






HMM定义
1、马尔可夫链
马尔可夫链是满足马尔可夫性质的随机过程。马尔可夫性质是无记忆性,也就是说,这一时刻的状态,受且只受前一时刻的影响,而不受更往前时刻的状态的影响。我们下面说的隐藏状态序列就马尔可夫链。
2、隐马尔可夫模型
隐马尔科夫模型(HMM, Hidden Markov Model)可用标注问题,在语音识别、NLP、生物信息、模式识别等领域被实践证明是有效的算法。
HMM是关于时序的概率模型,描述由一个隐藏的马尔科夫链生成不可观测的状态随机序列,再由各个状态生成观测随机序列的过程。
隐马尔科夫模型随机生成的状态随机序列,称为状态序列。每个状态生成一个观测,由此产生的观测随机序列,称为观测序列。

隐马尔科夫模型有初始概率分布、状态转移概率分布以及观测概率分布确定,其形式化定义如下:
设
Q
Q
Q是所有可能状态集合,
V
V
V是所有可能的观测的集合
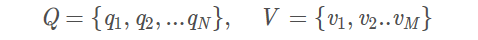
其中
N
N
N是可能的状态数,
M
M
M是可能的观测数。
I
I
I是长度为
T
T
T的状态序列,
O
O
O是对应的观测序列
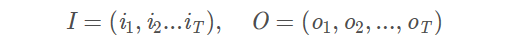
A是状态转移矩阵
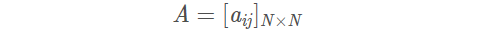
其中

表示的是
t
t
t时刻处于
q
i
q_i
qi的条件下在
t
+
1
t+1
t+1时刻状态转移到
q
j
q_j
qj的概率。
B是观测概率矩阵
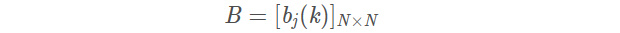
其中
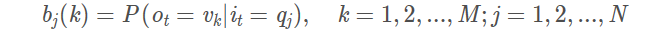
是在时刻t处于状态
q
j
q_j
qj的条件下生成观测
v
k
v_k
vk的概率。
π
π
π是初始状态概率向量
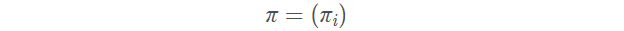
其中
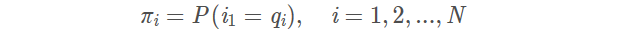
所以隐马尔科夫模型
λ
\lambda
λ可以用三元符号表示,即

