







概率密度


最大似然估计原理

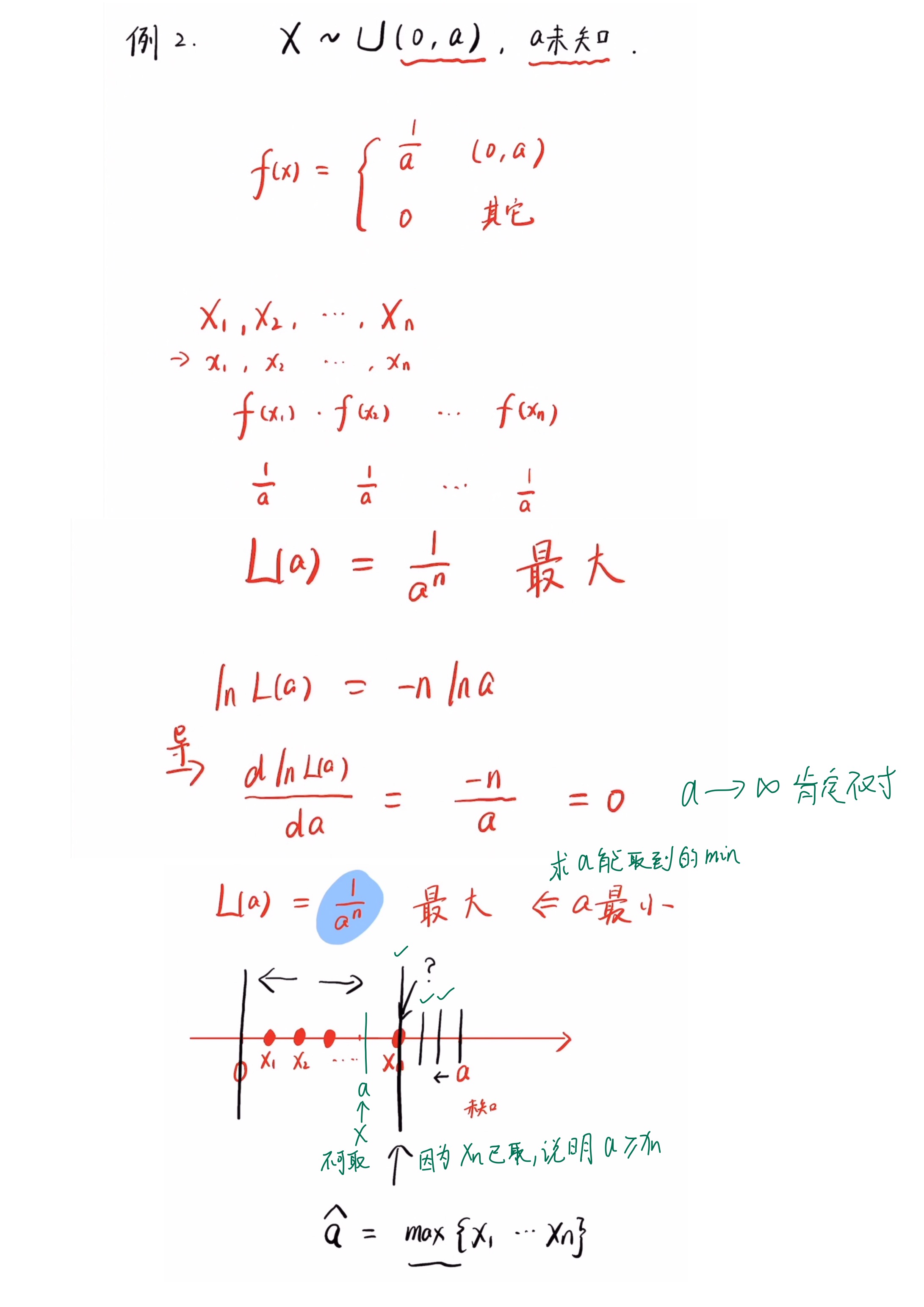
最大似然估计里的似然函数能理解成取到这组样本的概率(每一个样本X1、X2、X3、…Xn同时发生)【似然函数之所以是概率密度的连乘,其实就是每一个样本同时发生(抽到这组样本)的意思】,然后最大似然估计的基本思想就是既然能抽出这组样本,就默认为这组样本被抽到的概率是最大的(或试验条件下对这组样本的出现是最有利的),因此应该构造一个似然函数,表示X1,X2,X3,…Xn同时发生的概率,最终使得抽出的这组样本被抽到的概率(似然函数值)达到最大值的参数就是这个参数的最大似然估计值

