







Abstract
条件图像生成是利用类标签信息生成多样化图像的任务。尽管许多条件生成对抗性网络(GAN)都显示出了逼真的结果,但这类方法将图像嵌入和相应标签嵌入(数据到类关系data-to-class relations)之间的成对关系视为条件损失conditioning losses。在这篇文章中,我们提出了ContraGAN,通过使用条件对比损失conditional contrastive loss来考虑同一批次中多个图像嵌入之间的关系(数据到数据的关系)以及数据到类的关系。ContraGAN的鉴别器鉴别给定样本的真实性,最小化一个对比目标来学习训练图像之间的关系。同时,生成器试图生成欺骗真实性且对比损失低的真实感图像。实验结果表明,ContraGAN在Tiny ImageNet和ImageNet数据集上的性能分别比现有模型提高了7.3%和7.7%。此外,我们还通过实验证明了ContraGAN有助于缓解判别器的过拟合。为了公平比较,我们使用PyTorch库重新实现了12个最先进的GANs。软件包在https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.有售
1 Introduction1 Introduction
生成对抗网络(GAN) 引入了一种现实数据生成的新范式。许多方法在un/conditional 图像生成任务中显示了令人印象深刻的改进。客观景观的非凸性[10,11,12]和梯度消失问题[3,11,13,14]的研究强调了对抗性动态的不稳定性。因此,许多方法都试图通过采用良好的目标[3,13,15]和正则化技术[4,7,16]来稳定训练过程。特别是,带有投影鉴别器[17]的光谱归一化[4]首次成功地生成了ImageNet数据集的图像[18]。SAGAN [5]表明,在生成器和鉴别器上都使用光谱归一化可以缓解GANs的训练不稳定性。BigGAN [6]通过扩大网络参数的数量和批量大小,极大地提高了生成图像的质量。
在这个旅程中,生成器和鉴别器的条件化类信息被证明是现实图像生成背后的秘密[17,19,20]。ACGAN [19]通过与鉴别器一起训练softmax分类器来验证这个方向。ProjGAN [17]利用具有概率模型假设的投影鉴别器。特别是ProjGAN显示了令人惊讶的图像合成结果,成为SNGAN [4]、SAGAN [7]、BigGAN [6]、CRGAN [7]和LOGAN [9]采用的基本模型。然而,带有投射判别器的GANs存在过拟合问题,这导致对抗性训练崩溃[21,9,22,23]。众所周知,当类的数量增加时,ACGAN是不稳定的[17,19]。
本文提出了一种新的条件生成对抗网络框架,即对比生成对抗网络Contrastive Generative Adversarial Networks (ContraGAN)。我们的方法是基于ACGAN和ProjGAN利用数据到类的关系作为条件损失。这种损失只考虑图像的嵌入和相应标签的嵌入之间的关系。相比之下,ContraGAN基于条件对比损失(2C损失)conditional contrastive loss (2C loss)来考虑同一批次中的数据到数据关系。当类标签相同时,ContraGAN将多个图像嵌入拉得更近,但否则会推得更远。通过这种方式,鉴别器不仅可以捕获数据到类,还可以捕获样本之间的数据到数据关系。
我们使用各种主干架构在CIFAR10 [24]、微型ImageNet [25]和ImageNet [18]数据集上进行图像生成实验,如DCGAN [2]、ResGAN [26、16]和配备了光谱归一化功能的BigGAN [6]。通过详尽的实验,我们验证了所提出的ContraGAN在微小的ImageNet和ImageNet数据集上分别比现有的模型提高了7.3%和7.7%,这是基于Frechet初始距离(FID) [27]。此外,ContraGAN在CIFAR10上给出了与art模型相当的结果(FID降低了1.3%)。由于ContraGAN可以从一个适当大小的批处理中学习到丰富的数据到数据关系,因此无需硬的负挖掘和正挖掘hard negative and positive mining就可以显著降低FID。此外,我们通过实验证明2C损失缓解了判别器的过拟合问题。在消融研究中,我们证明ContraGAN可以从使用数据增强的一致性正则化consistency regularization[7]中受益。
