






-
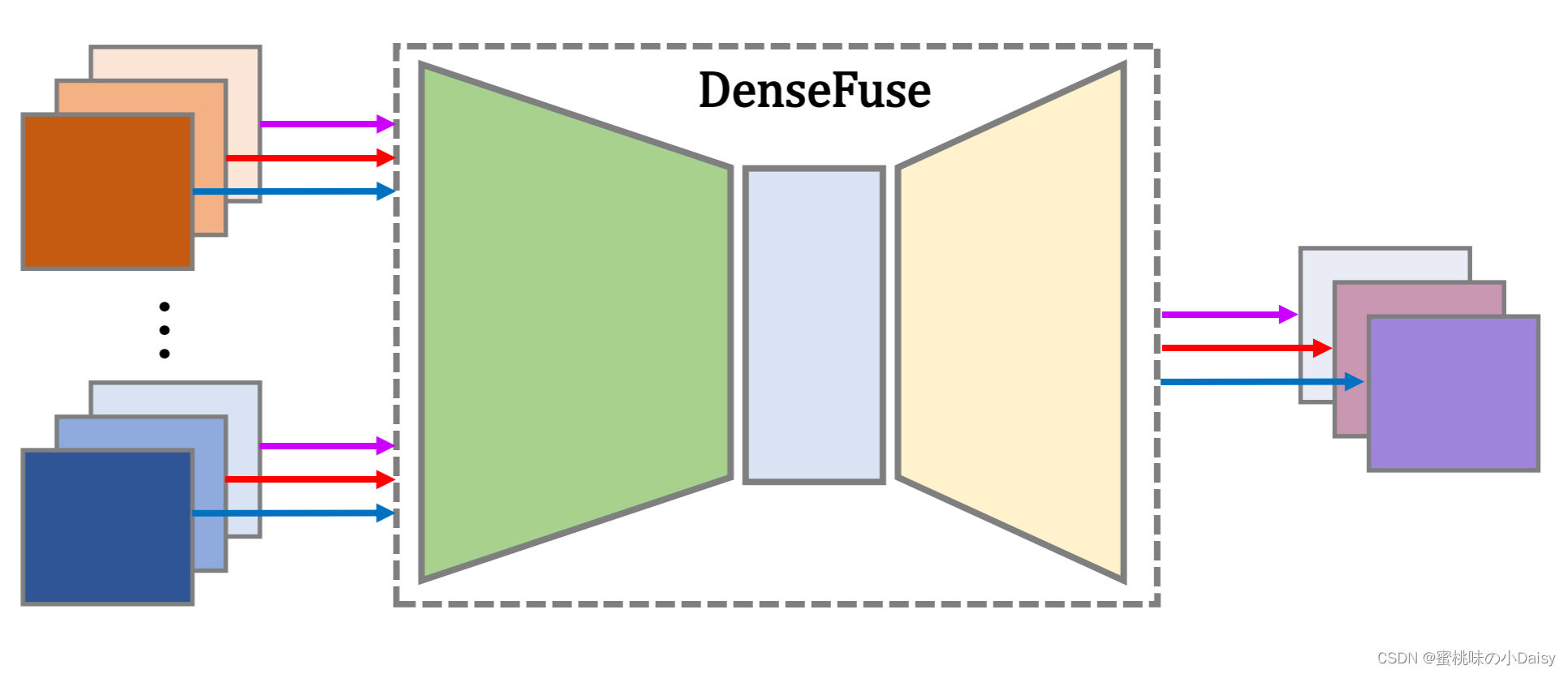
DenseFuse
-
论文来源
-
IEEE Transactions on Image Processing
-
计算机科学1区
-
影响因子11.041
-
论文网址:https://ieeexplore.ieee.org/document/8580578
-
-
-
-
-
摘 要
-
提出了一种用于红外和可见光图像融合问题的新型深度学习架构。与传统的卷积网络相比,使用编码网络与卷积层,融合层和密集块相结合,其中每层的输出都连接到其他层。在编码过程中,我们尝试使用这种架构来从源图像中提取更多有用的特征,并设计了两个融合层(融合策略)来融合这些特征。最后,解码器对融合后的图像进行重构。
-
简单来说,就是使用编码网络(密集Net)进行特征提取,再进行两个策略进行融合,最后经过解码器重构图像。
-
-
-
引 言和相关工作
-
就是在说红外与可见光图像融合的意义、应用。还有常用的方法等等。
-
论文提出来一个问题:在这之前基于CNN的融合方法中,只有最后一层的结果被用作图像特征,这种操作会丢失许多有用的信息,很多信息是由中间层获得的。
-
为了解决这个问题,提出了一种新的深度学习架构,该架构由编码网络和解码网络构成。利用编码网络提取图像特征,通过解码网络得到融合图像。编码网络由卷积层和密集块构成,其中每层的输出用作下一层的输入。因此,编码网络中每一层的结果都被用来构建特征映射。最后,融合后的图像将被重建的融合策略和解码网络,其中包括四个CNN层。