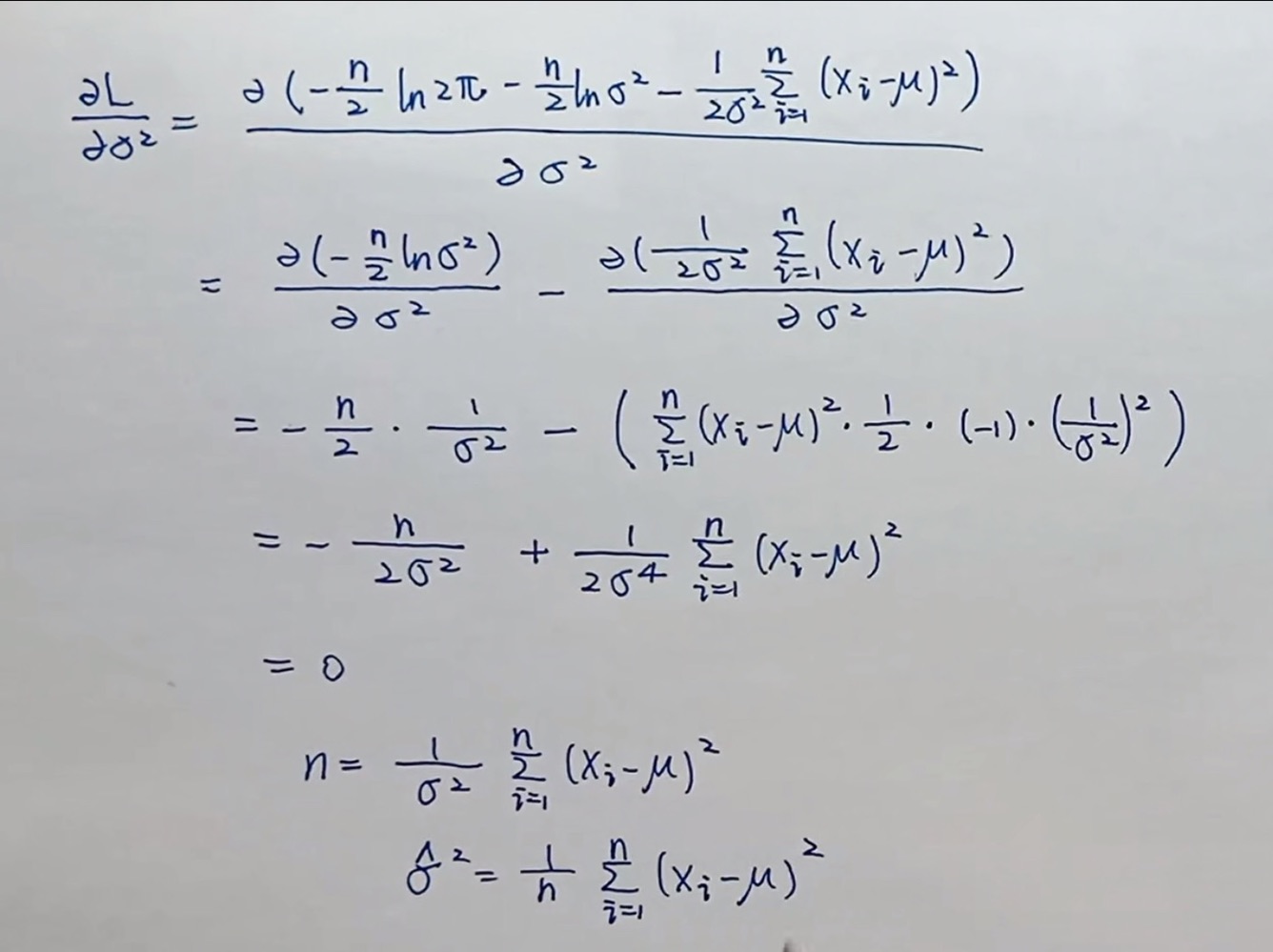
参数估计三性质 总结:
1.估计量:用于样本推断总体,估计量是一个随机变量,服从一个分布
2.无偏:随机变量(估计量)的期望(均值)等于总体的均值
3.有效性:随机变量(估计量)围绕总体均值的波动(方差)小
4.一致性:随着样本容量增加(即估计量具体的估计值增加),估计量的方差逐渐减小,依概率收敛到总体均值(PS:在我看来是随着样本的增多,信息量增多,不确定性下降,导致能从样本得到对总体更多的认识)
5.一致性对于估计量最重要:随着样本量增加,估计量会收敛致总体的数字特征,这样可以用样本推断总体(扰动项与同期解释变量不相关(无内生性)是OLS为一致估计量的最重要条件)
参考:https://www.zhihu.com/question/22983179/answer/404391738
矩阵求逆



特征值 特征向量



















 38万+
38万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