综上所述,我们的工作贡献如下:
- 我们提出了一种用于条件图像生成的新型对比生成对抗网络。ContraGAN基于一种新的条件对比损失(2C损失),它可以同时学习数据到类和数据到数据的关系。
- 我们通过实验证明ContraGAN在微小的ImageNet和ImageNet数据集上分别提高了7.3%和7.7%的最新结果。ContraGAN还有助于缓解判别器的过拟合问题。
- ContraGAN在没有数据增强的情况下显示了良好的结果,以实现一致性正则化。如果应用一致性正则化,ContraGAN可以给出优越的图像生成结果。
- 我们提供了12个最先进的GANs的实现,以便进行公平的比较。我们对CIFAR10数据集的现有技术的实现取得了比原始论文中报告的FID分数更好的性能。
2 Background
2.1 Generative Adversarial Networks
生成对抗网络(GAN) [1]是一种隐式生成模型,它使用生成器和鉴别器来合成现实图像。虽然鉴别器(D)应该区分给定图像是否合成,但生成器(G)试图通过从噪声向量生成逼真的图像来欺骗鉴别器。对抗性训练的目标如下:

其中preal(x)是真实的数据分布,pz(z)是预定义的先验分布,通常是多元高斯分布。由于生成器和鉴别器之间的动态是不稳定的,很难达到纳什均衡Nash equilibrium[28],所以有许多目标函数[3,13,15,29]和正则化技术[4,7,16,21]来帮助网络收敛到适当的均衡。
2.2 Conditional GANs
合成真实感图像的一种广泛使用的策略是利用类标签信息。这一类的早期方法是条件变分自动编码器(CVAE) [30]和条件生成对抗网络[31]。这些方法将潜在向量与标签连接起来,以处理生成图像的语义特征。自从DCGAN [2]展示了高分辨率图像生成以来,利用类标签信息的GANs已经显示出了先进的性能[6,7,9,8]。
条件GANs最常见的方法是向生成器和鉴别器中注入标签信息。ACGAN [19]在鉴别器中的卷积层顶部附加了一个辅助分类器来区分图像的类别。图1a显示了ACGAN的说明。ProjGAN [17]指出ACGAN很可能生成容易分类的图像,生成的图像并不多样。ProjGAN提出了一个投影鉴别器来解决这些问题(参见图1b)。但是,这些方法在培训阶段没有明确考虑数据到数据的关系。此外,Wu等人最近的研究[9]发现带有投影判别器的BigGAN[6]仍然存在判别器过拟合和训练崩溃问题。
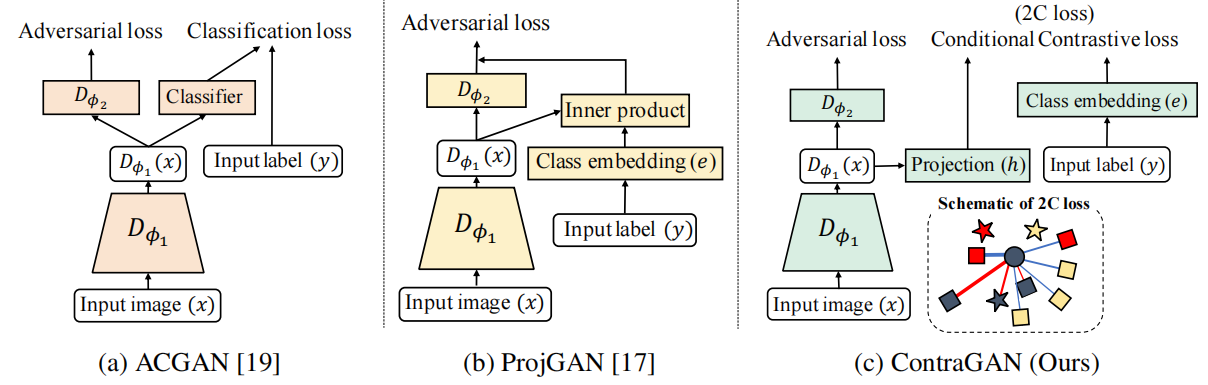
图1:三个条件GAN的鉴别器示意图。(a)ACGAN[19]有一个辅助分类器auxiliary classififier来指导生成器合成可分类良好well-classifiable的图像。(b)ProjGAN[17]通过添加嵌入式图像的内积和相应的类嵌入来改进ACGAN。©我们的方法扩展了ACGAN和ProjGAN的条件对比损失(2C loss)。ContraGAN考虑同一批中的多个正对和负对。ContraGAN也利用2C损失来更新生成器。
3 Method
我们首先分析ACGAN和ProjGAN的 条件函数 conditioning functions 可以被解释为 基于对的损失 pair-based losses,它们只看训练示例的 数据到类关系 data-to-class (Sec.3.1)。然后,为了同时考虑 数据到数据 和 数据到类的关系 data-to-data and data-to-class ,我们设计了一种新的条件对比损失(2C损失)(Sec3.2) conditional contrastive loss (2C loss)。最后,我们提出了用于条件图像生成的对比生成对抗网络 Contrastive Generative Adversarial Networks (ContraGAN)(Sec3.3)。
3.1 Conditional GANs and Data-to-Class Relations