-
论文将密集块纳入编码网络,这就是提出的名称的起源:Densefuse。通过这种操作,我们的网络可以从中间层保留更多有用的信息,并且易于训练。
-
-
方 法
-
在融合框架中,彩色图像(RGB)的融合策略与灰度图像相同,因此在论文中,暂时只考虑灰度图像的融合任务。彩色图像的融合结果如第4-D节所示。
-
输入的红外图像和可见光图像(灰度图像)被表示为I1,···,Ik,并且k ≥ 2。注意,输入图像是预先配准的。并且索引(1,···,k)与输入图像的类型无关,这意味着Ii(i = 1,···,k)可以被视为红外或可见光图像。网络架构有三个部分:编码器,融合层和解码器。
-
如图1所示,编码器包含两个部分(C1和DenseBlock),用于提取深度特征。第一层(C1)包含3 × 3卷积核以提取粗糙特征,密集块(DenseBlock)包含三个卷积层(每层的输出级联为下一层的输入),其中也包含3 × 3卷积核。在我们的网络中,反射模式用于填充输入图像。对于编码网络中的每个卷积层,特征映射的输入通道数为16。编码器的结构有两个优点。首先,卷积运算的卷积核大小和步长分别为3×3和1。使用此策略,输入图像可以是任何大小。其次,密集块结构可以在编码网络中尽可能多地保留深度特征,并且这种操作可以确保所有的显著特征都用于融合策略。