隐马尔科夫模型的两个性质
1、齐次马尔科夫性假设
即设隐藏的马尔科夫链在任意时刻
t
t
t的状态只依赖于前一时刻的状态,与其他时刻的状态以及观测无关。
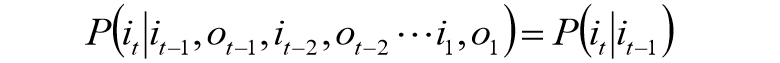
2、观测独立性假设
即假设任意时刻的观测只依赖该时刻的马尔科夫链的状态,与其他观测和状态无关。
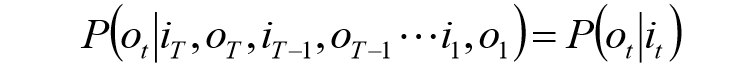
HMM的三个基本问题
1、概率计算问题
给定模型
λ
=
(
A
,
B
,
π
)
\lambda=(A,B,\pi)
λ=(A,B,π)和观测序列
O
=
(
o
1
,
o
2
,
.
.
.
,
o
T
)
O=(o_1,o_2,...,o_T)
O=(o1,o2,...,oT)计算在模型
λ
\lambda
λ下观测序列为
O
O
O的概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。
2、学习问题
已知观测序列
O
=
(
o
1
,
o
2
,
.
.
.
,
o
T
)
O=(o_1,o_2,...,o_T)
O=(o1,o2,...,oT),估计模型
λ
=
(
A
,
B
,
π
)
\lambda=(A,B,\pi)
λ=(A,B,π)的参数,使得在该模型下观测序列概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)最大。
3、预测问题
也成为解码问题。已知模型
λ
=
(
A
,
B
,
π
)
\lambda=(A,B,\pi)
λ=(A,B,π)和观测序列
O
=
(
o
1
,
o
2
,
.
.
.
,
o
T
)
O=(o_1,o_2,...,o_T)
O=(o1,o2,...,oT),求对给定的观测序列概率P
P
(
I
∣
O
)
P(I|O)
P(I∣O)的最大值。即给定观测序列,求最有可能的对应状态序列。
概率计算问题
直接计算法
按照概率公式,列举所有可能的长度为
T
T
T的状态序列
I
=
{
i
1
,
i
2
,
⋅
⋅
⋅
,
i
t
}
I=\{i_1,i_2,···,i_t\}
I={i1,i2,⋅⋅⋅,it}求各个状态序列
I
I
I与观测序列
O
=
{
o
1
,
o
2
,
⋅
⋅
⋅
,
o
t
}
O=\{o_1,o_2,···,o_t\}
O={o1,o2,⋅⋅⋅,ot}的联合概率
P
(
O
,
I
∣
λ
)
P(O,I|\lambda)
P(O,I∣λ),然后对所有可能的状态序列求和,从而得到
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。
状态序列
I
=
{
i
1
,
i
2
,
⋅
⋅
⋅
,
i
t
}
I=\{i_1,i_2,···,i_t\}
I={i1,i2,⋅⋅⋅,it}的概率是:
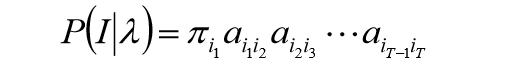
对固定的状态序列
I
I
I,观测序列
O
O
O的概率是:
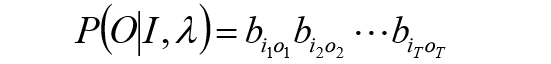
O
O
O和
I
I
I同时出现的联合概率是:
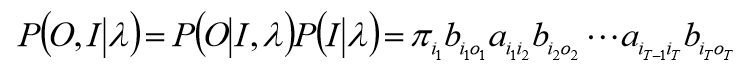
对所有可能的状态序列
I
I
I求和,得到观测序列
O
O
O的概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ):
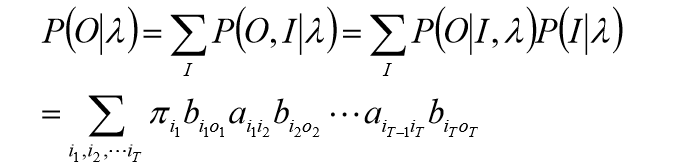
最终式:
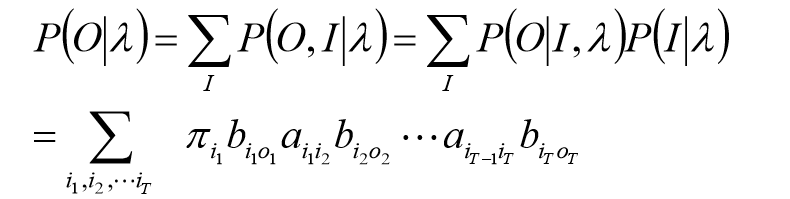
前向算法
给定
λ
\lambda
λ,定义到时刻
t
t
t部分观测序列为
o
1
,
o
2
,
.
.
.
,
o
t
o1,o2,...,ot
o1,o2,...,ot且状态为
q
i
qi
qi的概率称为前向概率,记做:
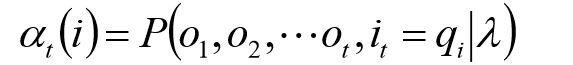
可以递推计算前向概率
a
t
(
i
)
a_t(i)
at(i)及观测序列概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。
初值:
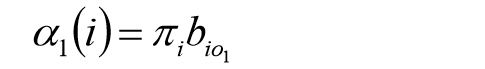
递推:
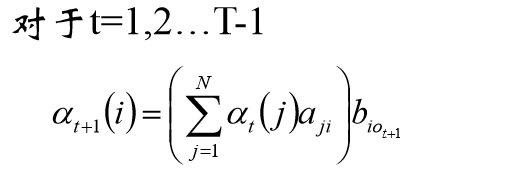
最终:
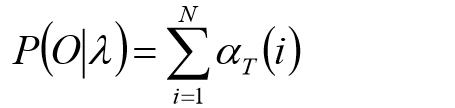
后向算法
给定
λ
\lambda
λ,定义到时刻
t
t
t状态为
q
i
qi
qi的前提下,从
t
+
1
t+1
t+1到
T
T
T的部分观测序列为
o
t
+
1
,
o
t
+
2..
o
T
ot+1,ot+2..oT
ot+1,ot+2..oT的概率为后向概率,记做:
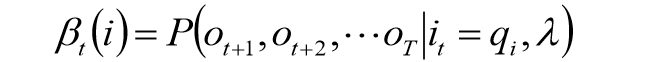
可以递推计算后向概率
β
t
(
i
)
\beta_t(i)
βt(i)及观测序列概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。
初值:

递推:

最终:
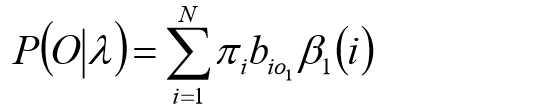
说明:
为了计算在时刻
t
t
t状态为
q
i
qi
qi条件下时刻
t
+
1
t+1
t+1之后的观测序列为
o
t
+
1
,
o
t
+
2
,
.
.
.
,
o
T
ot+1,ot+2,...,oT
ot+1,ot+2,...,oT的后向概率
β
t
(
i
)
\beta_t(i)
βt(i),只需要考虑在时刻
t
+
1
t+1
t+1所有可能的
N
N
N个状态
q
j
qj
qj的转移概率
(
a
i
j
项
)
(aij项)
(aij项),以及在此状态下的观测
o
t
+
1
ot+1
ot+1的观测概率
(
b
j
o
t
+
1
项
)
(bjot+1项)
(bjot+1项) ,然后考虑状态
q
j
qj
qj之后的观测序列的后向概率
β
t
(
j
)
\beta_t(j)
βt(j)。
Baum-Welch算法
若训练数据只有观测序列,则HMM的学习需要使用EM算法,是非监督学习。
EM算法整体框架:

所有观测数据写成
O
=
(
o
1
,
o
2
,
.
.
.
,
o
T
)
O=(o_1,o_2,...,o_T)
O=(o1,o2,...,oT),所有隐数据写成
I
=
(
i
1
,
i
2
,
.
.
.
,
i
T
)
I=(i_1,i_2,...,i_T)
I=(i1,i2,...,iT),完全数据是
(
O
,
I
)
=
(
o
1
,
o
2
,
.
.
.
,
o
T
,
i
1
,
i
2
,
.
.
.
,
i
T
)
(O,I)=(o_1,o_2,...,o_T,i_1,i_2,...,i_T)
(O,I)=(o1,o2,...,oT,i1,i2,...,iT)完全数据的对数似然函数是
I
n
P
(
O
,
I
∣
λ
)
InP(O,I|\lambda)
InP(O,I∣λ)。
假设
λ
‾
\overline{\lambda}
λ是HMM参数的当前估计值,入为待求的参数。

EM过程
根据:
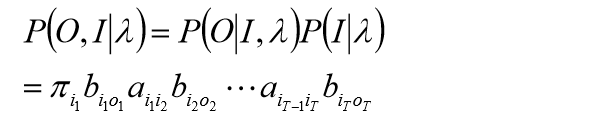
函数可写成:

极大化
极大化
Q
Q
Q,求得参数
A
,
B
,
π
A,B,\pi
A,B,π,由于该三个参数分别位于三个项中,可分别极大化:
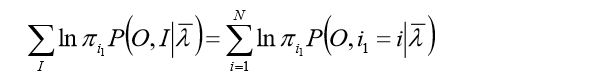
注意
π
i
\pi_i
πi满足加和为1,利用拉格朗日乘子法得到:
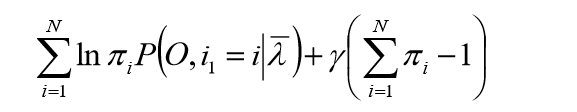
初始状态概率
对上式相对于
T
i
T_i
Ti求偏导得到:
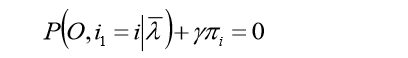
对
i
i
i求和得到:
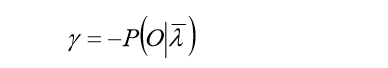
从而得到初始状态概率:

转移概率和观测概率
第二项可写成:
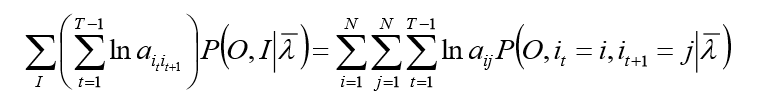
仍然使用拉格朗日乘子法,得到:
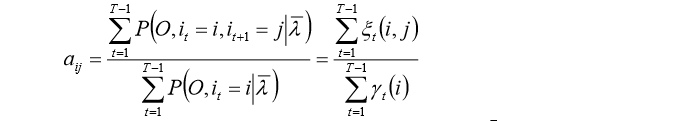
同理,得到:
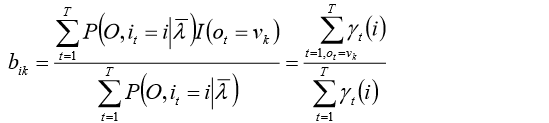
预测算法
近似算法
在每个时刻
t
t
t选择在该时刻最有可能出现的状态
i
t
∗
i_t^*
it∗,从而得到一个状态序列
I
∗
=
{
i
1
∗
,
i
2
∗
,
.
.
.
,
i
t
∗
}
I^*=\{i_1^*,i_2^*, ...,i_t^*\}
I∗={i1∗,i2∗,...,it∗},将它作为预测的结果。
给定模型和观测序列,时刻
t
t
t处于状态
q
i
q_i
qi的概为:
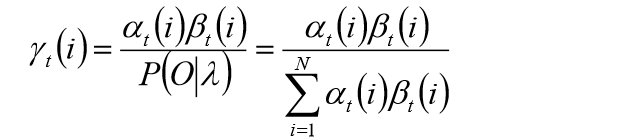
Viterbi算法
Viterbi算法实际是用动态规划解HMM预测问题,用DP求概率最大的路径(最优路径),这是一条路径对应一个状态序列。
定义变量
δ
t
(
i
)
\delta_t(i)
δt(i):在时刻
t
t
t状态为
i
i
i的所有路径中,概率的最大值。
定义:
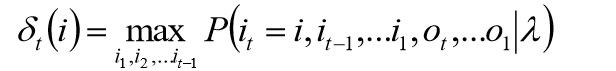
递推:

终止:
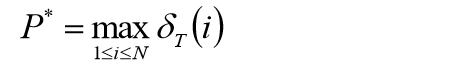















 2844
2844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