ACGAN中的鉴别器的目标是对 给定图像的类别和样本的真实性进行分类。使用数据到类的关系,即关于给定数据属于哪个类的信息,生成器试图生成可以 欺骗真实性deceive the authenticity 的虚假图像,并被归类为目标标签。由于ACGAN使用交叉熵损失来对图像的类进行分类,我们可以将ACGAN的条件损失视为一种基于对的损失,只能考虑数据对类的关系(见图2d)。ProjGAN试图最大化真实图像嵌入和相应的目标嵌入之间的内部积值inner-product values,同时在图像是假时 最小化内部积值。由于ProjGAN的鉴别器根据真实性和类信息 推拉pushes and pulls 图像的嵌入,我们可以将ProjGAN的条件目标视为一种基于对的损失,考虑数据对类的关系(见图2e)。与ACGAN研究固定的单热向量和样本之间的关系fixed one-hot vector and a sample不同,ProjGAN可以使用 可学习的类嵌入learnable class embedding,即代理Proxy 来考虑更灵活的关系。
3.2 Conditional Contrastive Loss
为了利用数据间data-to-data的关系,我们可以采用自监督[34]学习self-supervised learning或度量学习metric learning[32,35,36,37,38,39]中使用的损失函数。换句话说,我们的方法是在鉴别器和生成器中添加一个度量学习或自我监督学习目标,以显式地控制嵌入图像特征(depending on the labels) 之间的距离。对比损失contrastive loss[35]、三联体损失triplet loss[32]、四联体丢失quadruplet loss[36]和n对损失 N-pair loss[37] 可能是很好的候选者。然而,众所周知,1)挖掘信息丰富的三联体或四联体需要更高的训练复杂性,2)较差的元组会使训练时间更长。虽然基于代理的损失proxy-based losses[33,38,39]使用可训练的类嵌入向量缓解了挖掘的复杂性,但这种损失并没有明确地考虑到数据-数据关系[40]。

图2:图表说明了度量学习损失(a、b、c)和条件GANs(d、e、f)。颜色表示类标签,形状表示角色。(正方形)图像的嵌入。(菱形)一个增强的图像的嵌入。(圆圈)参考图像嵌入reference image embedding。每个损失都应用于参考文献。(星形)类标签的嵌入。(三角形)类标签的一个热编码one-hot encoding of a class label。红线和蓝线的厚度分别表示拉力和推力的强度。ProjGAN的损失函数允许 引用reference 和 相应的类嵌入 在引用是真实的时 彼此接近,反之 推得很远。与ACGAN和ProjGAN相比,2C损失可以同时考虑训练示例之间的 数据对类data-to-class 和 数据对数据data-to-data 的关系
。
NT-Xent损失
在引入提出的2C损失之前,我们引入NT-Xent损失[34]来更好地表达我们的想法。
然而,Eq(6)需要适当的数据增强,并且不能考虑训练示例中的 数据-类的关系。为了解决这些问题,我们建议使用类标签的嵌入embeddings of class labels,而不是使用数据增强。


3.3 Contrastive Generative Adversarial Networks
对于提出的2C损失,我们描述了被称为ContraGAN的框架,并引入了训练程序。与典型的GANs训练程序一样,ContraGAN有一个鉴别器训练步骤step和一个生成器训练步骤来计算对抗性损失。在此基础上,ContraGAN还使用一组真实或假图像计算2C损失。算法1显示了该contragan的训练过程。一个值得注意的方面是,在鉴别器训练步骤中使用m个真实图像和在生成器训练步骤中使用m个生成图像来计算2C损失。
通过这种方式,鉴别器通过最小化来自同一个类的真实图像嵌入之间的距离来更新自己,反之最大化它。通过强制嵌入通过2C损失进行相关联By forcing the embeddings to relate via 2C loss,鉴别器可以学习真实图像的细粒度表示。类似地,生成器利用鉴别器的知识,如类内特征intra-class characteristics和真实图像的高阶表示higher-order representations,来生成更真实的图像。