-
我们在融合层中选择了不同的融合策略,这些将在第三节B中介绍。解码器包含四个卷积层(3×3卷积核)。融合层的输出将作为解码器的输入。我们使用这种简单而有效的架构来重建最终的融合图像。
-
看到这里,什么是密集连接网络呢?于是我查了一下资料。截了两张图放在下面简单介绍一下,有兴趣了解的同学可以去这位博主那里看看。DenseNet——密集连接的卷积神经网络_密集连接卷积神经网络-CSDN博客
-
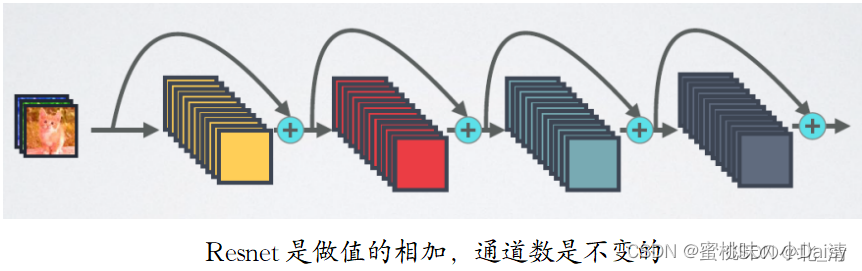 残差网络ResNet(2015ImageNet的分类任务上第一名)
残差网络ResNet(2015ImageNet的分类任务上第一名) -
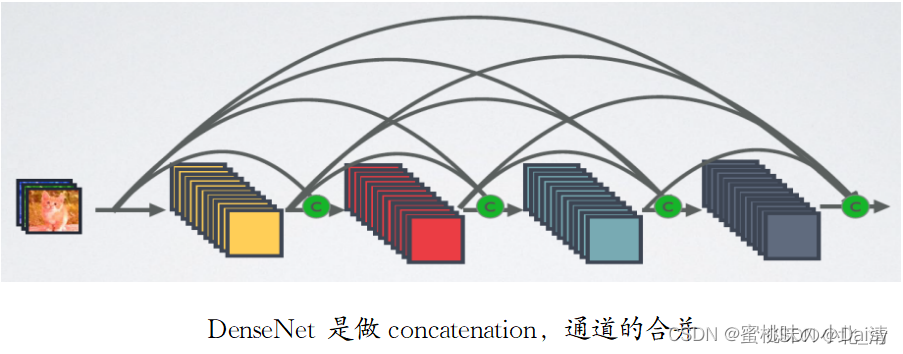 密集连接网络DenseNet(斩获了CVPR2017最佳论文奖)
密集连接网络DenseNet(斩获了CVPR2017最佳论文奖)
-
-
-
-
-
网络框架
-
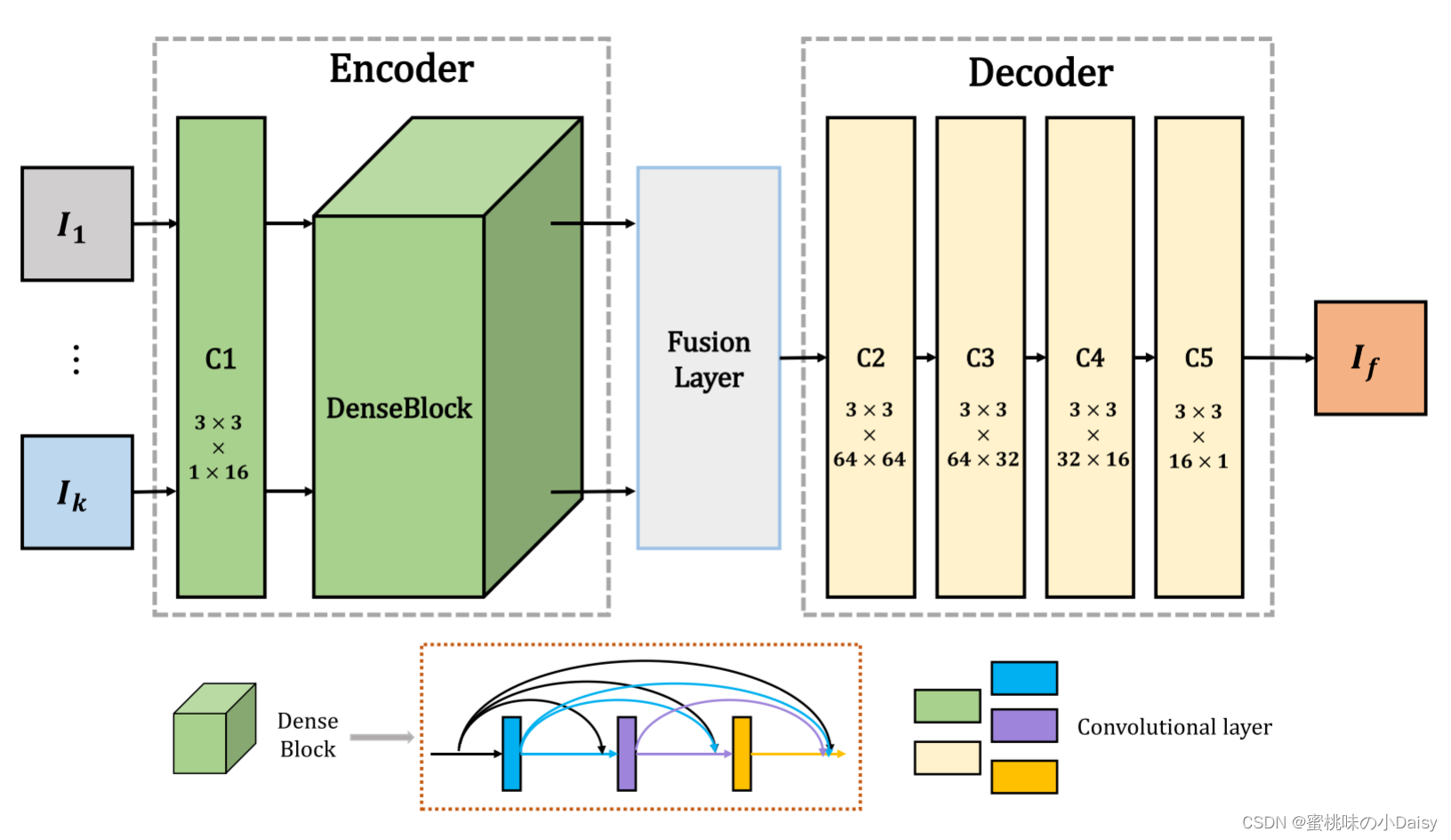 图 1 所提出的方法的架构
图 1 所提出的方法的架构-
训练
-
在训练阶段,只考虑编码器和解码器网络,试图训练编码器和解码器网络来重建输入图像。在编码器和解码器权重值固定后,采用自适应融合策略对编码器获取的深度特征进行融合。我们在训练阶段的网络工作的详细框架如图2所示,我们的网络架构如表I所示。
