






Diffusion扩散模型
本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。
本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确保执行环境安装了GUI界面。
关于扩散模型(Diffusion Models)有很多种理解,本文的介绍是基于denoising diffusion probabilistic model (DDPM),DDPM已经在(无)条件图像/音频/视频生成领域取得了较多显著的成果,现有的比较受欢迎的的例子包括由OpenAI主导的GLIDE和DALL-E 2、由海德堡大学主导的潜在扩散和由Google Brain主导的图像生成。
实际上生成模型的扩散概念已经在(Sohl-Dickstein et al., 2015)中介绍过。然而,直到(Song et al., 2019)(斯坦福大学)和(Ho et al., 2020)(在Google Brain)才各自独立地改进了这种方法。
本文是在Phil Wang基于PyTorch框架的复现的基础上(而它本身又是基于TensorFlow实现),迁移到MindSpore AI框架上实现的。

实验中我们采用离散时间(潜在变量模型)的观点,另外,读者也可以查看有关于扩散模型的其他几个观点!
实验开始之前请确保安装并导入所需的库(假设您已经安装了MindSpore、download、dataset、matplotlib以及tqdm)。
import math # 导入数学库以便进行数学计算
from functools import partial # 从functools库导入partial函数,用于偏函数
%matplotlib inline # 为Jupyter Notebook设置内联绘图
import matplotlib.pyplot as plt # 导入matplotlib库中的pyplot模块用于绘图
from tqdm.auto import tqdm # 导入tqdm库的自动进度条
import numpy as np # 导入numpy库用于数值计算
from multiprocessing import cpu_count # 从multiprocessing库导入cpu_count函数,用于获取CPU核心数量
from download import download # 从download模块导入download函数,用于下载文件
import mindspore as ms # 导入MindSpore库
import mindspore.nn as nn # 导入MindSpore的神经网络模块
import mindspore.ops as ops # 导入MindSpore的操作模块
from mindspore import Tensor, Parameter # 从MindSpore导入Tensor和Parameter类
from mindspore import dtype as mstype # 将MindSpore的数据类型模块命名为mstype
from mindspore.dataset.vision import Resize, Inter, CenterCrop, ToTensor, RandomHorizontalFlip, ToPIL # 导入图像处理相关的操作
from mindspore.common.initializer import initializer # 导入MindSpore的初始化器
from mindspore.amp import DynamicLossScaler # 导入动态损失缩放
ms.set_seed(0) # 设置随机种子为0,以确保实验的可重复性
解析:
- 数学库和偏函数:
import math和from functools import partial引入了数学计算和偏函数的功能,以便在后续的代码中使用。 - Jupyter Notebook绘图:
%matplotlib inline用于在Jupyter Notebook中直接显示图形。 - 绘图库:
import matplotlib.pyplot as plt导入绘图模块,用于数据可视化。 - 进度条:
from tqdm.auto import tqdm引入进度条,以便在长时间运行的循环中提供可视化反馈。 - 数值计算库:
import numpy as np导入NumPy库,用于高效的数值计算。 - 多进程支持:
from multiprocessing import cpu_count获取CPU核心数量,以便在并行计算中优化性能。 - 文件下载:
from download import download提供了从互联网下载资源的功能。 - MindSpore库:
import mindspore as ms和其他引入的模块使得可以使用MindSpore进行深度学习建模。相关的功能包括神经网络构建(nn)、各种操作(ops)、张量和参数管理。 - 图像处理:从
mindspore.dataset.vision中引入的类用于图像预处理,如调整大小、中心裁剪、随机水平翻转等。 - 初始化器和动态损失缩放:通过
initializer进行权重初始化,DynamicLossScaler用于在混合精度训练中动态调整损失缩放。 - 随机种子设置:
ms.set_seed(0)确保使用相同的随机种子可以重现实验结果。
模型简介
什么是Diffusion Model?
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
- 我们选择的固定(或预定义)正向扩散过程 q𝑞 :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
- 一个学习的反向去噪的扩散过程 pθ𝑝𝜃 :通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像
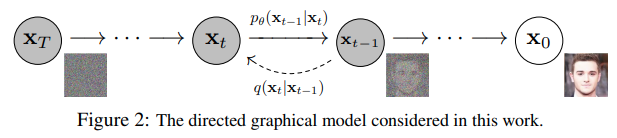
由 t 索引的正向和反向过程都发生在某些有限时间步长 T(DDPM作者使用 T=1000)内。从t=0𝑡=0开始,在数据分布中采样真实图像 x0𝑥0(本文使用一张来自ImageNet的猫图像形象的展示了diffusion正向添加噪声的过程),正向过程在每个时间步长 t都从高斯分布中采样一些噪声,再添加到上一个时刻的图像中。假定给定一个足够大的 T和一个在每个时间步长添加噪声的良好时间表,您最终会在 t=T=𝑇 通过渐进的过程得到所谓的各向同性的高斯分布。
扩散模型实现原理
Diffusion 前向过程
所谓前向过程,即向图片上加噪声的过程。虽然这个步骤无法做到图片生成,但这是理解diffusion model以及构建训练样本至关重要的一步。 首先我们需要一个可控的损失函数,并运用神经网络对其进行优化。
Diffusion 前向过程
所谓前向过程,即向图片上加噪声的过程。虽然这个步骤无法做到图片生成,但这是理解diffusion model以及构建训练样本至关重要的一步。
首先我们需要一个可控的损失函数,并运用神经网络对其进行优化。
设 是真实数据分布,由于 ,所以我们可以从这个分布中采样以获得图像 。接下来我们定义前向扩散过程 ,在前向过程中我们会根据已知的方差 在每个时间步长 t 添加高斯噪声,由于前向过程的每个时刻 t 只与时刻 t-1 有关,所以也可以看做马尔科夫过程:
回想一下,正态分布(也称为高斯分布)由两个参数定义:平均值 和方差 。基本上,在每个时间步长 处的产生的每个新的(轻微噪声)图像都是从条件高斯分布中绘制的,其中
我们可以通过采样 然后设置
请注意, 在每个时间步长 (因此是下标)不是恒定的:事实上,我们定义了一个所谓的“动态方差”的方法,使得每个时间步长的 可以是线性的、二次的、余弦的等(有点像动态学习率方法)。
因此,如果我们适当设置时间表,从 开始,我们最终得到 ,即随着 的增大 会越来越接近纯噪声,而 就是纯高斯噪声。
那么,如果我们知道条件概率分布 ,我们就可以反向运行这个过程:通过采样一些随机高斯噪声 ,然后逐渐去噪它,最终得到真实分布 中的样本。但是,我们不知道条件概率分布 。这很棘手,因为需要知道所有可能图像的分布,才能计算这个条件概率。
正如Ho等人所展示的那样,这种性质的另一个优点是可以重新参数化平均值,使神经网络学习(预测)构成损失的KL项中噪声的附加噪声。这意味着我们的神经网络变成了噪声预测器,而不是(直接)均值预测器。其中,平均值可以按如下方式计算:
$$ \mathbf{\mu}_\theta(\mathbf{x}_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1- \bar{\alpha}_t}} \mathbf{\epsilon}_\theta(\mathbf{x}_t, t) \right) $$
最终的目标函数 ${L}_{t}$ 如下 (随机步长 t 由 $({\epsilon} \sim N(\mathbf{0}, \mathbf{I}))$ 给定):
$$ \| \mathbf{\epsilon} - \mathbf{\epsilon}_\theta(\mathbf{x}_t, t) \|^2 = \| \mathbf{\epsilon} - \mathbf{\epsilon}_\theta( \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{(1- \bar{\alpha}_t) } \mathbf{\epsilon}, t) \|^2$$
在这里,
x
0
是初始(真实,未损坏)图像,是初始(真实,未损坏)图像,
ϵ
是在时间步长是在时间步长
t
采样的纯噪声,采样的纯噪声,
ϵ
θ
(
x
t
,
t
)
\mathbf{x}_0是初始(真实,未损坏)图像,是初始(真实,未损坏)图像,\mathbf{\epsilon}是在时间步长是在时间步长t采样的纯噪声,采样的纯噪声,\mathbf{\epsilon}_\theta (\mathbf{x}_t, t)
x0是初始(真实,未损坏)图像,是初始(真实,未损坏)图像,ϵ是在时间步长是在时间步长t采样的纯噪声,采样的纯噪声,ϵθ(xt,t)是我们的神经网络。神经网络是基于真实噪声和预测高斯噪声之间的简单均方误差(MSE)进行优化的。
训练算法现在如下所示:

换句话说:
- 我们从真实未知和可能复杂的数据分布中随机抽取一个样本 q(x0)𝑞(𝑥0)
- 我们均匀地采样11和T𝑇之间的噪声水平t𝑡(即,随机时间步长)
- 我们从高斯分布中采样一些噪声,并使用上面定义的属性在 t𝑡 时间步上破坏输入
- 神经网络被训练以基于损坏的图像 xt𝑥𝑡 来预测这种噪声,即基于已知的时间表 xt𝑥𝑡 上施加的噪声
实际上,所有这些都是在批数据上使用随机梯度下降来优化神经网络完成的。
U-Net神经网络预测噪声
神经网络需要在特定时间步长接收带噪声的图像,并返回预测的噪声。请注意,预测噪声是与输入图像具有相同大小/分辨率的张量。因此,从技术上讲,网络接受并输出相同形状的张量。那么我们可以用什么类型的神经网络来实现呢?
