







Github链接:https://github.com/tangyudi/Ai-learn (包括全部课程资料与学习路线图)
该课程共16章所有代码和数据集
目录
1-basic-operate
1.basic.py
# author : 'wangzhong';
# date: 03/12/2020 20:41
import torch
import numpy as np
# 创建一个未初始化矩阵
empty = torch.empty(5, 3)
# 创建一个空矩阵
zeros = torch.zeros(5, 4)
# 创建指定范围整形矩阵
randInt = torch.randint(1, 10, (5, 4))
# 创建随机矩阵
rand = torch.rand(5, 4)
# 转为tensor类型
x = torch.tensor([5, 5, 3])
# 转为1矩阵
x = x.new_ones((5, 3))
# 生成形状形同,均值为0,方差为1的标准正态分布随机数
x = torch.randn_like(x, dtype=torch.float)
print(x)
# 查看维度
print(x.size())
# 同numpy的reshape
print(x.view(15))
# 从torch转为numpy,内存共享,改变一个,另一个同时改变
a = torch.ones(5, 3)
b = a.numpy()
b[0][0] = 100
print(a)
# 从numpy转为torch,内存共享,改变一个,另一个同时改变
a = np.ones((5, 3))
b = torch.from_numpy(a)
b[0][0] = 100
print(a)
# 查看gpu版是否安装成功
print(torch.cuda.is_available())
2.autoGrad.py
# date: 09/12/2020 02:41
import torch
# 简单的torch自动求导尝试,这里的t = x + b
x = torch.randn(3, 4, requires_grad=True)
# print(x)
b = torch.randn(3, 4, requires_grad=True)
# print(b)
t = x + b
# print(t)
y = t.sum()
# print(y)
y.backward()
# print(x.grad)
x = torch.rand(1)
b = torch.rand(1, requires_grad=True)
w = torch.rand(1, requires_grad=True)
y = w * x
z = y + b
w2 = torch.rand(1, requires_grad=True)
b2 = torch.rand(1, requires_grad=True)
res = w2*z + b2
# 判断是否是leaf节点,显然这个最简单的公式里,y不是
print(y.is_leaf)
# retain_graph=True:保留z-y-x的计算图
z.backward(retain_graph=True)
print(w.grad)
# 非叶子节点,grad直接省略
# 如果需要非叶子节点的grad,需要这个函数
y.retain_grad()
print(y.grad)
res.backward()
print(w2.grad)
print(b2.grad)
print(w.grad)
3.lineardemo.py
# date: 13/12/2020 13:56
"""
基于pytorch的线性回归demo练习
"""
import numpy as np
import torch
import torch.nn as nn
# 继承nn.module,实现前向传播,线性回归即是全连接层
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
if __name__ == '__main__':
# torch里要求必须是float
x = np.arange(1, 12, dtype=np.float32).reshape(-1, 1)
y = 2 * x + 1
model = LinearRegressionModel(1, 1)
# 可以通过to()或者cuda()使用GPU进行模型的训练,需要将模型和数据都转换到GPU上,也可以指定具体的GPU,如.cuda(1)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
epochs = 1000
learning_rate = 0.01
# 优化迭代
optimizer = torch.optim.SGD(model.parameters(), learning_rate)
# 评估指标,均方误差
criterion = nn.MSELoss()
for epoch in range(epochs):
inputs = torch.from_numpy(x).to(device)
labels = torch.from_numpy(y).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
# 进行权重更新
optimizer.step()
if epoch % 50 == 0:
print("epoch:", epoch, "loss:", loss.item())
predict = model(torch.from_numpy(x).requires_grad_()).data.numpy()
# torch.save(model.state_dict(), "model.pk1")
result = model.load_state_dict(torch.load("model.pk1"))
model.pkl地址: https://github.com/PlayPurEo/ML-and-DL/blob/master/pytorch/1-basic-operate/model.pk1
4.tensorPractice.py
# author : 'wangzhong';
# date: 22/12/2020 20:06
"""
练习下常见的tensor格式
"""
from torch import tensor
# 这是一个标量,就是一个值
scalar = tensor(55)
# 正常的数值操作
scalar *= 2
# 0维
print(scalar.dim())
# 可以查看矩阵的维度,如torch.size([2,3,4])代表三维,且每个维度的大小分别是2,3,4
print(scalar.shape)
# -------------------------------------------
v = tensor([1, 2, 3])
# 一维向量
print(v.dim())
# size方法和属性shape一样
print(v.size())