-
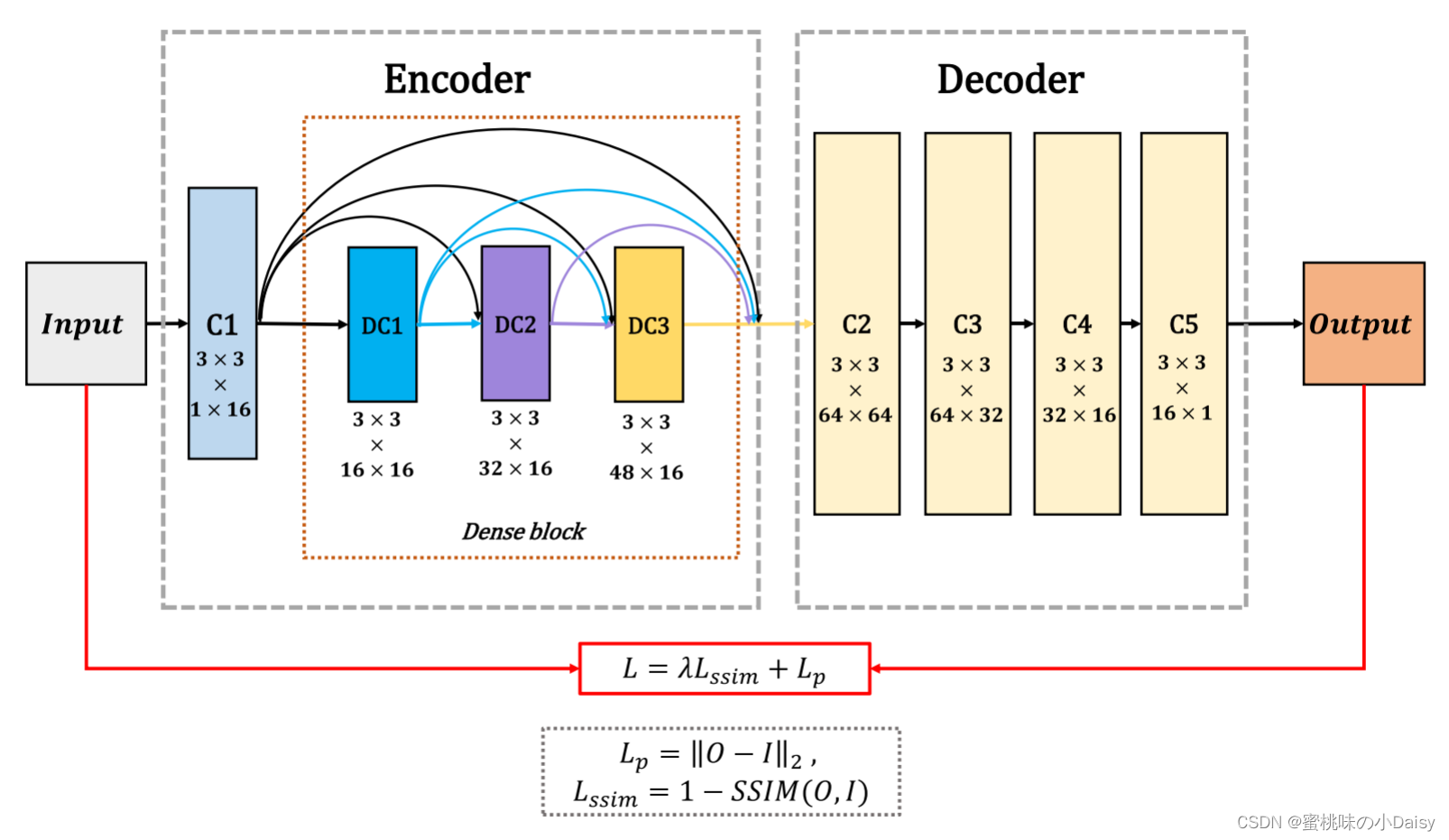 图2 培训过程的框架
图2 培训过程的框架-
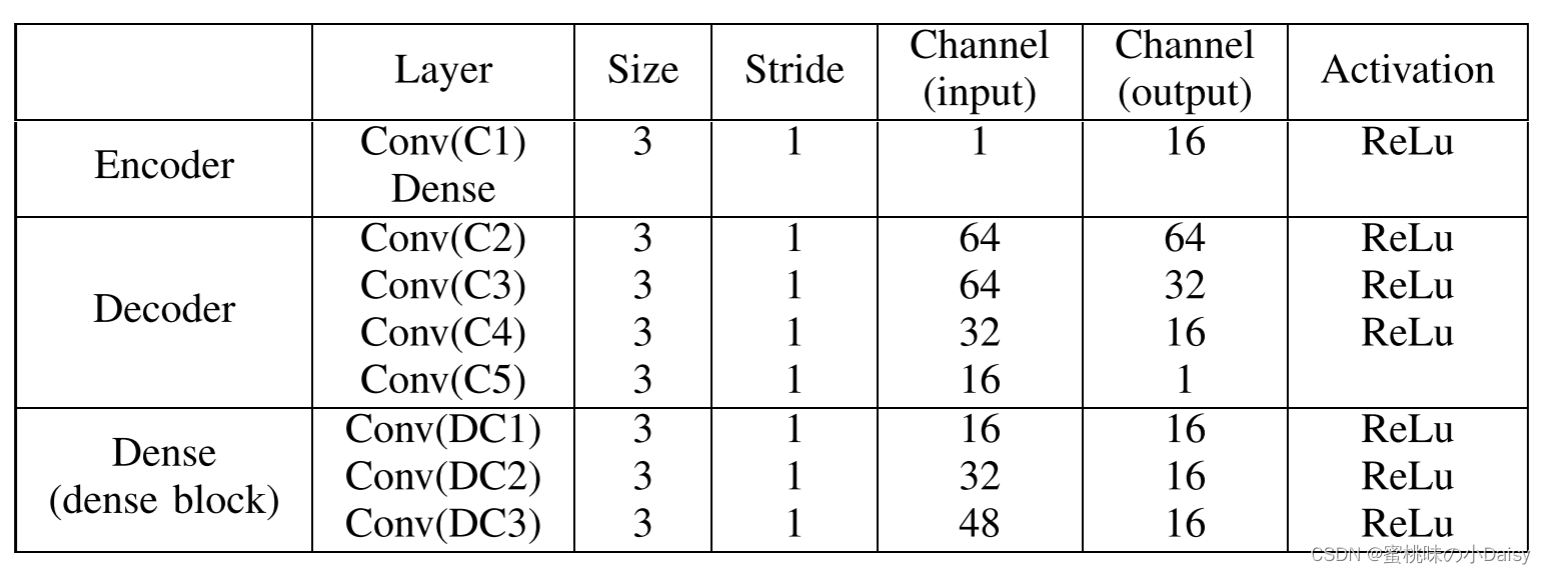
这种训练策略的明显优点是,我们可以为特定的融合任务设计合适的融合层。同时也为融合层的进一步发展留下了更大的空间。在图2和表I中,C1是编码器网络中的卷积层,包含3×3滤波器。DC1、DC2和DC3是密集块中的卷积层,并且每层的输出通过级联操作连接到每隔一层。解码器由C2、C3、C4和C5组成,它们将用于重建输入图像。
-
表一:培训过程的结构Conv表示卷积块(卷积层+激活); Dense表示密集块。
-
训练阶段的目标是训练一个具有较好特征提取和重构能力的自编码器网络(编码器、解码器)。由于红外和可见光图像的训练数据不足,我们使用MS-COCO [18]的灰度图像来训练我们的模型。在我们的训练阶段,我们使用可见光图像来训练编码器和解码器的权重。我们使用MS-COCO [18]作为输入图像来训练我们的网络,其中包含80000张图像,所有这些图像都被调整为256 × 256并转换为灰度图像。学习率设定为1 × 10^−4。块大小和epoch分别为2和4。用NVIDIA GTX 1080Ti GPU实现的。Tensorflow被用作网络架构的后端。培训阶段的分析将在第IV-A节中介绍。