这里通常使用的是非常相似的自动编码器,您可能还记得典型的"深度学习入门"教程。自动编码器在编码器和解码器之间有一个所谓的"bottleneck"层。编码器首先将图像编码为一个称为"bottleneck"的较小的隐藏表示,然后解码器将该隐藏表示解码回实际图像。这迫使网络只保留bottleneck层中最重要的信息。
在模型结构方面,DDPM的作者选择了U-Net,出自(Ronneberger et al.,2015)(当时,它在医学图像分割方面取得了最先进的结果)。这个网络就像任何自动编码器一样,在中间由一个bottleneck组成,确保网络只学习最重要的信息。重要的是,它在编码器和解码器之间引入了残差连接,极大地改善了梯度流(灵感来自于(He et al., 2015))。
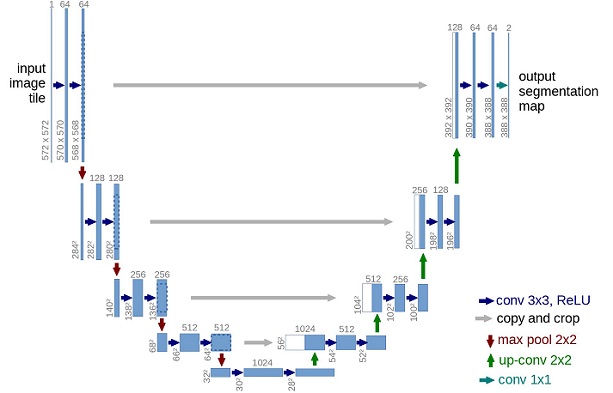
可以看出,U-Net模型首先对输入进行下采样(即,在空间分辨率方面使输入更小),之后执行上采样。
构建Diffusion模型
下面,我们逐步构建Diffusion模型。
首先,我们定义了一些帮助函数和类,这些函数和类将在实现神经网络时使用。
def rearrange(head, inputs):
b, hc, x, y = inputs.shape # 获取输入张量的形状,b为batch size,hc为通道数,x和y为空间维度
c = hc // head # 计算每个头的通道数
return inputs.reshape((b, head, c, x * y)) # 重新调整形状为(b, head, c, x * y)
def rsqrt(x):
res = ops.sqrt(x) # 计算x的平方根
return ops.inv(res) # 返回平方根的倒数
def randn_like(x, dtype=None):
if dtype is None: # 如果没有指定数据类型
dtype = x.dtype # 则使用输入x的dtype
res = ops.standard_normal(x.shape).astype(dtype) # 生成与x相同形状的标准正态分布随机数,并转换为dtype
return res # 返回生成的随机张量
def randn(shape, dtype=None):
if dtype is None: # 如果没有指定数据类型
dtype = ms.float32 # 默认使用float32类型
res = ops.standard_normal(shape).astype(dtype) # 生成指定形状的标准正态分布随机数,并转换为dtype
return res # 返回生成的随机张量
def randint(low, high, size, dtype=ms.int32):
res = ops.uniform(size, Tensor(low, dtype), Tensor(high, dtype), dtype=dtype) # 生成在[low, high)区间内的随机整数
return res # 返回生成的随机整数张量
def exists(x):
return x is not None # 检查x是否存在(即不为None)
def default(val, d):
if exists(val): # 如果val存在
return val # 返回val
return d() if callable(d) else d # 否则返回d的调用结果或d本身
def _check_dtype(d1, d2):
if ms.float32 in (d1, d2): # 如果d1或d2是float32
return ms.float32 # 返回float32
if d1 == d2: # 如果d1和d2相同
return d1 # 返回d1
raise ValueError('dtype is not supported.') # 否则抛出类型不支持的异常
class Residual(nn.Cell):
def __init__(self, fn): # 初始化Residual类,fn为传入的函数
super().__init__() # 调用父类构造函数
self.fn = fn # 将fn赋值给self.fn
def construct(self, x, *args, **kwargs): # 定义前向计算方法
return self.fn(x, *args, **kwargs) + x # 返回fn的输出与输入x相加,形成残差连接
rearrange:该函数用于重新调整输入张量的形状,通常在处理多头注意力机制时使用。它将通道维度分为多个头,并将空间维度展平。rsqrt:计算输入张量的平方根的倒数,常用于归一化操作。randn_like:生成与给定张量x相同形状的标准正态分布随机数。如果指定了数据类型,则使用该类型,否则使用x的类型。randn:根据给定的形状生成标准正态分布的随机数。支持指定数据类型,默认使用ms.float32。randint:生成指定范围内的随机整数,范围在[low, high)之间。支持指定数据类型,默认使用ms.int32。exists:检查输入是否存在(即不为None),用于参数验证。default:返回指定的默认值,如果传入的值存在则返回该值,否则返回默认值。支持默认值为可调用对象的情况。_check_dtype:检查两个数据类型是否相同,如果其中一个是ms.float32则返回ms.float32,如果两者相等则返回其中一个,否则抛出异常。Residual类:该类实现了残差连接结构。初始化时接受一个函数fn,在前向传播时将输入x通过fn处理后与输入x相加,形成残差输出。
我们还定义了上采样和下采样操作的别名。
def Upsample(dim):
# 创建一个转置卷积层,用于上采样
return nn.Conv2dTranspose(dim, dim, 4, 2, pad_mode="pad", padding=1)
# 参数说明:
# dim: 输入和输出的通道数
# 4: 卷积核的大小
# 2: 步幅,指每次滑动的步长
# pad_mode: 填充模式,此处为“pad”
# padding: 添加的填充数量
def Downsample(dim):
# 创建一个卷积层,用于下采样
return nn.Conv2d(dim, dim, 4, 2, pad_mode="pad", padding=1)
# 参数说明:
# dim: 输入和输出的通道数
# 4: 卷积核的大小
# 2: 步幅,指每次滑动的步长
# pad_mode: 填充模式,此处为“pad”
# padding: 添加的填充数量
Upsample:- 该函数返回一个转置卷积层(也称为反卷积层),用于上采样操作。
nn.Conv2dTranspose的参数定义了卷积层的特性:dim: 输入和输出的通道数,即卷积层的深度。4: 卷积核的大小为4x4。2: 步幅为2,意味着在空间维度上每次移动2个像素。pad_mode: 设置为“pad”,指在卷积操作中使用填充。padding: 在每一边添加1个像素的填充,以保持输出的特征图尺寸。
Downsample:- 该函数返回一个标准的卷积层,用于下采样操作。
nn.Conv2d的参数定义了卷积层的特性:dim: 输入和输出的通道数,即卷积层的深度。4: 卷积核的大小为4x4。2: 步幅为2,意味着在空间维度上每次移动2个像素。pad_mode: 设置为“pad”,指在卷积操作中使用填充。padding: 在每一边添加1个像素的填充,以保持输出的特征图尺寸。
使用场景:
Upsample通常用于生成网络(如GANs)中,为了增大特征图的空间尺寸。Downsample通常用于卷积神经网络中的特征提取过程,减少特征图的空间尺寸,同时增加特征的表达能力。
位置向量
由于神经网络的参数在时间(噪声水平)上共享,作者使用正弦位置嵌入来编码t𝑡,灵感来自Transformer(Vaswani et al., 2017)。对于批处理中的每一张图像,神经网络"知道"它在哪个特定时间步长(噪声水平)上运行。
SinusoidalPositionEmbeddings模块采用(batch_size, 1)形状的张量作为输入(即批处理中几个有噪声图像的噪声水平),并将其转换为(batch_size, dim)形状的张量,其中dim是位置嵌入的尺寸。然后,我们将其添加到每个剩余块中。
class SinusoidalPositionEmbeddings(nn.Cell):
def __init__(self, dim):
super().__init__() # 初始化父类
self.dim = dim # 保存维度信息
half_dim = self.dim // 2 # 计算一半的维度
emb = math.log(10000) / (half_dim - 1) # 计算缩放因子
emb = np.exp(np.arange(half_dim) * - emb) # 生成位置编码的基础
self.emb = Tensor(emb, ms.float32) # 将位置编码转换为Tensor并指定数据类型
def construct(self, x):
emb = x[:, None] * self.emb[None, :] # 计算位置编码:x与emb的外积
emb = ops.concat((ops.sin(emb), ops.cos(emb)), axis=-1) # 计算sin和cos值并拼接
return emb # 返回位置编码
__init__:- 构造函数用于初始化类实例,并设置位置编码的维度。
self.dim保存了位置编码的总维度。half_dim计算为维度的一半,通常在位置编码中使用。emb计算缩放因子,使用公式math.log(10000) / (half_dim - 1)生成基础位置编码,这样可以确保不同位置的编码在相同尺度上变化。emb使用np.exp生成位置编码的基础,并将其转换为Tensor,类型为ms.float32。
construct:construct方法是该类的前向传播方法。emb = x[:, None] * self.emb[None, :]:这里使用了广播机制,将输入x乘以self.emb,计算出每个位置的编码。x的形状可能是(batch_size, seq_length),而self.emb是(half_dim,),通过None增加维度后形成外积。emb = ops.concat((ops.sin(emb), ops.cos(emb)), axis=-1):计算emb的正弦和余弦,最后通过ops.concat将其在最后一个维度进行拼接,形成完整的位置编码。- 最终返回的
emb有dim维度,包含了每个位置的正弦和余弦信息。
使用场景:
- Sinusoidal Position Embeddings 通常用于自然语言处理和计算机视觉中的Transformer模型等,帮助模型理解输入序列中的位置信息。通过正弦和余弦函数的组合,模型能够捕捉到相对和绝对位置的关系。
ResNet/ConvNeXT块
接下来,我们定义U-Net模型的核心构建块。DDPM作者使用了一个Wide ResNet块(Zagoruyko et al., 2016),但Phil Wang决定添加ConvNeXT(Liu et al., 2022)替换ResNet,因为后者在图像领域取得了巨大成功。
在最终的U-Net架构中,可以选择其中一个或另一个,本文选择ConvNeXT块构建U-Net模型。
class Block(nn.Cell):
def __init__(self, dim, dim_out, groups=1):
super().__init__() # 初始化父类
self.proj = nn.Conv2d(dim, dim_out, 3, pad_mode="pad", padding=1) # 定义卷积层
self.proj = c(dim, dim_out, 3, padding=1, pad_mode='pad') # 可能是自定义的卷积函数,替代nn.Conv2d
self.norm = nn.GroupNorm(groups, dim_out) # 定义组归一化层
self.act = nn.SiLU() # 定义SiLU激活函数
def construct(self, x, scale_shift=None):
x = self.proj(x) # 应用卷积层
x = self.norm(x) # 应用归一化层
if exists(scale_shift): # 检查scale_shift是否存在
scale, shift = scale_shift # 解包scale和shift
x = x * (scale + 1) + shift # 应用scale和shift变换
x = self.act(x) # 应用激活函数
return x # 返回结果
class ConvNextBlock(nn.Cell):