# -------------------------------------------
matrix = tensor([[1, 2, 3], [4, 5, 6]])
# 二维向量
print(matrix.dim())
print(matrix.shape)
# 矩阵乘法
print(matrix.matmul(matrix.T))
# (2,3) * (3,) = (2,)
print(matrix.matmul(tensor([1, 2, 3])))
# (2,) * (2, 3) = (3,)
print(tensor([1, 2]).matmul(matrix))
# 对应位置相乘
print(matrix * matrix)
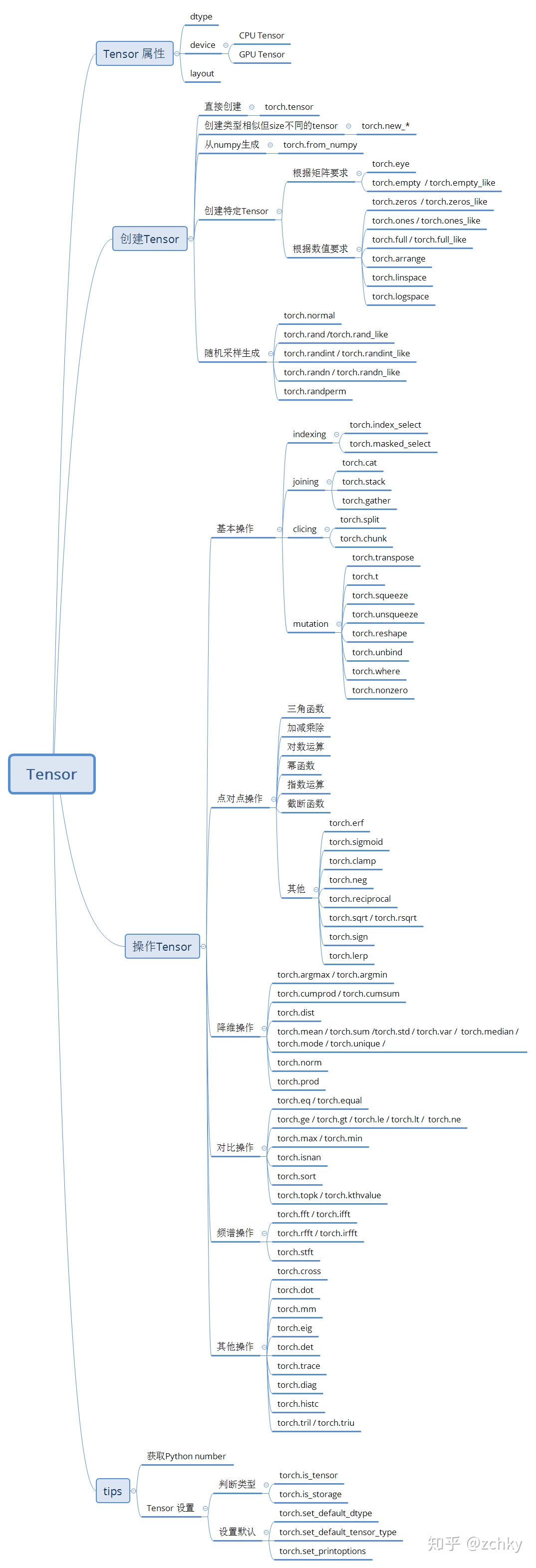
2-regression-practice
temperature.py
# date: 04/01/2021 15:56
"""
pytorch基础气温预测项目
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from sklearn import preprocessing
import datetime
# 通过python console查看维度
features = pd.read_csv('temps.csv')
# 看看数据长什么样子
# print(features.head())
# 对字符串特征做独热编码
features = pd.get_dummies(features)
print(features.head())
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features = features.drop('actual', axis=1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 特征标准化处理
input_features = preprocessing.StandardScaler().fit_transform(features)
# 转为tensor格式
x = torch.tensor(input_features, dtype=torch.float)
y = torch.tensor(labels, dtype=torch.float)
# 权重参数初始化,一层hidden layer
weights = torch.randn((14, 128), dtype=torch.float, requires_grad=True)
biases = torch.randn(128, dtype=torch.float, requires_grad=True)
weights2 = torch.randn((128, 1), dtype=torch.float, requires_grad=True)
biases2 = torch.randn(1, dtype=torch.float, requires_grad=True)
learning_rate = 0.001
losses = []
# 简单的手写梯度下降
# for i in range(1000):
# # 计算隐层,mm为矩阵乘法
# hidden = x.mm(weights) + biases
# # 加入激活函数
# hidden = torch.relu(hidden)
# # 预测结果
# predictions = hidden.mm(weights2) + biases2
# # 代价函数为均方误差
# loss = torch.mean((predictions - y) ** 2)
# losses.append(loss.data.numpy())
#
# # 打印损失值
# if i % 100 == 0:
# print('loss:', loss)
# # 返向传播计算
# loss.backward()
#
# # 更新参数
# weights.data.add_(- learning_rate * weights.grad.data)
# biases.data.add_(- learning_rate * biases.grad.data)
# weights2.data.add_(- learning_rate * weights2.grad.data)
# biases2.data.add_(- learning_rate * biases2.grad.data)
#
# # 每次迭代都得记得清空
# weights.grad.data.zero_()
# biases.grad.data.zero_()
# weights2.grad.data.zero_()
# biases2.grad.data.zero_()
# 更简单的,全部用torch内置函数完成的模型训练
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr=0.001)
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype=torch.float, requires_grad=True)
yy = torch.tensor(labels[start:end], dtype=torch.float, requires_grad=True)
prediction = my_nn(xx)
# 降为一维,否则loss会告警
prediction = prediction.squeeze(-1)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
predict = my_nn(x).data.numpy()
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data={'date': dates, 'actual': labels})
predictions_data = pd.DataFrame(data={'date': dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label='actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label='prediction')
plt.xticks(rotation='60')
plt.legend()
# 图名
plt.xlabel('Date')
plt.ylabel('Maximum Temperature (F)')
plt.title('Actual and Predicted Values')
plt.show()
懒得复制了。。。。















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