-
-
-
-
融合层(融合策略)
-
我们选择了两种融合策略(加法策略和L1范数策略)对编码器得到的显著特征图进行联合融合。
-
1.相加策略
-
加法策略:加法融合策略,就像[15,查了一下是DeepFuse]中的融合策略一样。策略流程如图3所示。如图1所示,一旦编码器和解码器网络被固定,在测试阶段,两个输入图像分别被馈送到编码器。 在我们的网络中,m ∈{1,2,···,M},M = 64表示特征映射的数量。k ≥ 2表示从输入图像获得的特征图的索引。
-
其中φmi(i = 1,···,k)表示由编码器从输入图像获得的特征图,fm表示融合的特征图。加法策略由公式4表示,其中(x,y)表示特征图和融合特征图中的对应位置。然后将fm作为解码器的输入,解码器重构出最终的融合图像。
-
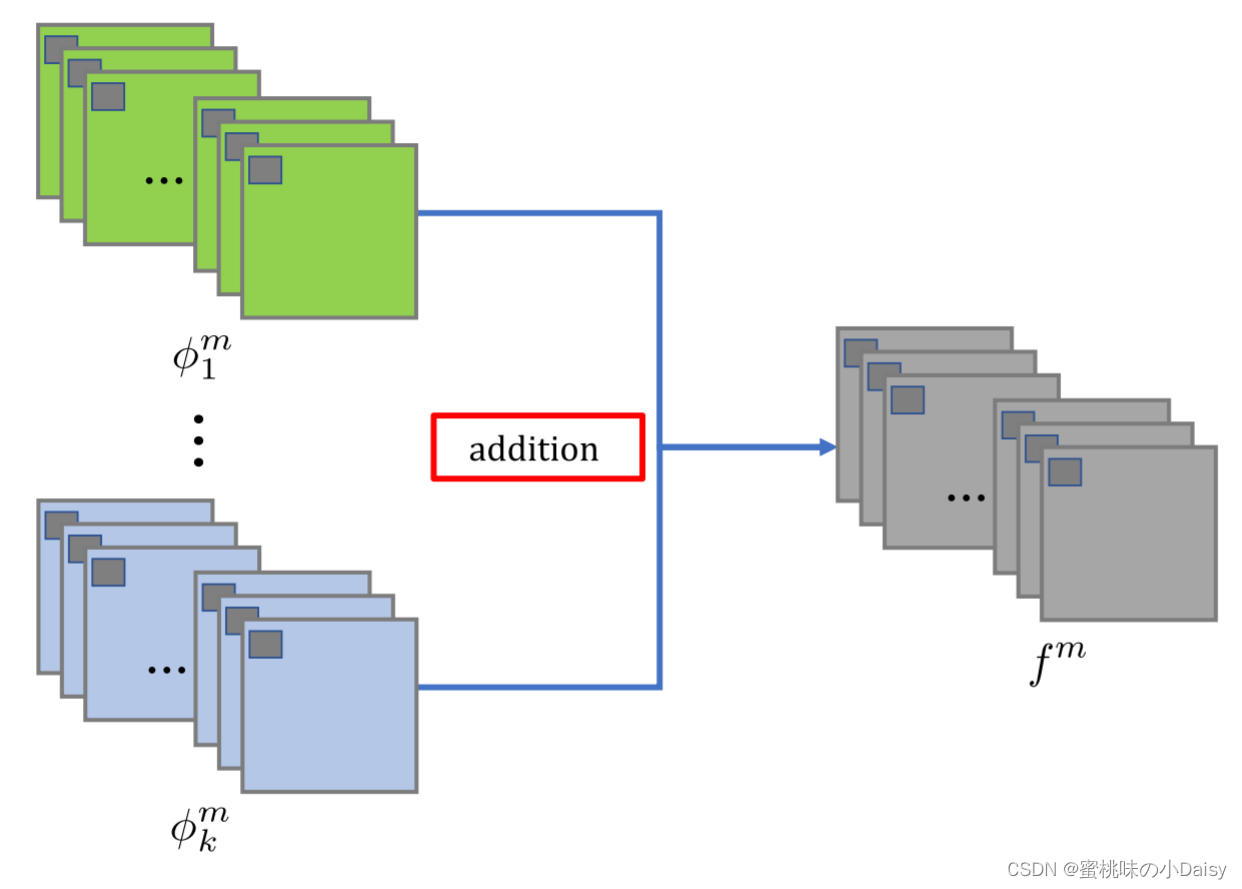
图3 加法策略的过程
-
-
-
-
2.L1范数策略
-
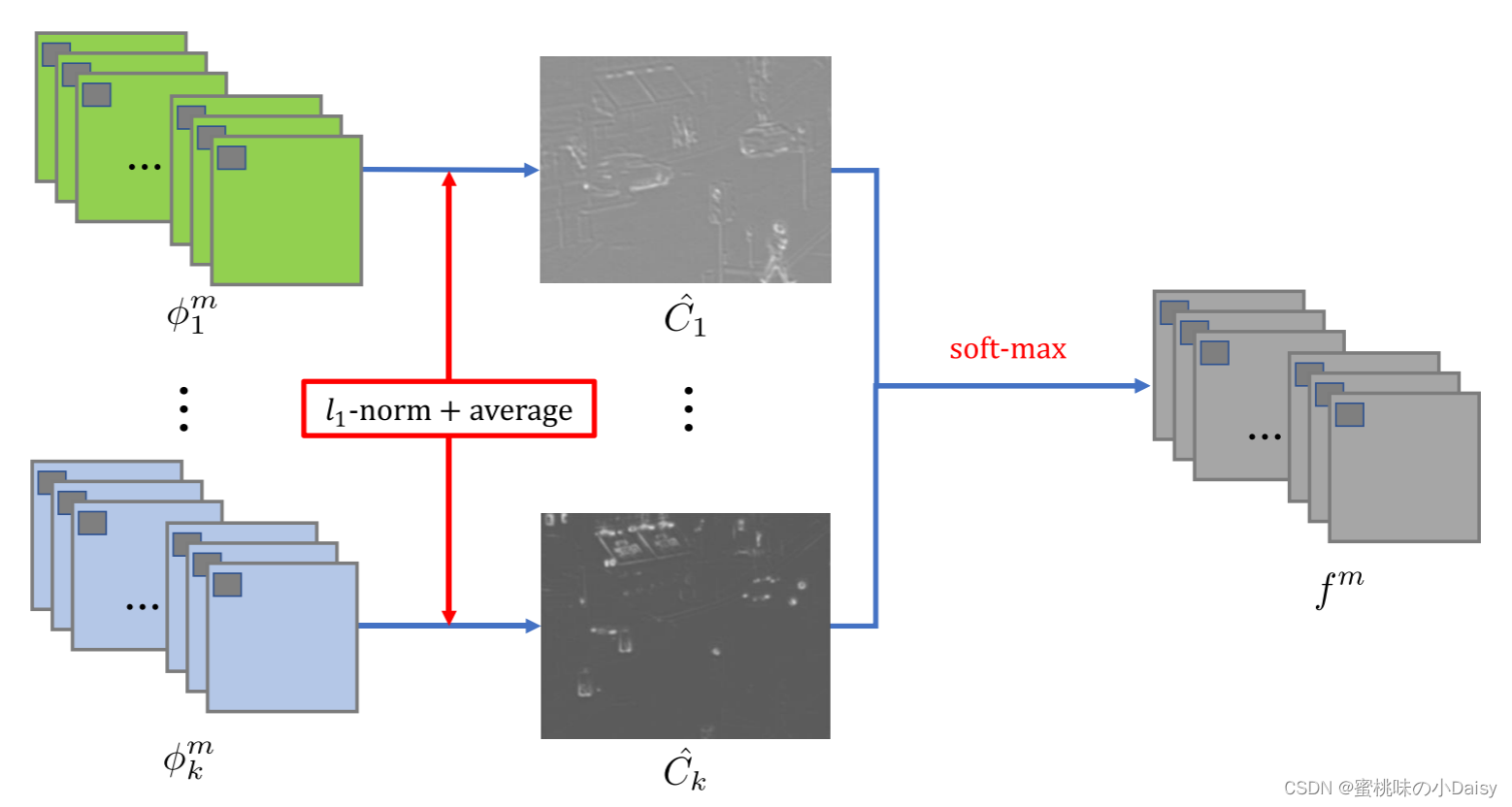
加法策略的性能在[15]中得到了证明。但是这种操作是一种非常粗糙的显著特征选择融合策略。我们采用了一种新的策略,这是基于L1-范数和Softmax运算到我们的网络。该策略的示意图如图4所示。
-