def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):
super().__init__() # 初始化父类
self.mlp = (
nn.SequentialCell(nn.GELU(), nn.Dense(time_emb_dim, dim)) # 如果时间嵌入维度存在,定义一个MLP
if exists(time_emb_dim)
else None
)
self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, group=dim, pad_mode="pad") # 定义下采样卷积层
self.net = nn.SequentialCell( # 定义主网络结构
nn.GroupNorm(1, dim) if norm else nn.Identity(), # 选择是否使用归一化
nn.Conv2d(dim, dim_out * mult, 3, padding=1, pad_mode="pad"), # 第一个卷积层
nn.GELU(), # 激活函数
nn.GroupNorm(1, dim_out * mult), # 归一化层
nn.Conv2d(dim_out * mult, dim_out, 3, padding=1, pad_mode="pad"), # 第二个卷积层
)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity() # 残差卷积
def construct(self, x, time_emb=None):
h = self.ds_conv(x) # 应用下采样卷积层
if exists(self.mlp) and exists(time_emb): # 如果存在MLP和时间嵌入
assert exists(time_emb), "time embedding must be passed in" # 确保时间嵌入存在
condition = self.mlp(time_emb) # 计算条件嵌入
condition = condition.expand_dims(-1).expand_dims(-1) # 扩展维度以匹配
h = h + condition # 将条件嵌入加到主特征图上
h = self.net(h) # 应用主网络结构
return h + self.res_conv(x) # 返回输出加上残差
Block** 类**:- 构造函数 (
__init__):self.proj: 定义一个卷积层(可能是自定义的卷积函数),用于处理输入特征图。self.norm: 使用组归一化,适用于处理小批量数据,尤其是在特征图中具有多个通道的情况下。self.act: 使用SiLU(Sigmoid Linear Unit)作为激活函数,它在一些任务中表现良好。
- 前向传播 (
construct):x = self.proj(x): 通过卷积层处理输入。x = self.norm(x): 对处理后的特征图进行归一化。- 若
scale_shift存在,则应用缩放和偏移。 - 最后应用激活函数并返回结果。
- 构造函数 (
ConvNextBlock** 类**:- 构造函数 (
__init__):self.mlp: 如果time_emb_dim存在,则定义一个多层感知机(MLP)用于处理时间嵌入。self.ds_conv: 创建一个下采样卷积层,使用7x7卷积核和分组卷积。self.net: 定义一个序列网络,包含归一化、卷积和激活函数。self.res_conv: 若输入和输出维度不同,则创建一个1x1卷积以进行残差连接,否则使用身份变换。
- 前向传播 (
construct):- 首先对输入应用下采样卷积。
- 如果存在时间嵌入且MLP存在,计算条件嵌入并扩展其维度,随后与主特征图相加。
- 应用主网络结构,最后返回与残差卷积的输出相加的结果,增强特征的表达能力。
- 构造函数 (
使用场景:
Block和ConvNextBlock是深度学习模型中特征提取模块,常用于图像处理和生成任务。它们通过残差连接和归一化层提高了训练稳定性和模型性能,特别在处理高维特征时。
Attention模块
接下来,我们定义Attention模块,DDPM作者将其添加到卷积块之间。Attention是著名的Transformer架构(Vaswani et al., 2017),在人工智能的各个领域都取得了巨大的成功,从NLP到蛋白质折叠。Phil Wang使用了两种注意力变体:一种是常规的multi-head self-attention(如Transformer中使用的),另一种是LinearAttention(Shen et al., 2018),其时间和内存要求在序列长度上线性缩放,而不是在常规注意力中缩放。 要想对Attention机制进行深入的了解,请参照Jay Allamar的精彩的博文。
class Attention(nn.Cell):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__() # 初始化父类
self.scale = dim_head ** -0.5 # 缩放因子,避免点积过大
self.heads = heads # 头的数量
hidden_dim = dim_head * heads # 隐藏维度,即每个头的维度乘以头的数量
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False) # 定义1x1卷积用于生成Q、K、V
self.to_out = nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True) # 定义1x1卷积用于输出
self.map = ops.Map() # 创建Map操作
self.partial = ops.Partial() # 创建Partial操作
def construct(self, x):
b, _, h, w = x.shape # 获取输入特征图的形状
qkv = self.to_qkv(x).chunk(3, 1) # 通过卷积层生成Q、K、V
q, k, v = self.map(self.partial(rearrange, self.heads), qkv) # 对Q、K、V进行重排以适应多头
q = q * self.scale # 缩放Q
# 计算相似度
sim = ops.bmm(q.swapaxes(2, 3), k) # 计算Q和K的点积
attn = ops.softmax(sim, axis=-1) # 对相似度进行softmax归一化以获得注意力权重
# 计算输出
out = ops.bmm(attn, v.swapaxes(2, 3)) # 根据注意力权重加权V
out = out.swapaxes(-1, -2).reshape((b, -1, h, w)) # 重新排列输出形状
return self.to_out(out) # 通过输出卷积层返回最终结果
class LayerNorm(nn.Cell):
def __init__(self, dim):
super().__init__() # 初始化父类
self.g = Parameter(initializer('ones', (1, dim, 1, 1)), name='g') # 初始化缩放参数g
def construct(self, x):
eps = 1e-5 # 防止除0错误的微小值
var = x.var(1, keepdims=True) # 计算方差
mean = x.mean(1, keep_dims=True) # 计算均值
# 进行层归一化
return (x - mean) * ops.rsqrt((var + eps)) * self.g # 归一化并应用缩放
class LinearAttention(nn.Cell):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__() # 初始化父类
self.scale = dim_head ** -0.5 # 缩放因子
self.heads = heads # 头的数量
hidden_dim = dim_head * heads # 隐藏维度
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False) # 生成Q、K、V的卷积层
self.to_out = nn.SequentialCell( # 定义输出模块
nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True), # 输出卷积层
LayerNorm(dim) # 层归一化
)
self.map = ops.Map() # 创建Map操作
self.partial = ops.Partial() # 创建Partial操作
def construct(self, x):
b, _, h, w = x.shape # 获取输入特征图的形状
qkv = self.to_qkv(x).chunk(3, 1) # 通过卷积生成Q、K、V
q, k, v = self.map(self.partial(rearrange, self.heads), qkv) # 重排以适应多头
q = ops.softmax(q, -2) # 对Q进行softmax
k = ops.softmax(k, -1) # 对K进行softmax
q = q * self.scale # 缩放Q
v = v / (h * w) # 对V进行归一化
# 计算上下文
context = ops.bmm(k, v.swapaxes(2, 3)) # 计算K和V的加权组合
# 计算输出
out = ops.bmm(context.swapaxes(2, 3), q) # 根据Q计算输出
out = out.reshape((b, -1, h, w)) # 重新排列输出形状
return self.to_out(out) # 返回最终输出
解析:
Attention** 类**:- 构造函数 (
__init__):self.scale: 计算缩放因子,防止点积的值过大。self.heads: 定义注意力头的数量。hidden_dim: 每个头的维度乘以头的数量。self.to_qkv: 通过1x1卷积层生成查询(Q)、键(K)、值(V)。self.to_out: 通过1x1卷积层将输出映射回原始维度。
- 前向传播 (
construct):- 获取输入的形状并生成Q、K、V。
- 通过
map和partial操作重排Q、K、V。 - 计算相似度并获得注意力权重。
- 根据注意力权重加权V,最后返回通过输出卷积层处理的结果。
- 构造函数 (
LayerNorm** 类**:- 构造函数 (
__init__):- 初始化一个可学习的缩放参数
g。
- 初始化一个可学习的缩放参数
- 前向传播 (
construct):- 计算输入的均值和方差,并使用其进行层归一化处理,最后返回归一化后的结果。
- 构造函数 (
LinearAttention** 类**:- 构造函数 (
__init__):- 与
Attention类类似,但在这里应用了不同的处理步骤和结构。 self.to_out包含卷积和层归一化的组合。
- 与
- 前向传播 (
construct):- 同样获取输入的形状并生成Q、K、V。
- 计算Q和K的softmax值,缩放Q并归一化V。
- 计算上下文并根据Q计算输出,最后返回通过输出模块处理的结果。
- 构造函数 (
使用场景:
- Attention 和 LinearAttention:用于构建注意力机制,在图像处理、自然语言处理等领域中广泛应用,可以帮助模型关注输入数据中的重要特征。
- LayerNorm:可用于标准化神经网络中的激活值,提高训练的稳定性和性能。
组归一化
DDPM作者将U-Net的卷积/注意层与群归一化(Wu et al., 2018)。下面,我们定义一个PreNorm类,将用于在注意层之前应用groupnorm。
class PreNorm(nn.Cell):
def __init__(self, dim, fn):
super().__init__() # 初始化父类
self.fn = fn # 保存传入的函数(通常是某种操作或模块)
self.norm = nn.GroupNorm(1, dim) # 定义组归一化层,适用于输入特征的归一化
def construct(self, x):
x = self.norm(x) # 对输入x进行归一化
return self.fn(x) # 返回经过函数fn处理后的结果
解析:
- 构造函数 (