3.4 Differences between 2C Loss and NT-Xent Loss
NT-Xentloss[34]专门用于无监督学习。将增广图像作为正样本,考虑原始图像与增广图像之间的data-to-data关系。另一方面,2C损失利用了对标签信息的弱监督weak supervision of label information。因此,与2C损失相比,NT-Xent很难收集同一个类的图像嵌入,因为没有来自标签信息的监督。此外,NT-Xent损失需要额外的数据增强和额外的正向和向后传播additional forward and backward propagations,这导致的训练时间比2C损失的模型长几倍。
4 Experiments
4.1 Datasets and Evaluation Metric
我们使用CIFAR10[24]、Tiny ImageNet[25]和ImageNet[18]数据集进行条件图像生成实验,以将该方法与其他方法进行比较。
CIFAR10[24]
是一个在许多图像生成工作[4,6,7,8,9,17,19]中广泛使用的基准数据集benchmark dataset,它包含32×32像素的彩色图像,为10个不同的类别。该数据集总共由6万张图像组成。它被分为5万张图像用于训练和1万张图像用于测试。
Tiny ImageNet[25]
总共提供了12万张彩色图像。图像大小为64×64像素,数据集由200个类别组成。每个类别有600张图像,分别分为500张、50张和50个样本,用于训练、验证和测试。Tiny ImageNet每个类的图像数量比CIFAR10少10×的图像数量,但它提供了比CIFAR10多20×的类数量。与CIFAR10相比,选择Tiny ImageNet来测试一个更具挑战性的场景——每个类的图像数量并不多,但网络需要学习更多的类别。
ImageNet[18]
分别提供1281167和50,000张彩色图像用于训练和验证,数据集由1000个类别组成。我们使用一个长度与图像的短边相同的方框来裁剪每幅图像。裁剪后的图像被重新缩放到128×128像素。
Frechet Inception Distance (FID)
是本文所有实验中使用的一种评价度量。由Heusel等人提出的FID。[42]使用 Inception-V3 network[44]计算从真实图像中获得的特征与生成的图像之间的Wasserstein-2 distance[43]。由于FID是两个分布之间的距离,较低的FID表明更好的结果。
4.2 Software
有各种各样的方法可以报告很强的FID分数,但并不容易重现结果,因为没有明确说明培训的详细规范或测量结果的方法。例如,FID可能会根据参考图像的选择而有所不同(可以使用训练、验证或测试数据集)。此外,之前工作的FID评分并不一致,这取决于 TensorFlow versions[45]。因此,我们重新实现了12个最先进的GANs [2,13,15,3,16,10,19,17,4,5,6,7]来验证相同条件下提出的ContraGAN。我们的实施仔细地遵循了之前工作中的主要概念和可用的规范。实验结果表明,对于使用CIFAR10数据集的实验,我们的实现结果优于原始论文[4,6]中的数字。我们希望我们的实现将减轻比较各种GAN pipelines 的压力。
4.3 Experimental Setup
为了进行可靠的评估,所有使用CIFAR10和TinyImageNet数据集的实验都使用不同的随机种子进行了三次,我们报告了fid的均值和标准差。使用ImageNet的实验执行了一次,我们报告了在训练期间的最佳表现。我们使用CIFAR10的测试图像和相同数量的生成图像来计算FID。对于使用TinyImageNet和ImageNet的实验,我们使用具有相同数量生成图像的验证集。本文中报道的所有FID值都是使用PyTorch FID实现[46]计算的。
由于光谱归一化[4]已经成为现代GAN训练中的一个重要元素,我们使用铰链损失hinge loss[15],并在实验中使用的所有架构中应用光谱归一化。我们采用了论文中使用的现代架构:DCGAN[2,4]、ResGAN[26,16]和BigGAN[6],所有关于这些架构的细节都在补充中描述。