在图4中,特征图由φmi表示,activity level map(这个查了半天资料不知道怎么翻译,暂时先翻译成活动水平图吧没办法了) Ci将通过L1范数和基于块的平均计算,并且fm仍然表示融合的特征图。受Liu等人[12]的启发,φ1:Mi(x,y)的L1范数可以是特征图的活动水平度量。因此,通过公式5计算初始活动水平图Ci,
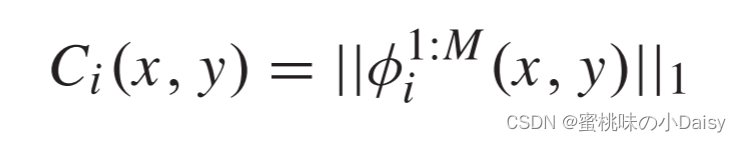
-
然后,利用基于块的平均算法来通过公式6计算最终活动水平图C^i。其中r确定块大小,在我们的策略中r = 1。(这里的r不太清楚是怎么选择的,论文也没有具体细说,也没加引用,一头雾水。)
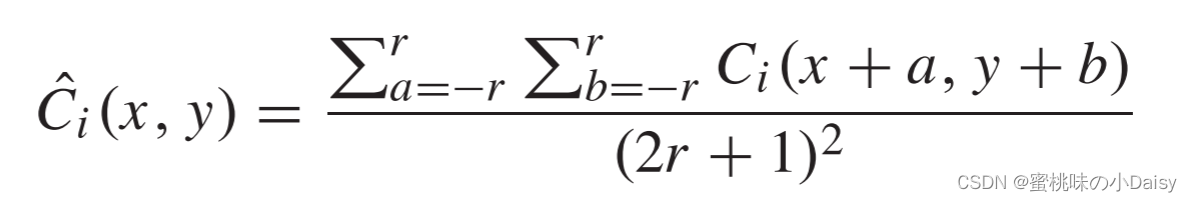
-
在我们得到最终的活动水平图C^i之后,fm由公式7计算,解码器将融合后的特征映射fm作为输入,重构出最终的融合图像。
-
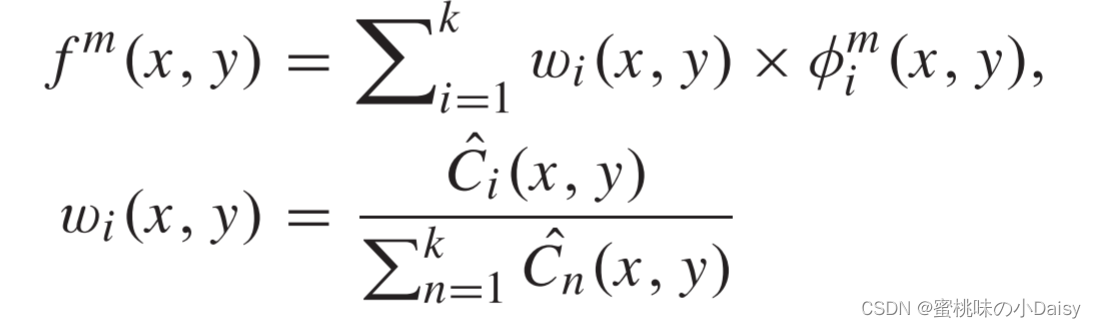
-
-
图4 L1范数与soft-max 策略的示意图
-
-
-
-
-
-
-
-
-
损失函数
-
为了更精确地重建输入图像,我们最小化损失函数L来训练我们的编码器和解码器,L是像素损失Lp和结构相似性(SSIM)损失Lssim与权重λ的加权组合。(这里的损失函数还比较简单,只有两部分。就是说这个时候损失函数还没有后来那么卷。。。)
-
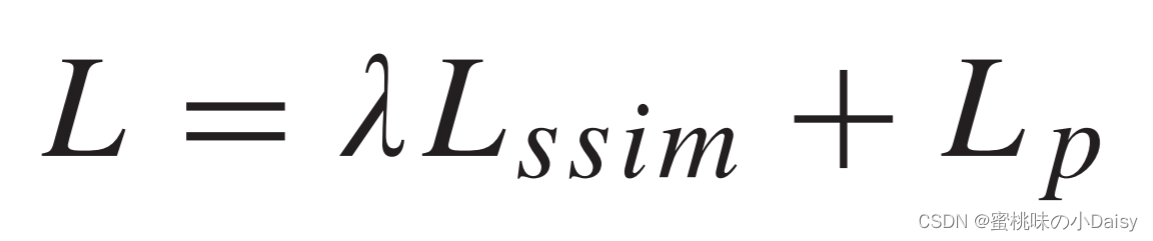
-