__init__):self.fn: 将传入的函数或操作保存为实例变量。这个函数通常是在归一化之后应用于输入的某种操作(如卷积、注意力等)。self.norm: 创建一个组归一化层,通常用于处理小批量的输入数据,能够有效地减少内部协变量偏移。
- 前向传播 (
construct):x = self.norm(x): 对输入x应用组归一化,确保每个通道的均值和方差一致,从而提高模型训练的稳定性。return self.fn(x): 将归一化后的输入传递给保存的函数fn,并返回其输出。
使用场景:
- PreNorm 常用于对神经网络中的某些层(如注意力机制、卷积层等)进行标准化处理。通过在应用这些操作之前进行归一化,可以提高模型的收敛速度和性能,特别是在深度学习模型中。
条件U-Net
我们已经定义了所有的构建块(位置嵌入、ResNet/ConvNeXT块、Attention和组归一化),现在需要定义整个神经网络了。请记住,网络 ϵθ(xt,t) 的工作是接收一批噪声图像+噪声水平,并输出添加到输入中的噪声。
更具体的: 网络获取了一批(batch_size, num_channels, height, width)形状的噪声图像和一批(batch_size, 1)形状的噪音水平作为输入,并返回(batch_size, num_channels, height, width)形状的张量。
网络构建过程如下:
- 首先,将卷积层应用于噪声图像批上,并计算噪声水平的位置
- 接下来,应用一系列下采样级。每个下采样阶段由2个ResNet/ConvNeXT块 + groupnorm + attention + 残差连接 + 一个下采样操作组成
- 在网络的中间,再次应用ResNet或ConvNeXT块,并与attention交织
- 接下来,应用一系列上采样级。每个上采样级由2个ResNet/ConvNeXT块+ groupnorm + attention + 残差连接 + 一个上采样操作组成
- 最后,应用ResNet/ConvNeXT块,然后应用卷积层
最终,神经网络将层堆叠起来,就像它们是乐高积木一样(但重要的是了解它们是如何工作的)。
class Unet(nn.Cell):
def __init__(
self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
with_time_emb=True,
convnext_mult=2,
):
super().__init__() # 初始化父类
self.channels = channels # 输入通道数
init_dim = default(init_dim, dim // 3 * 2) # 初始化维度,根据条件设置
# 定义初始卷积层
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True)
# 计算每个分辨率的维度
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:])) # 输入输出维度对
block_klass = partial(ConvNextBlock, mult=convnext_mult) # 定义卷积块
# 如果需要时间嵌入
if with_time_emb:
time_dim = dim * 4 # 定义时间嵌入维度
self.time_mlp = nn.SequentialCell(
SinusoidalPositionEmbeddings(dim), # 使用正弦位置嵌入
nn.Dense(dim, time_dim), # 全连接层
nn.GELU(), # 激活函数
nn.Dense(time_dim, time_dim), # 另一全连接层
)
else:
time_dim = None
self.time_mlp = None
self.downs = nn.CellList([]) # 下采样模块列表
self.ups = nn.CellList([]) # 上采样模块列表
num_resolutions = len(in_out) # 计算分辨率数量
# 构建下采样模块
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1) # 判断是否为最后一个分辨率
self.downs.append(
nn.CellList(
[
block_klass(dim_in, dim_out, time_emb_dim=time_dim), # 第一个卷积块
block_klass(dim_out, dim_out, time_emb_dim=time_dim), # 第二个卷积块
Residual(PreNorm(dim_out, LinearAttention(dim_out))), # 残差连接和归一化注意力
Downsample(dim_out) if not is_last else nn.Identity(), # 分辨率不变时使用身份映射
]
)
)
mid_dim = dims[-1] # 中间层的维度
# 中间模块
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim))) # 中间注意力块
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
# 构建上采样模块
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
is_last = ind >= (num_resolutions - 1) # 判断是否为最后一个分辨率
self.ups.append(
nn.CellList(
[
block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim), # 第一个卷积块,通道数加倍
block_klass(dim_in, dim_in, time_emb_dim=time_dim), # 第二个卷积块
Residual(PreNorm(dim_in, LinearAttention(dim_in))), # 残差连接和归一化注意力
Upsample(dim_in) if not is_last else nn.Identity(), # 分辨率不变时使用身份映射
]
)
)
out_dim = default(out_dim, channels) # 设置输出维度
self.final_conv = nn.SequentialCell( # 最终卷积模块
block_klass(dim, dim), # 卷积块
nn.Conv2d(dim, out_dim, 1) # 输出卷积
)
def construct(self, x, time):
x = self.init_conv(x) # 通过初始卷积处理输入
t = self.time_mlp(time) if exists(self.time_mlp) else None # 处理时间嵌入
h = [] # 保存下采样阶段的特征
# 下采样阶段
for block1, block2, attn, downsample in self.downs:
x = block1(x, t) # 第一个卷积块
x = block2(x, t) # 第二个卷积块
x = attn(x) # 注意力模块
h.append(x) # 保存特征
x = downsample(x) # 下采样操作
# 中间层处理
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
len_h = len(h) - 1 # 获取特征列表的长度
# 上采样阶段
for block1, block2, attn, upsample in self.ups:
x = ops.concat((x, h[len_h]), 1) # 拼接上下文特征
len_h -= 1
x = block1(x, t) # 第一个卷积块
x = block2(x, t) # 第二个卷积块
x = attn(x) # 注意力模块
x = upsample(x) # 上采样操作
return self.final_conv(x) # 返回最终输出
解析:
Unet** 类**:- 构造函数 (
__init__):self.channels: 输入图像的通道数。init_dim: 初始卷积层的输出通道数,默认为输入维度的二分之一。self.init_conv: 定义初始卷积层,用于处理输入图像,以获取初始特征。dims: 根据dim_mults计算每个分辨率的维度。in_out: 创建输入输出维度的对。block_klass: 定义卷积块的部分应用,便于后续使用。self.time_mlp: 如果需要时间嵌入,定义处理时间信息的全连接神经网络。self.downs和self.ups: 创建下采样和上采样模块的列表。- 通过循环构建下采样和上采样模块,使用卷积块、残差连接、注意力机制和下/上采样操作。
self.final_conv: 定义最终输出卷积层,将特征映射到输出通道。
- 构造函数 (
- 前向传播 (
construct):x = self.init_conv(x): 通过初始卷积层处理输入。t = self.time_mlp(time): 处理时间嵌入,如果存在的话。h = []: 初始化一个列表,用来存储下采样阶段的特征。- 下采样阶段:对每个下采样模块依次进行操作,保存特征并进行下采样。
- 中间层处理:通过中间模块进行特征处理。
- 上采样阶段:逆序遍历上采样模块,拼接特征图并进行处理。
return self.final_conv(x): 返回最终卷积处理后的输出。
使用场景:
- Unet 是一种经典的图像分割网络架构,广泛用于医学图像处理、图像生成等任务。通过下采样和上采样过程,U-Net 能够有效地提取多尺度特征,并且结合了高分辨率特征图,具有良好的分割精度。该实现还结合了时间嵌入和注意力机制,使得模型可以处理动态或时序数据。
正向扩散
我们已经知道正向扩散过程在多个时间步长中,从实际分布逐渐向图像添加噪声,根据差异计划进行正向扩散。最初的DDPM作者采用了线性时间表:
- 我们将正向过程方差设置为常数,从线性增加到。
- 但是,它在(Nichol et al., 2021)中表明,当使用余弦调度时,可以获得更好的结果。
下面,我们定义了时间步的时间表。
def linear_beta_schedule(timesteps):
beta_start = 0.0001 # 设置 beta 的起始值
beta_end = 0.02 # 设置 beta 的结束值
return np.linspace(beta_start, beta_end, timesteps).astype(np.float32) # 生成从 beta_start 到 beta_end 的线性间隔数组
解析:
- 功能:
- 该函数用于生成一个线性渐变的 beta 值序列,通常在某些算法中需要使用到 beta 值(例如,扩散模型中)。
- 参数:
timesteps: 表示生成多少个 beta 值,通常对应于算法的时间步数或迭代次数。
- 变量:
beta_start: beta 值的起始值,设定为 0.0001。beta_end: beta 值的结束值,设定为 0.02。
- 返回值:
- 使用
np.linspace函数生成一个从beta_start到beta_end的线性间隔数组,长度为timesteps。最后通过.astype(np.float32)将生成的数组转换为浮点数类型,以确保数据类型一致。
- 使用
使用场景:
- linear_beta_schedule 函数常用于机器学习模型中,特别是在扩散模型中,用于生成每个时间步的噪声强度(β),以便在训练过程中逐渐增加噪声,使模型能够学会从噪声中恢复原始数据。
首先,让我们使用 T=200𝑇=200 时间步长的线性计划,并定义我们需要的 βtβ𝑡 中的各种变量,例如方差 α¯t𝛼¯𝑡 的累积乘积。下面的每个变量都只是一维张量,存储从 t𝑡 到 T𝑇 的值。重要的是,我们还定义了extract函数,它将允许我们提取一批适当的 t𝑡 索引。
# 扩散200步
timesteps = 200 # 设置扩散的时间步数
# 定义 beta schedule
betas = linear_beta_schedule(timesteps=timesteps) # 生成 beta 值序列
# 定义 alphas
alphas = 1. - betas # 计算 alphas 值
alphas_cumprod = np.cumprod(alphas, axis=0) # 计算 alphas 的累积乘积
alphas_cumprod_prev = np.pad(alphas_cumprod[:-1], (1, 0), constant_values=1) # 填充累积乘积
