






目录
分类问题的目标变量是标称型数据,或者离散型数据。而回归的目标变量为连续型,也即是回归对连续型变量做出预测,最直接的办法是依据输入写出一个目标值的计算公式,这样对于给定的输入,利用该公式可以计算出相应的预测输出。这个公式称为回归方程,而求回归方程显然就是求该方程的回归系数,而一旦有了这些回归系数,再给定输入,就可以将这些回归系数乘以输入值,就得到了预测值。
线性回归
将输入项分别乘以一些常量,再将结果加起来得到输出。假设输入数据存放在矩阵x中,而回归系数存放在向量w中,那么对于给定的数据x1,预测结果将会通过
Y
=
θ
T
X
Y=\theta^TX
Y=θTX给出。问题的关键就变成了如何找到合适的参数
θ
\theta
θ。

最小二乘法
预测值
θ
T
x
i
\theta^Tx^i
θTxi与真实值
y
i
y^i
yi之间一定会存在误差
ϵ
i
\epsilon^i
ϵi。
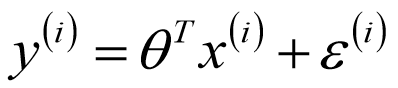
根据中心极限定理,可认为这些误差是独立同分布的,服从均值为0(由于
θ
0
的
存
在
\theta_0的存在
θ0的存在),方差为
σ
2
\sigma^2
σ2的高斯分布。
ϵ
i
\epsilon^i
ϵi出现的概率:
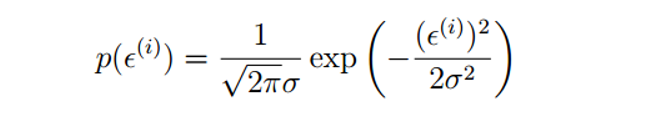
在
θ
\theta
θ与
x
i
x^i
xi确定时
y
i
y^i
yi出现的概率:
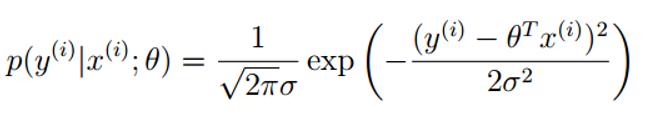
似然函数:

对数似然:

目标函数:
欲使似然函数取最大值,则结果中减号后面一部分要取最小值,将该部分命名为目标函数。
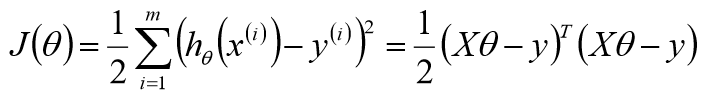
目标函数求解:
计算梯度,寻找驻点。


为了防止
X
T
X
X^TX
XTX不可逆,往往在主对角线元素上添加微小的数值,称为扰动。该参数不仅可以保证
X
T
X
X^TX
XTX可逆,还可以作为正则项防止过拟合,下文详细说明。
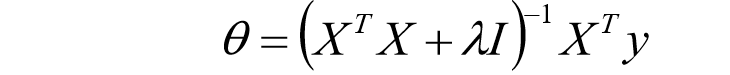
广义逆矩阵


Logistic回归
Logistic回归是统计学习中的经典分类方法,属于对数线性模型,所以也被称为对数几率回归。虽然带有回归的字眼,但是该模型是一种分类算法,Logistic回归是一种线性分类器,针对的是线性可分问题。利用logistic回归进行分类的主要思想是:根据现有的数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示要找到最佳拟合参数集,因此,logistic训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化方法。

sigmoid函数

用
θ
T
x
\theta^Tx
θTx代替
z
z
z
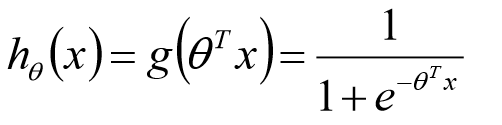
Logistic回归的学习过程

似然函数:
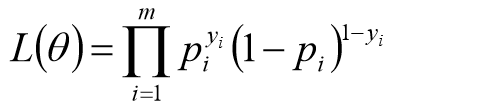
对数似然:
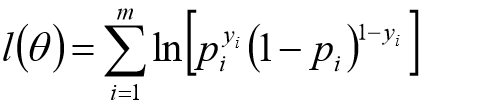
损失函数:
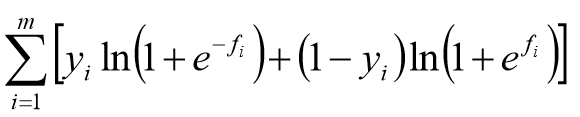
梯度:

参数的迭代:

Softmax回归
线性回归解决的连续值的预测,逻辑回归解决的是离散值的预测,而且针对二分类问题。若因变量y有k个取值,这是一个多分类问题,二分类模型在这里不太适用,Softmax回归针对的就是这种问题。

对于输入数据有k个类别,softmax 回归主要估算输入数据
x
i
x_i
xi归属于每一类的概率。

各个类别概率位于[0,1],并且概率之和为 1。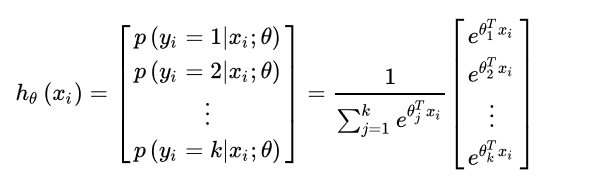
数据
x
i
x_i
xi归属于类别
j
j
j的概率为
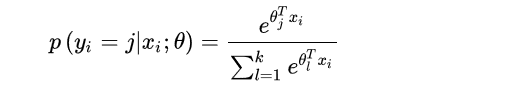
Softmax回归的学习过程
损失函数:
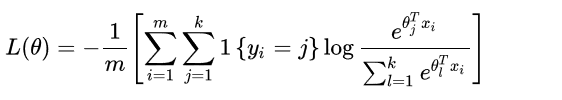
其中,1{·}是示性函数,即1{值为真的表达式}=1,1{值为假的表达式}=0。
梯度:

正则项
正则化是为了防止过拟合, 进而增强泛化能力。

当模型过于复杂时,预测函数总能完美匹配各个样本点,但样本中总会存在噪声,这样的预测函数往往不能很好的预测样本中不存在的数据,这种情况称为过拟合,如上图中的红线。
当模型复杂度降低后,虽然未能完美匹配样本点,但却能更好的表现数据的趋势,如上图中的绿线。
线性回归的复杂度惩罚因子
对目标函数进行改造,将与参数复杂度相关的部分添加到目标函数中,控制参数复杂度,这个惩罚因子称为正则项。
L1正则:
在原始的目标函数后面加上一个L1正则化项,即所有权重的绝对值的和,乘以λ。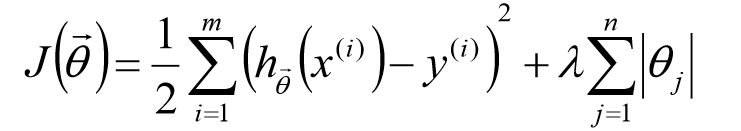
L2正则:
在原始的目标函数后面加上一个L2正则化项,即所有权重的平方和,乘以λ。

Elastic Net:
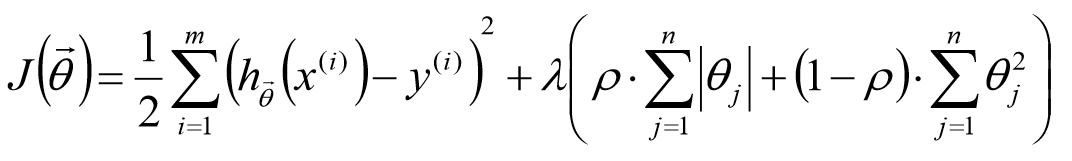
L1正则与L2正则的比较:


蓝色的圆圈表示没有经过限制的损失函数在寻找最小值过程中,参数的不断迭代(随最小二乘法,最终目的还是使损失函数最小)变化情况,表示的方法是等高线,z轴的值就是损失函数。参数取到最理想的点可以直观的理解为蓝圈与红圈的和的最小值,而这个值通在很多情况下是两个曲面相交的地方。
L2正则项的优势:处处可导,方便计算。
L2正则项的劣势:只是使得模型的参数值趋近于0,而不是等于0,这样就无法丢掉模型里的任何一个特征,因此无法做到稀疏化。
L1正则项的优势:可以使得大部分模型参数的值等于0,这些权值等于0的特征可以省去,从而达到稀疏化的目的。
L1正则项的劣势:一次正则项有拐点,不是处处可微,给计算带来了难度。
梯度下降算法
初始化
θ
\theta
θ(随机初始化),沿着负梯度方向迭代,更新后的
θ
\theta
θ使
J
(
θ
)
J(\theta)
J(θ)更小。


梯度方向

批量梯度下降法
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
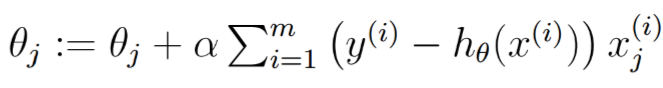

优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
当样本数目 mm 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
随机梯度下降法
随机梯度下降法不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新,使得训练速度加快。

优点:
由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
小批量梯度下降法
小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用 batch_size 个样本来对参数进行更新。
优点:
(1)通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
(3)可实现并行化。
缺点:
batch_size的不当选择可能会带来一些问题。
决定系数:
拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高,观察点在回归直线附近越密集。
1、样本总平方和TSS:
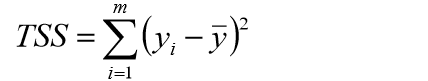
2、残差平方和RSS:
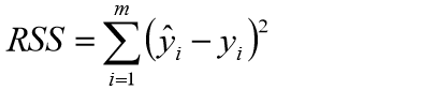
3、
R
2
R^2
R2:
为了判定模型拟合的好坏,定义
R
2
R^2
R2判定。


4、回归平方和ESS:
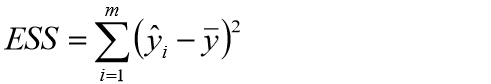
TSS >= RSS + ESS
只有在无偏估计时等号才成立。
分类器指标
ROC (Receiver Operating Characteristic) 曲线和 AUC (Area Under the Curve) 值常被用来评价一个二值分类器 (binary classifier) 的优劣。
混淆矩阵

真正例(True Positive,TP):真实类别为正例,预测类别为正例;
假正例(False Positive,FP):真实类别为负例,预测类别为正例;
假负例(False Negative,FN):真实类别为正例,预测类别为负例;
真负例(True Negative,TN):真实类别为负例,预测类别为负例。
准确率,又称查准率(Precision,P):
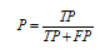
召回率,又称查全率(Recall,R):
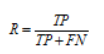
F1值:
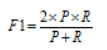
ROC曲线
ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)(也就是recall)。

AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
AUC值越大的分类器,正确率越高。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样,模型没有预测价值。
- AUC < 0.5,比随机猜测还差,但只要总是反预测而行,就优于随机猜测,因此不存在AUC < 0.5的情况。















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