由于ACGAN生成器中使用的条件策略与ProjGAN不同,因此我们在所有实验中都采用了生成器的条件方法来进行公平的比较。我们使用条件着色变换conditional coloring transform[47,48,17],这是原始ProjGAN所采用的方法。
在进行主要实验之前,我们根据公式8中投影层 h 的类型来研究性能的变化和批量大小。虽然陈等人[34]报道对比学习可以受益于高维投影和更大的批量,我们发现CIFAR10批量为64和Tiny ImageNet为1024的线性投影表现最好。对于投影层的维数,我们选择CIFAR 512,小ImageNet 768,ImageNet实验1024。我们做一个网格搜索grid search,以找到 式8 中使用的合适的温度temperature(t),实验发现,温度为1.0的效果最好。在我们的实验中使用的详细的超参数设置将在补充部分中描述。
4.4 Evaluation Results
略
4.5 Training Stability of ContraGAN
本节比较了ContraGAN和ProjGAN对微型ImageNet[17]的训练稳定性。我们计算了在训练数据集和验证数据集上的真实性精度之间的差异。这是因为训练和验证性能之间的差异是测量过拟合的一个很好的估计量。此外,正如布洛克等人一样。在他的工作[6]中提到,网络参数的最大奇异值(谱范数)的突然变化可以表明对抗性训练的崩溃。根据这一想法,我们绘制了鉴别器参数的谱范数的趋势,以监测训练崩溃。
如图3第一列所示,ProjGAN显示精度差异迅速增加,ProjGAN比ContraGAN更早到达崩溃点。此外,光谱分析结果表明,ContraGAN对训练崩溃具有更强的鲁棒性。我们推测ContraGAN更难达到不良数据状态undesirable status,因为ContraGAN共同考虑数据到数据和数据到标签的关系。我们发现,在 验证数据集 上的准确性的提高可以表明训练崩溃。
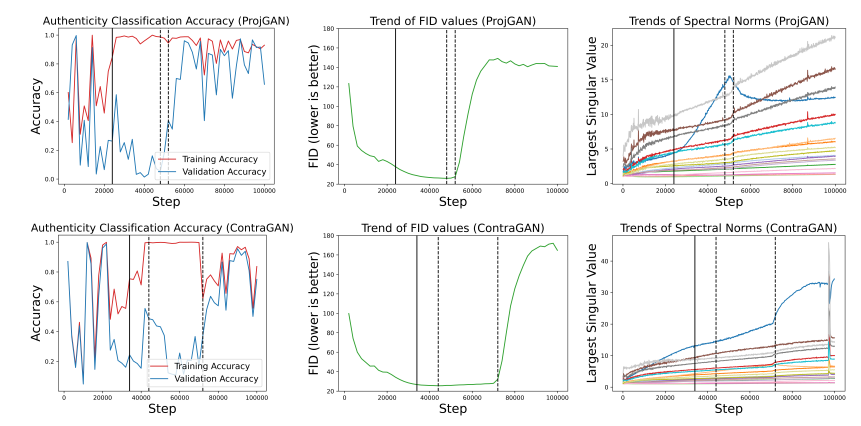
图3:训练和验证数据集上的真实分类精度(左),FID值的趋势(中间),以及鉴别器卷积参数的最大奇异值的趋势(右)。为了指定训练精度和验证精度之间的差异大于0.5的起点,我们使用了一条实黑线。第一条和第二条黑色虚线分别表示何时表现最好和训练何时崩溃。
4.6 Ablation Study
略
5 Conclusion
在本文中,我们提出了一个条件对比损失(2C损失),并提出了新的用于条件图像生成的对比生成对抗网络(ContraGAN)。与之前的条件损失不同,提出的2C损失不仅考虑了 data-to-class,还考虑了训练示例之间的 data-to-data relations。在相同的条件下,我们证明了ContraGAN在Tiny ImageNet和ImageNet数据集上优于最先进的条件GAN。同时,我们还发现ContraGAN有助于缓解鉴别器的过拟合问题和训练崩溃。作为未来的工作,我们希望从理论和实验上分析 对抗性训练 是如何随着 验证数据集上 的 真实性准确性的提高 而崩溃的。此外,我们认为 探索先进的正则化技术 [8,9,22,23]对于进一步了解ContraGAN是必要的。
Broader Impact
我们提出了一种新的条件图像生成模型,可以合成更真实和多样化的图像。我们的工作可以有助于图像到图像的翻译[50,51],生成真实的人脸[52,53,54],或任何利用对抗性训练的任务。
由于条件GANs可以扩展到各种图像处理应用,并可以学习高维数据集的表示,科学家可以提高天文图像[55,56]的质量,设计复杂的结构材料[57],并有效地寻找化学空间来开发材料[58]。我们可以用条件GANs做很多有益的任务,但是我们应该担心条件GANs可以用于深度假技术[59]。现代生成模型可以合成真实的图像,因此很难区分真实的和假的。这可能会引发性骚扰[60],假新闻[61],甚至是人脸识别系统[62]的安全问题。
为了避免不当使用条件gan,我们需要意识到生成模型的优缺点。此外,研究生成的样本[63]的一般特征以及如何区分假图像和未知生成模型[64,65,66]将是很好的。














 3661
3661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