# 计算相关变量
sqrt_recip_alphas = Tensor(np.sqrt(1. / alphas)) # 计算每个 alpha 的平方根倒数
sqrt_alphas_cumprod = Tensor(np.sqrt(alphas_cumprod)) # 计算累积乘积的平方根
sqrt_one_minus_alphas_cumprod = Tensor(np.sqrt(1. - alphas_cumprod)) # 计算 (1 -累积乘积) 的平方根
# 计算 q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod) # 后验方差计算
# 计算 p2_loss_weight
p2_loss_weight = (1 + alphas_cumprod / (1 - alphas_cumprod)) ** -0. # 计算 p2_loss_weight
p2_loss_weight = Tensor(p2_loss_weight) # 转换为 Tensor
def extract(a, t, x_shape):
b = t.shape[0] # 获取 t 的第一个维度大小
out = Tensor(a).gather(t, -1) # 根据 t 的索引提取 a 中的元素
return out.reshape(b, *((1,) * (len(x_shape) - 1))) # 调整输出形状
解析:
- 扩散步数设置:
timesteps = 200: 定义扩散过程的时间步长为 200。
- beta 生成:
betas = linear_beta_schedule(timesteps=timesteps): 调用之前定义的函数生成 beta 值序列,用于后续计算。
- alphas 计算:
alphas = 1. - betas: 根据 beta 计算对应的 alphas 值。alphas_cumprod = np.cumprod(alphas, axis=0): 计算 alphas 的累积乘积,用于后续的噪声消除计算。alphas_cumprod_prev = np.pad(alphas_cumprod[:-1], (1, 0), constant_values=1): 对累积乘积进行填充,以便后续计算后验方差。
- 变量计算:
sqrt_recip_alphas: 计算每个 alphas 的平方根倒数,方便后续的计算。sqrt_alphas_cumprod: 计算 alphas 的累积乘积的平方根。sqrt_one_minus_alphas_cumprod: 计算(1 - alphas_cumprod)的平方根。
- 后验方差计算:
posterior_variance: 计算扩散模型中状态转移的后验方差,用于推断时的噪声水平。
- p2_loss_weight 计算:
p2_loss_weight: 计算损失权重,根据 alphas 的累积乘积和逆累积乘积的关系,调整模型的学习过程。
extract** 函数**:extract(a, t, x_shape): 定义了一个提取函数,用于根据输入的索引t从数组a中提取相应的元素。这个函数在处理不同时间步的特征时非常有用。b = t.shape[0]: 获取索引张量的大小。out = Tensor(a).gather(t, -1): 根据索引 t 从 a 中提取元素。return out.reshape(b, *((1,) * (len(x_shape) - 1))): 调整输出的形状以适应后续处理。
使用场景:
- 该代码片段通常会出现在扩散模型的实现中,特别是在图像生成和图像重建等任务中,利用扩散过程逐步恢复数据。在这个过程中,beta 和 alpha 的调度对于控制噪声的引入和去除至关重要。
extract函数则用于在不同时间步取出特征,以便进行训练或推理。
我们将用猫图像说明如何在扩散过程的每个时间步骤中添加噪音。
# 下载猫猫图像
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/image_cat.zip' # 定义猫猫图像的下载链接
path = download(url, './', kind="zip", replace=True) # 下载图像压缩文件到当前目录,指定文件类型为 zip,并允许覆盖
解析:
- 下载链接:
url: 定义了猫猫图像的压缩文件的网络链接。
- 下载函数:
download(url, './', kind="zip", replace=True): 调用download函数进行文件下载。url: 指向要下载的文件的链接。'./': 指定下载文件的保存路径,这里是当前目录。kind="zip": 指定文件的类型为 zip,表明下载的文件是一个压缩文件。replace=True: 表示如果文件已存在,则允许覆盖。
使用场景:
- 该代码段用于从指定的网络地址下载包含猫猫图像的压缩文件。这在数据预处理和数据集准备的过程中非常常见,尤其是在进行计算机视觉任务时,需要获取和使用相关图像数据集。下载后可以解压并使用这些图像进行模型训练或测试。
from PIL import Image # 导入 Pillow 库中的 Image 模块
# 打开指定路径的图像
image = Image.open('./image_cat/jpg/000000039769.jpg') # 加载猫猫图像
# 设置基础宽度
base_width = 160 # 定义要调整的图像宽度
# 调整图像大小
image = image.resize((base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))))
# 根据基础宽度计算新的高度,保持图像的纵横比
# 显示调整后的图像
image.show() # 显示图像
解析:
- 导入库:
from PIL import Image: 从 PIL(Python Imaging Library)库导入 Image 模块,以便进行图像处理。
- 打开图像:
image = Image.open('./image_cat/jpg/000000039769.jpg'): 使用Image.open()方法打开指定路径的图像文件。
- 设置基础宽度:
base_width = 160: 定义要调整的图像宽度为 160 像素。
- 调整图像大小:
image = image.resize(...): 调用resize方法调整图像的大小。(base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))):base_width: 设置的新宽度。int(float(image.size[1]) * float(base_width / float(image.size[0]))): 计算新的高度,以保持原图的纵横比。image.size[0]为原图的宽度,image.size[1]为原图的高度。- 通过比例计算获取新高度,确保图像不会变形。
- 显示图像:
image.show(): 调用show()方法在默认图像查看器中显示调整后的图像。
使用场景:
- 该代码段用于加载、调整大小并显示一张猫猫图像。这在图像预处理阶段非常常见,尤其是在需要统一输入图像尺寸以供计算机视觉模型处理时。调整图像大小时保持纵横比有助于避免图像失真。
噪声被添加到mindspore张量中,而不是Pillow图像。我们将首先定义图像转换,允许我们从PIL图像转换到mindspore张量(我们可以在其上添加噪声),反之亦然。
这些转换相当简单:我们首先通过除以255来标准化图像(使它们在 [0,1] 范围内),然后确保它们在 [−1,1]范围内。DPPM论文中有介绍到:
假设图像数据由 0,1,…,255 中的整数组成,线性缩放为 [−1,1] , 这确保了神经网络反向过程在从标准正常先验 p(xT)开始的一致缩放输入上运行。
from mindspore.dataset import ImageFolderDataset # 导入 ImageFolderDataset 用于处理图像数据集
from mindspore.dataset.vision import Resize, CenterCrop, ToTensor, RandomHorizontalFlip # 导入图像变换函数
from mindspore.common import Inter # 导入插值方法
from multiprocessing import cpu_count # 导入 CPU 核心数计算
# 设置图像尺寸
image_size = 128 # 定义目标图像的大小
# 定义图像变换序列
transforms = [
Resize(image_size, Inter.BILINEAR), # 将图像调整到指定大小,使用双线性插值
CenterCrop(image_size), # 中心裁剪图像
ToTensor(), # 将图像转换为张量
lambda t: (t * 2) - 1 # 将像素值从 [0, 1] 归一化到 [-1, 1]
]
# 设置数据集路径
path = './image_cat' # 定义图像数据集的路径
# 创建图像数据集
dataset = ImageFolderDataset(dataset_dir=path, num_parallel_workers=cpu_count(),
extensions=['.jpg', '.jpeg', '.png', '.tiff'], # 指定支持的文件扩展名
num_shards=1, shard_id=0, shuffle=False, decode=True) # 定义数据集属性
# 项目只选择图像列
dataset = dataset.project('image') # 只选择图像数据
# 插入随机水平翻转变换
transforms.insert(1, RandomHorizontalFlip()) # 在变换序列中插入随机水平翻转
# 应用变换并创建映射
dataset_1 = dataset.map(transforms, 'image') # 对图像应用变换
# 批处理数据集
dataset_2 = dataset_1.batch(1, drop_remainder=True) # 将数据集按批次处理,批大小为1,丢弃剩余数据
# 获取数据
x_start = next(dataset_2.create_tuple_iterator())[0] # 从数据集中获取一个批次的图像数据
print(x_start.shape) # 打印图像数据的形状
解析:
- 导入库:
- 导入
ImageFolderDataset用于构建图像数据集,导入相关的图像处理变换函数,如Resize,CenterCrop,ToTensor,RandomHorizontalFlip。
- 导入
- 图像尺寸设置:
image_size = 128: 定义最终输出图像的尺寸为 128 像素。
- 定义图像变换:
transforms: 包含若干图像处理步骤:Resize(image_size, Inter.BILINEAR): 调整图像大小,使用双线性插值。CenterCrop(image_size): 对图像进行中心裁剪,确保图像的中心部分被保留。ToTensor(): 将图像转换为 PyTorch 或 MindSpore 的张量格式。lambda t: (t * 2) - 1: 将像素值归一化,从原来的 [0, 1] 范围转换到 [-1, 1]。
- 创建数据集:
dataset = ImageFolderDataset(...): 创建一个图像文件夹数据集,指定目录和文件扩展名,以及其他参数如并行工作线程、是否打乱、是否解码等。
- 选择项目:
dataset = dataset.project('image'): 从数据集中选择图像列。可以选择要使用的列,通常是图像列和标签列。
- 添加随机水平翻转:
transforms.insert(1, RandomHorizontalFlip()): 在变换序列中插入随机水平翻转,以增强数据集的多样性。
- 应用变换:
dataset_1 = dataset.map(transforms, 'image'): 将定义的变换应用到数据集中的图像列。
- 批处理:
dataset_2 = dataset_1.batch(1, drop_remainder=True): 将变换后的数据集按批次转换,每个批次包含 1 张图像,丢弃无法形成完整批次的剩余数据。
- 获取数据:
x_start = next(dataset_2.create_tuple_iterator())[0]: 获取一个批次的图像数据。print(x_start.shape): 打印获取的图像数据的形状,帮助确认图像的维度和大小。
使用场景:
- 该代码段用于处理图像数据集,尤其是在计算机视觉任务中。通过加载图像、应用变换(如调整大小、裁剪和翻转)并生成批次,可以为模型训练或推理准备数据。数据增强(如随机翻转)可以提高模型的泛化能力。
我们还定义了反向变换,它接收一个包含 [−1,1]中的张量,并将它们转回 PIL 图像:
import numpy as np # 导入 NumPy 库用于数值操作
# 定义逆变换列表
reverse_transform = [
lambda t: (t + 1) / 2, # 将张量从 [-1, 1] 范围转换到 [0, 1]
lambda t: ops.permute(t, (1, 2, 0)), # 将张量从 CHW 格式转换到 HWC 格式
lambda t: t * 255., # 将张量的像素值从 [0, 1] 扩展到 [0, 255]
lambda t: t.asnumpy().astype(np.uint8), # 将张量转换为 NumPy 数组,并转换数据类型为 uint8
ToPIL() # 将 NumPy 数组转换为 PIL 图像格式
]
def compose(transform, x):
for d in transform: # 遍历变换列表中的每一个变换
x = d(x) # 应用变换到输入数据 x
return x # 返回经过所有变换处理后的数据
解析:
- 导入库:
import numpy as np: 导入 NumPy 库,用于数值计算和数组操作。
- 逆变换列表:
reverse_transform: 列表中包含一系列用于将图像张量转换回原始图像格式的变换。lambda t: (t + 1) / 2: 将张量从 [-1, 1] 范围转换到 [0, 1],这通常用于图像的标准化过程的逆过程。lambda t: ops.permute(t, (1, 2, 0)): 将张量的维度从通道高度宽(CHW)格式转换为高度宽通道(HWC)格式,以便于图像显示和处理。lambda t: t * 255.: 将张量中的像素值从 [0, 1] 乘以 255,扩展到 [0, 255] 的整数范围,这是图像的标准像素值范围。lambda t: t.asnumpy().astype(np.uint8): 将 MindSpore 的张量转换为 NumPy 数组,并将其数据类型转换为无符号 8 位整数(uint8),用于图像存储。ToPIL(): 将 NumPy 数组转换为 PIL 图像对象,以便于可视化和保存。
- 组合变换函数:
def compose(transform, x): 定义一个函数compose,接收变换列表和输入数据x。for d in transform: 遍历变换列表中的每个变换。x = d(x): 依次将每个变换应用到输入数据。return x: 返回经过所有变换处理后的数据。
使用场景:
- 该代码段用于定义图像数据的逆变换过程,通常在图像生成、模型推理或输出结果可视化时使用。通过将处理过的张量恢复到可视化格式,可以方便地查看生成的图像或预测结果。这些逆操作对于确保模型输出的可理解性和可用性至关重要。
让我们验证一下:
# 使用 compose 函数对 x_start[0] 进行逆变换
reverse_image = compose(reverse_transform, x_start[0]) # 将经过逆变换处理的图像赋值给 reverse_image
# 显示处理后的图像
reverse_image.show() # 调用 show 方法在默认图像查看器中显示逆变换后的图像
解析:
- 逆变换应用:
reverse_image = compose(reverse_transform, x_start[0]):- 调用
compose函数,传入逆变换列表reverse_transform和张量x_start[0]。 x_start[0]是之前从数据集中获取的图像张量。- 通过逆变换,将图像数据转换回可视化格式(如 PIL 图像)。
- 调用
- 显示图像:
reverse_image.show():- 调用
show()方法在默认的图像查看器中显示经过逆变换处理的图像。 - 这一步通常用于验证图像的处理结果,确保图像恢复成功且符合预期。
- 调用
使用场景:
- 该代码段通常用于将经过深度学习模型处理的图像(如生成或分类)转换回人类可读的形式。通过逆变换的步骤,确保可以将张量数据恢复为可以直接显示的图像格式。这在模型的推理阶段非常常见,尤其是用于可视化生成的图像、分析模型性能或展示结果时。
我们现在可以定义前向扩散过程,如本文所示:
def q_sample(x_start, t, noise=None):
# 如果没有提供噪声,则生成与 x_start 相同形状的随机噪声
if noise is None:
noise = randn_like(x_start) # 使用 randn_like 函数生成与 x_start 形状相同的随机噪声
# 计算噪声样本,结合输入 x_start 和噪声
return (extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start + # 提取并应用 sqrt_alphas_cumprod
extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise) # 提取并应用 sqrt_one_minus_alphas_cumprod
解析:
- 函数定义:
def q_sample(x_start, t, noise=None): 定义一个函数q_sample,接受三个参数:x_start: 输入张量,通常是初始图像或样本。t: 时间步或噪声调度的参数,用于控制噪声的添加程度。noise: 可选参数,如果没有提供,将生成默认的噪声。
- 噪声生成:
if noise is None:: 检查是否提供了噪声。noise = randn_like(x_start): 如果没有提供噪声,使用randn_like函数生成与x_start形状相同的随机噪声。randn_like函数生成标准正态分布的随机数。
- 计算噪声样本:
extract(sqrt_alphas_cumprod, t, x_start.shape): 使用extract函数从sqrt_alphas_cumprod中提取与时间步t相关的值,并根据x_start的形状进行适配。这一部分通常用于控制样本的保留程度。extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape): 从sqrt_one_minus_alphas_cumprod中提取与时间步t相关的值,这部分通常用于控制要添加的噪声的程度。- 最终返回的是将
x_start和噪声按比例混合后的结果。
使用场景:
- 该函数通常用于生成带有噪声的图像样本,尤其在扩散模型或生成对抗网络中。通过控制时间步
t,可以调整样本的噪声水平,从而在图像生成或数据增强过程中产生不同程度的模糊或干扰效果。这种方法在训练生成模型时非常有效,有助于模型学习更丰富的特征和数据结构。
让我们在特定的时间步长上测试它:
def get_noisy_image(x_start, t):
# 添加噪声
x_noisy = q_sample(x_start, t=t) # 调用 q_sample 函数生成带噪声的图像样本
# 转换为 PIL 图像
noisy_image = compose(reverse_transform, x_noisy[0]) # 使用 compose 函数将带噪声的张量转换为 PIL 图像
return noisy_image # 返回转换后的 PIL 图像
解析:
- 函数定义:
def get_noisy_image(x_start, t): 定义一个函数get_noisy_image,接受两个参数:x_start: 输入的初始图像张量,通常是模型的输出或输入样本。t: 时间步或噪声调度的参数,用于控制噪声的添加程度。
- 添加噪声:
x_noisy = q_sample(x_start, t=t):- 调用
q_sample函数,将输入图像x_start和时间步t作为参数,生成带有噪声的图像张量x_noisy。 - 这个步骤通过将噪声与初始图像进行混合,从而创建一个更复杂的、具有噪声特性的样本。
- 调用
- 转换为 PIL 图像:
noisy_image = compose(reverse_transform, x_noisy[0]):- 使用
compose函数,将带噪声的张量x_noisy[0](通常为第一个样本)转换为 PIL 图像格式,方便显示和保存。 - 通过逆变换步骤,将处理过的张量恢复为可视化格式。
- 使用
- 返回值:
return noisy_image: 返回生成的带噪声的 PIL 图像。
使用场景:
- 该函数用于在图像生成、图像处理或数据增强等任务中生成带有噪声的图像。这在训练深度学习模型时非常重要,尤其是在对抗性训练或扩散模型中,通过添加噪声可以帮助模型提升对不同输入的鲁棒性,并学习到更稳健的特征表示。生成的带噪声图像在可视化时也可以帮助开发者理解模型在处理图像时的行为。
# 设置时间步
t = Tensor([40]) # 创建一个包含时间步的张量 t,值为 40
# 调用 get_noisy_image 函数生成带噪声的图像
noisy_image = get_noisy_image(x_start, t) # 使用 x_start 和 t 作为参数生成带噪声的图像
# 打印生成的带噪声的图像
print(noisy_image) # 输出 noisy_image 对象的信息,以便于查看
# 显示生成的带噪声的图像
noisy_image.show() # 调用 show 方法,在默认图像查看器中显示生成的带噪声图像
解析:
- 设置时间步:
t = Tensor([40]):- 创建一个张量
t,其中包含一个值为 40。这通常表示在某个噪声调度中选择的时间步,控制噪声添加的程度。
- 创建一个张量
- 生成带噪声的图像:
noisy_image = get_noisy_image(x_start, t):- 调用
get_noisy_image函数,将x_start和t作为参数,生成带噪声的图像并将其赋值给noisy_image变量。
- 调用
- 打印图像信息:
print(noisy_image):- 打印
noisy_image对象的信息,通常用于调试和检查生成的图像数据类型、尺寸等元数据。
- 打印
- 显示图像:
noisy_image.show():- 调用
show()方法,在默认的图像查看器中显示生成的带噪声图像,使用户可以直观地查看处理结果。
- 调用
使用场景:
- 这段代码用于生成并显示带有特定噪声级别的图像,通常用于测试或验证深度学习模型的图像处理能力。设置时间步
t可以帮助研究人员理解不同噪声水平对生成图像质量的影响。通过显示图像,开发者可以快速评估模型在实际应用中的表现。
让我们为不同的时间步骤可视化此情况:
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 模块用于绘图
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs):
# 检查 imgs 的结构,如果不是嵌套列表,则将其转换为嵌套列表
if not isinstance(imgs[0], list):
imgs = [imgs]
num_rows = len(imgs) # 获取行数
num_cols = len(imgs[0]) + with_orig # 列数计算,如果需要显示原始图像则增加一列
_, axs = plt.subplots(figsize=(200, 200), nrows=num_rows, ncols=num_cols, squeeze=False) # 创建子图
for row_idx, row in enumerate(imgs):
# 如果需要显示原始图像,则在这一行的开头添加原始图像
row = [image] + row if with_orig else row
for col_idx, img in enumerate(row):
ax = axs[row_idx, col_idx] # 获取当前子图的轴
ax.imshow(np.asarray(img), **imshow_kwargs) # 将图像数据绘制到轴上
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[]) # 隐藏坐标轴刻度
if with_orig: # 如果需要显示原始图像,则设置标题
axs[0, 0].set(title='Original image')
axs[0, 0].title.set_size(8) # 设置标题字体大小
if row_title is not None: # 如果有行标题,设置每行的标签