像素损失Lp计算为,其中O和I分别表示输出和输入图像。它是输出O和输入I之间的欧几里得距离。
-
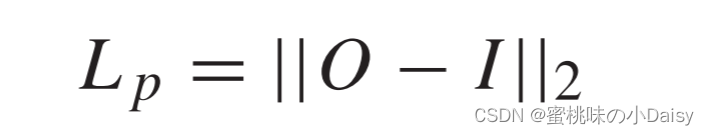
-
SSIM损耗Lssim由公式3获得,其中SSIM(·)表示结构相似性操作[17],它表示两个图像的结构相似性。由于像素损失和SSIM损失之间存在三个数量级的差异,因此在训练阶段,λ分别设置为1,10,100和1000。(这个λ后面的实验还做了对比实验,有兴趣的可以去论文看看。我这里就不放了。)
-
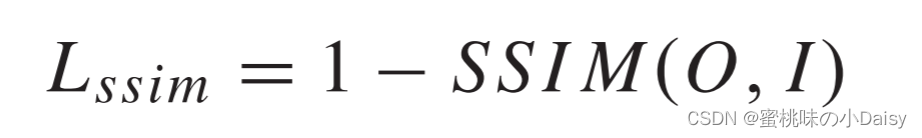
-
-
-
-
实验结果与分析
-
实验部分大家可以去论文看下吧。
-
D.RGB图像和红外图像的其他结果(这里就简单说一下前面说过的RGB的通道)
-
除了灰度图像融合任务之外,论文的融合算法还可以用于融合包括RGB通道的可见光图像和红外图像。如图10所示。我们使用固定的网络(编码器,融合层,解码器)来融合这些图像。在处理RGB灰度图像时,将RGB中的每个通道视为一个灰度图像。因此,对于一对RGB比例图像有三对通道,每对通道都将是我们网络的输入图像。然后,通过我们的网络获得三个融合通道,并将这些融合通道联合组合为一个融合RGB图像。
-
(简单来说就是将RGB拆分成3个灰度图像分别与红外图像进行融合,最后再合成RGB图像。)
-
