






线性回归
1、概念
利用线性关系来描述输入到输出的映射关系。
例:
2、应用场景
网络分析、银行风险分析、基金股价预测、天气预报······
3、优化方法
梯度下降法:


梯度计算:

参数更新:
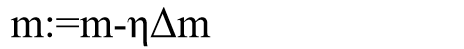
4、输出
可以多目标学习,通过合并多个任务loss,一般能够产生此单个模型更好的效果。

5、局限
线性回归能够清楚的描述分割线性分布的数据,对非线性分布的数据描述较弱。

从线性到非线性
1、非线性激励

2、考量标准
- 正向对输入的调整
- 反向梯度损失
3、常用非线性激励函数
- Sigmoid
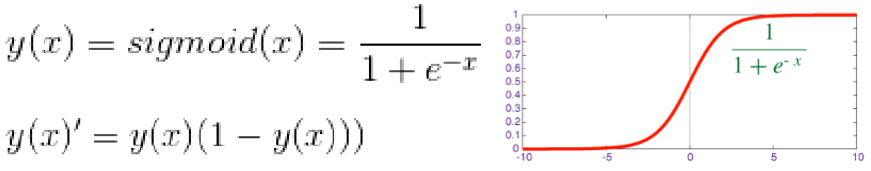
能将输入数据映射到[0,1],但反向梯度下降非常明显。 - tahn
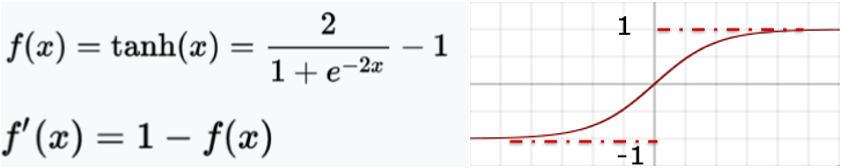
能将输入数据映射到[-1,1],反向梯度下降明显。 - ReLU

正向截断负值损失大量特征,反向梯度没有损失 - Leaky ReLU

与ReLU相比保留更多参数,反向梯度没有损失,负值时少量梯度反向传播
神经网络的构建
从第一层神经网络到最终输出,每一个神经元的数值由前一层神经元数值,神经元参数W、b以及激励函数共同决定第n+1层第k个神经元的方程,可由公式表示为:
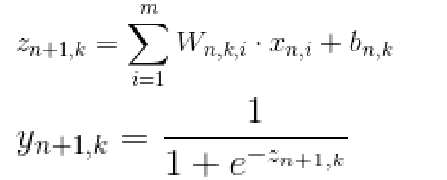
在这里,m表示第n层神经网络的宽度,n为当前神经网络的深度。

神经网络的配件
1、损失函数-Loss
影响深度学习性能最重要因素之一,是外部世界对神经网络模型训练的直接指导。合适的损失函数能够确保深度学习模型收敛的更好,设计合适的损失函数是研究工作的主要内容之一。
- Softmax
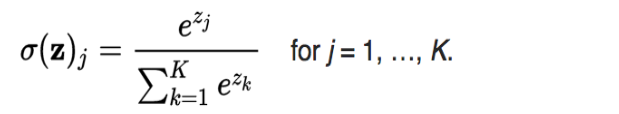
使用Softmax函数的好处是这样可以使得分类问题的预测结果更加明显,不同类别之间的差距更大。 - Cross entropy
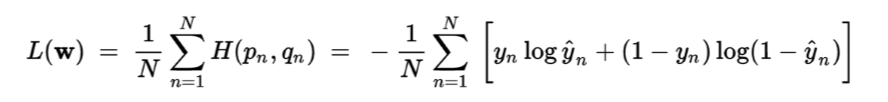
Cross entropy的用途:可以用于目标为[0,1]区间的回归问题,以及生成问题。 - 自定义损失函数
看中某一个属性:单独将某一些预测值取出或者赋予不同大小的参数;
合并多个loss:多目标训练任务,设置合理的loss结合方式。例如图片中,识别位置的loss和识别种类的loss作相应的结合,最终结合到一起共同指导模型的训练;
神经网络融合:不同神经网络loss结合,共同loss对网络进行训练指导,emsemble.
2、学习率-Learning rate

设置的数值大,收敛的速度比较快;设置的数值小,则产生的精度比较高。
学习率的设置:
- Fixed 直接固定学习率
- Step 通过设置步长逐步调整学习速率
- Adagrad 在训练参数的过程中动态调整学习率
3、动量
在模型梯度下降的过程中,会让模型沿着已经得到优化的方向前进,不用重新找方向,只是需要微调。


前一种是在原点上考虑梯度,然后结合动量投射相加做更新;
后一种是在动量投射的基础之上进行梯度更新,动量相加做更新。
4、过拟合-Overfitting

如果更多的参数能够参与决策,会对输入有更高的适应性,w‘更好。
应对过拟合:
- Regularization

- Dropout
随机的选择一部分神经元将他们的输出置为零,一般选择的Dropout的比例为50%。随机选择神经元节点会使得表现更加均衡。 - Fine-tuning /Data Augmentation
本质上就是用一些已经训练好的模型,再去进行训练,这个过程中,大部分的参数已经不用再更新,实际的参数大量减少。
















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