RGB比例尺图像和红外图像的融合结果如图11所示。(图11是红外与RGB的结果哈,实验的结果我都不放了哈,大家去论文看喽)
-
-
图10 RGB图像的融合框架
-
-
-
结论
-
针对红外和可见光图像融合问题,提出了一种新颖有效的基于CNN和密集块的深度学习架构。该算法不仅适用于灰度图像的融合,也适用于RGB图像的融合。网络有三个部分:编码器,融合层和解码器。首先,源图像(红外和可见光图像)被用作编码器的输入。通过CNN层和密集块得到特征映射,并采用加法和l1范数融合策略进行融合。经过融合层后,这些特征图被整合成一个包含源图像所有显著特征的特征图。最后,通过解码器网络重构融合图像。使用主观和客观的质量指标来评估我们的融合方法。实验结果表明,该方法具有最先进的融合性能。初步实验表明,网络架构可以适用于其他图像融合问题与适当的融合层,如多聚焦图像融合,多曝光图像融合和医学图像融合。
-
-
看到这里就结束啦!撒花✿✿ヽ(°▽°)ノ✿
-
这里有一个个人的感悟就是:这一篇是基于AE的框架的融合,看之前没了解流派。看的时候慢慢感触到了这不就是AE嘛,最后就是觉得AE和CNN是分不太清楚的,焦不离孟。大家即使选定了流派做,但在idea上也不要有太大的局限性吧。
-
DenseFuse【读论文】
最新推荐文章于 2025-04-01 20:19:55 发布


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