for row_idx in range(num_rows):
axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout() # 调整布局,确保各个子图之间不会重叠
函数调用
plot([get_noisy_image(x_start, Tensor([t])) for t in [0, 50, 100, 150, 199]]) # 绘制不同时间步生成的带噪声图像
解析:
- 导入模块:
import matplotlib.pyplot as plt: 导入 matplotlib 库中的 pyplot 模块,用于数据的可视化。
- 函数定义:
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs): 定义一个函数plot,用于绘制图像。参数包括:imgs: 待绘制的图像列表。with_orig: 布尔值,指示是否包含原始图像。row_title: 可选,行标题列表。**imshow_kwargs: 其他可选参数,将传递给imshow函数。
- 处理输入图像:
if not isinstance(imgs[0], list): imgs = [imgs]: 如果输入的图像不是嵌套列表,则将其转换为嵌套列表的形式。num_rows和num_cols计算行数和列数,列数根据是否需要显示原始图像进行调整。
- 创建子图:
_, axs = plt.subplots(...): 创建一个指定大小的子图阵列。
- 绘制图像:
- 使用双重循环遍历每一行和每一列的图像,调用
ax.imshow(...)绘制图像,并设置坐标轴的刻度为不可见。
- 使用双重循环遍历每一行和每一列的图像,调用
- 设置标题和标签:
- 根据
with_orig设置原始图像的标题。 - 如果提供了
row_title,则为每一行的第一个子图设置行标签。
- 根据
- 调整布局:
plt.tight_layout(): 调整图像的布局,防止重叠。
使用场景:
- 该函数和调用语句用于可视化多个不同时间步生成的带噪声图像。通过将不同的噪声级别的图像绘制在一起,用户可以直观地比较这些图像之间的差异,从而分析噪声对图像的影响。这在图像生成、处理和增强等应用中非常有用。
这意味着我们现在可以定义给定模型的损失函数,如下所示:
def p_losses(unet_model, x_start, t, noise=None):
# 如果未提供噪声,则生成随机噪声
if noise is None:
noise = randn_like(x_start) # 使用 randn_like 函数生成与 x_start 形状相同的随机噪声
# 添加噪声到输入图像
x_noisy = q_sample(x_start=x_start, t=t, noise=noise) # 调用 q_sample 函数获取带噪声的图像
# 使用 UNet 模型预测噪声
predicted_noise = unet_model(x_noisy, t) # 将带噪声的图像和时间步传递给 UNet 模型,得到预测的噪声
# 计算损失
loss = nn.SmoothL1Loss()(noise, predicted_noise) # 使用平滑 L1 损失计算实际噪声和预测噪声之间的差异
loss = loss.reshape(loss.shape[0], -1) # 将损失重塑为 (batch_size, -1) 的形状
loss = loss * extract(p2_loss_weight, t, loss.shape) # 根据时间步 t 提取相应的权重,并与损失相乘
return loss.mean() # 返回损失的平均值
解析:
- 函数定义:
def p_losses(unet_model, x_start, t, noise=None): 定义一个名为p_losses的函数,接受以下参数:unet_model: 训练好的 UNet 模型,用于噪声预测。x_start: 输入的原始图像张量。t: 当前的时间步,控制噪声的添加。noise: 可选,实际的噪声张量。如果未提供,将生成随机噪声。
- 生成噪声:
if noise is None: noise = randn_like(x_start):- 如果没有提供噪声,则使用
randn_like函数生成与x_start形状相同的随机噪声张量。
- 如果没有提供噪声,则使用
- 添加噪声:
x_noisy = q_sample(x_start=x_start, t=t, noise=noise):- 调用
q_sample函数,将原始图像和噪声添加到图像上,生成带噪声的图像x_noisy。
- 调用
- 噪声预测:
predicted_noise = unet_model(x_noisy, t):- 将带噪声的图像
x_noisy和时间步t传递给 UNet 模型,得到预测的噪声predicted_noise。
- 将带噪声的图像
- 计算损失:
loss = nn.SmoothL1Loss()(noise, predicted_noise):- 使用
SmoothL1Loss(平滑 L1 损失)计算实际噪声与预测噪声之间的损失。平滑 L1 损失在处理异常值时更为稳健。
- 使用
loss = loss.reshape(loss.shape[0], -1):- 将损失重塑为二维数组,形状为 (batch_size, -1),以便后续处理。
loss = loss * extract(p2_loss_weight, t, loss.shape):- 使用
extract函数根据当前时间步t提取对应的权重p2_loss_weight,然后将其应用于损失,以调整损失的贡献。
- 使用
- 返回平均损失:
return loss.mean(): 返回损失的平均值,作为模型优化的目标。
使用场景:
- 该函数用于计算 UNet 模型在图像去噪任务中的损失,特别是在扩散模型中。通过输入带噪声的图像并预测噪声,可以评估模型的性能,并在训练过程中优化模型的参数。通过使用平滑 L1 损失,模型对噪声的预测更加稳健,适合处理图像生成和恢复等任务。
denoise_model将是我们上面定义的U-Net。我们将在真实噪声和预测噪声之间使用Huber损失。
数据准备与处理
在这里我们定义一个正则数据集。数据集可以来自简单的真实数据集的图像组成,如Fashion-MNIST、CIFAR-10或ImageNet,其中线性缩放为 [−1,1] 。
每个图像的大小都会调整为相同的大小。有趣的是,图像也是随机水平翻转的。根据论文内容:我们在CIFAR10的训练中使用了随机水平翻转;我们尝试了有翻转和没有翻转的训练,并发现翻转可以稍微提高样本质量。
本实验我们选用Fashion_MNIST数据集,我们使用download下载并解压Fashion_MNIST数据集到指定路径。此数据集由已经具有相同分辨率的图像组成,即28x28。
# 下载 MNIST 数据集
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip' # 数据集的 URL 地址
path = download(url, './', kind="zip", replace=True) # 调用 download 函数下载数据集,并指定保存路径和类型
解析:
- 设置数据集 URL:
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip':- 将 MNIST 数据集的下载链接存储在变量
url中。
- 将 MNIST 数据集的下载链接存储在变量
- 下载数据集:
path = download(url, './', kind="zip", replace=True):- 调用
download函数进行数据集的下载。 - 参数解释:
url: 下载的文件地址。'./': 指定将文件保存到当前工作目录。kind="zip": 指定下载文件的类型为 zip 格式。replace=True: 如果目标路径已存在同名文件,则替换它。
- 调用
使用场景:
- 这段代码用于下载 MNIST 数据集,该数据集常用于机器学习和深度学习的测试和训练。通过将数据集下载到本地,用户可以进一步处理和使用这些数据进行模型训练、评估和验证。该下载方法简单且高效,适合在各种环境中快速获取需要的数据集。
from mindspore.dataset import FashionMnistDataset # 从 MindSpore 数据集模块导入 FashionMnistDataset 类
# 定义图像相关参数
image_size = 28 # 图像的大小
channels = 1 # 图像的通道数,灰度图为1
batch_size = 16 # 每个批次的样本数量
# 设置数据集目录
fashion_mnist_dataset_dir = "./dataset" # 指定 Fashion MNIST 数据集的存储目录
# 创建 Fashion MNIST 数据集
dataset = FashionMnistDataset(
dataset_dir=fashion_mnist_dataset_dir, # 数据集目录
usage="train", # 使用训练集
num_parallel_workers=cpu_count(), # 设置并行工作进程的数量
shuffle=True, # 进行洗牌以增加数据的随机性
num_shards=1, # 设置分片数,1表示不进行分片
shard_id=0 # 当前分片的 ID
)
解析:
- 导入数据集模块:
from mindspore.dataset import FashionMnistDataset: 从 MindSpore 的数据集模块导入FashionMnistDataset类,用于加载 Fashion MNIST 数据集。
- 定义图像相关参数:
image_size = 28: 设置图像的边长为 28 像素(Fashion MNIST 图像均为 28x28)。channels = 1: 设置图像的通道数为 1,表示这些图像为灰度图。batch_size = 16: 设置每个训练批次的样本数量为 16。
- 设置数据集目录:
fashion_mnist_dataset_dir = "./dataset": 指定 Fashion MNIST 数据集的存储目录为当前工作目录下的dataset文件夹。
- 创建 Fashion MNIST 数据集:
dataset = FashionMnistDataset(...):dataset_dir=fashion_mnist_dataset_dir: 指定上面定义的数据集目录。usage="train": 指定使用训练集。num_parallel_workers=cpu_count(): 设定并行处理的工作进程数量,通常使用 CPU 核心数来加速数据读取。shuffle=True: 数据将被随机打乱,以增加训练的随机性,避免模型过拟合。num_shards=1: 指定数据集分片的数量,1表示不进行分片。shard_id=0: 指定当前分片的 ID,适用于分布式训练。
使用场景:
- 该代码段用于加载 Fashion MNIST 数据集,为深度学习模型的训练准备数据。通过使用 MindSpore 的数据集模块,用户可以方便地获取和处理数据,并在训练过程中利用多进程加速数据的加载,有助于提高训练效率。Fashion MNIST 数据集是一种常用的图像分类数据集,适合用于模型的训练和评估。
接下来,我们定义一个transform操作,将在整个数据集上动态应用该操作。该操作应用一些基本的图像预处理:随机水平翻转、重新调整,最后使它们的值在 [−1,1] 范围内。
# 定义数据转换操作
transforms = [
RandomHorizontalFlip(), # 随机水平翻转图像
ToTensor(), # 将图像转换为张量
lambda t: (t * 2) - 1 # 将像素值范围从 [0, 1] 转换到 [-1, 1]
]
# 对数据集进行处理
dataset = dataset.project('image') # 提取数据集中 'image' 字段
dataset = dataset.shuffle(64) # 随机打乱数据集,缓冲区大小为 64
dataset = dataset.map(transforms, 'image') # 对 'image' 字段应用转换操作
dataset = dataset.batch(16, drop_remainder=True) # 将数据集分批,每批 16 个样本,丢弃不完整批次
解析:
- 定义数据转换操作:
transforms = [...]: 创建一个包含多个数据转换操作的列表。RandomHorizontalFlip(): 随机水平翻转图像,有助于增加数据的多样性,减少模型对特定方向的依赖。ToTensor(): 将 PIL 图像或 NumPy 数组转换为 MindSpore 的张量格式,便于后续处理和模型输入。lambda t: (t * 2) - 1: 使用 Lambda 函数将图像的像素值范围从 [0, 1] 转换到 [-1, 1],这个转换在某些模型中有助于更好地训练。
- 对数据集进行处理:
dataset = dataset.project('image'):- 从数据集中提取出 ‘image’ 字段,准备对图像进行后续处理。
dataset = dataset.shuffle(64):- 随机打乱数据集,使用缓冲区大小为 64。这意味着在打乱过程中将会使用最近的 64 个样本来进行打乱,增加随机性。
dataset = dataset.map(transforms, 'image'):- 对提取的 ‘image’ 字段应用定义的转换操作,处理图像数据。
dataset = dataset.batch(16, drop_remainder=True):- 将数据集分批,每批包含 16 个样本。如果最后一个批次的样本少于 16 个,则丢弃这个不完整的批次,这样可以确保每个批次的大小一致,方便模型训练。
使用场景:
- 这段代码用于预处理从 Fashion MNIST 数据集中加载的图像数据,以便于输入到深度学习模型进行训练。通过随机翻转和张量转换,增强了数据的多样性并准备了适合模型输入的格式。批处理操作确保了每个训练步骤都有一致的数据量,提高了训练效率。这种预处理方式在图像分类任务中非常常见,有助于提升模型的性能和泛化能力。
x = next(dataset.create_dict_iterator())
print(x.keys())
采样
由于我们将在训练期间从模型中采样(以便跟踪进度),我们定义了下面的代码。采样在本文中总结为算法2:

从扩散模型生成新图像是通过反转扩散过程来实现的:我们从T𝑇开始,我们从高斯分布中采样纯噪声,然后使用我们的神经网络逐渐去噪(使用它所学习的条件概率),直到我们最终在时间步t=0结束。如上图所示,我们可以通过使用我们的噪声预测器插入平均值的重新参数化,导出一个降噪程度较低的图像 xt−1。请注意,方差是提前知道的。
理想情况下,我们最终会得到一个看起来像是来自真实数据分布的图像。
下面的代码实现了这一点。
def p_sample(model, x, t, t_index):
# 从模型中提取当前时间步的 beta 值
betas_t = extract(betas, t, x.shape)
# 提取 sqrt(1 - α) 的累积乘积
sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)
# 提取 sqrt(1 / α) 的值
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# 计算模型的均值
model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)
if t_index == 0:
return model_mean # 在最后一个时间步返回模型均值
# 提取后验方差
posterior_variance_t = extract(posterior_variance, t, x.shape)
noise = randn_like(x) # 生成与输入相同形状的随机噪声
return model_mean + ops.sqrt(posterior_variance_t) * noise # 返回加入噪声的均值
def p_sample_loop(model, shape):
b = shape[0] # 获取批次大小
img = randn(shape, dtype=None) # 从纯噪声初始化图像
imgs = [] # 存储生成的图像
# 反向循环时间步进行采样
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = p_sample(model, img, ms.numpy.full((b,), i, dtype=mstype.int32), i) # 进行一步采样
imgs.append(img.asnumpy()) # 将生成的张量转换为 NumPy 数组并存储
return imgs # 返回所有生成的图像
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size)) # 调用 p_sample_loop 函数进行采样
解析:
- p_sample 函数:
p_sample(model, x, t, t_index):- 目的: 在给定的时间步中生成图像。
- 参数:
model: 使用的生成模型。x: 当前的图像张量(通常是噪声)。t: 当前采样的时间步。t_index: 当前时间步的索引。
- 步骤:
- 提取当前时间步的 beta 值、累积乘积的平方根和反向 alpha 的平方根。
- 计算模型的输出均值。
- 如果当前时间步是最后一步 (t_index == 0),直接返回模型均值。
- 否则,提取后验方差,生成噪声,并返回带噪声的均值。
- p_sample_loop 函数:
p_sample_loop(model, shape):- 目的: 根据给定的形状生成图像序列。
- 参数:
model: 使用的生成模型。shape: 输出图像的形状。
- 步骤:
- 从随机噪声开始初始化图像。
- 使用循环反向迭代时间步,调用
p_sample函数进行逐步生成图像。 - 将生成的图像保存为 NumPy 数组,以便后续处理。
- sample 函数:
sample(model, image_size, batch_size=16, channels=3):- 目的: 简化生成图像的调用,提供默认参数。
- 参数:
model: 使用的生成模型。image_size: 生成图像的大小。batch_size: 每次生成的图像数量。channels: 图像的通道数(默认为 3,即 RGB 图像)。
- 步骤: 调用
p_sample_loop进行图像生成。
使用场景:
- 这段代码实现了基于扩散模型的图像生成过程。通过在多个时间步上进行逐步生成,利用模型来反向生成数据,从噪声开始到最终输出生成的图像。这种方法在生成对抗网络(GANs)和其他生成模型中非常有效,并且适用于图像合成、风格迁移等任务。可以用于生成高质量的图像数据,尤其在计算机视觉领域具有广泛应用。
请注意,上面的代码是原始实现的简化版本。
训练过程
下面,我们开始训练吧!
# 定义动态学习率
lr = nn.cosine_decay_lr(
min_lr=1e-7, # 最小学习率
max_lr=1e-4, # 最大学习率
total_step=10 * 3750, # 总步数,10个epoch,每个epoch 3750步
step_per_epoch=3750, # 每个epoch的步数
decay_epoch=10 # 衰减的epoch数
)
# 定义 Unet模型
unet_model = Unet(
dim=image_size, # 输入图像的大小
channels=channels, # 图像的通道数
dim_mults=(1, 2, 4,) # U-Net中每一层的通道数的倍增因子
)
name_list = [] # 用于存储参数名称
for (name, par) in list(unet_model.parameters_and_names()):
name_list.append(name) # 添加参数名称到列表
i = 0
for item in list(unet_model.trainable_params()):
item.name = name_list[i] # 为训练参数设置名称
i += 1
# 定义优化器
optimizer = nn.Adam(unet_model.trainable_params(), learning_rate=lr) # Adam优化器
loss_scaler = DynamicLossScaler(65536, 2, 1000) # 动态损失缩放器
# 定义前向过程
def forward_fn(data, t, noise=None):
loss = p_losses(unet_model, data, t, noise) # 计算损失
return loss
# 计算梯度
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False) # 获取损失和梯度
# 梯度更新
def train_step(data, t, noise):
loss, grads = grad_fn(data, t, noise) # 计算损失和梯度
optimizer(grads) # 更新参数
return loss # 返回损失
解析:
- 定义动态学习率:
lr = nn.cosine_decay_lr(...):- 使用余弦衰减学习率策略,设置最小学习率和最大学习率。
total_step: 训练总步数。step_per_epoch: 每个 epoch 的步数。decay_epoch: 学习率衰减的 epoch 数。
- 定义 Unet 模型:
unet_model = Unet(...):- 创建一个 U-Net 模型实例,指定输入图像的维度(
dim)、通道数(channels)和通道倍增因子(dim_mults)。
- 创建一个 U-Net 模型实例,指定输入图像的维度(
- 设置参数名称:
- 通过遍历模型参数,为每个可训练参数设置名称,以便在调试或模型可视化时跟踪这些参数。
- 定义优化器:
optimizer = nn.Adam(...):- 使用 Adam 优化器,传入可训练参数和学习率。
loss_scaler = DynamicLossScaler(...):- 创建一个动态损失缩放器,用于处理混合精度训练,防止数值下溢或上溢。
- 定义前向过程:
forward_fn(data, t, noise):- 计算损失的前向函数,调用
p_losses函数来计算损失。
- 计算损失的前向函数,调用
- 计算梯度:
grad_fn = ms.value_and_grad(...):- 使用 MindSpore 的
value_and_grad函数,获取损失和梯度的计算函数。
- 使用 MindSpore 的
- 梯度更新:
train_step(data, t, noise):- 在训练步骤中,计算损失和梯度,并使用优化器更新模型参数,返回计算得到的损失。
使用场景:
- 该代码段用于设置和训练一个 U-Net 模型,通常应用于图像生成、分割或恢复任务。动态学习率和损失缩放的使用可以帮助模型更有效地训练,同时避免数值问题。通过定义前向过程和梯度更新步骤,能够在训练循环中使用,适合用于大规模数据集的训练过程。
import time # 导入时间库
epochs = 10 # 设置训练的总周期数
for epoch in range(epochs):
begin_time = time.time() # 记录开始时间
for step, batch in enumerate(dataset.create_tuple_iterator()):
unet_model.set_train() # 设置模型为训练模式
batch_size = batch[0].shape[0] # 获取当前批次的大小
t = randint(0, timesteps, (batch_size,), dtype=ms.int32) # 随机生成时间步
noise = randn_like(batch[0]) # 生成与当前批次图像相同形状的随机噪声
loss = train_step(batch[0], t, noise) # 执行训练步骤,计算损失
if step % 500 == 0: # 每500个步骤打印一次损失
print(" epoch: ", epoch, " step: ", step, " Loss: ", loss)
end_time = time.time() # 记录结束时间
times = end_time - begin_time # 计算训练时间
print("training time:", times, "s") # 打印每个epoch的训练时间
# 展示随机采样效果
unet_model.set_train(False) # 设置模型为评估模式
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels) # 进行样本生成
plt.imshow(samples[-1][5].reshape(image_size, image_size, channels), cmap="gray") # 可视化生成的样本
print("Training Success!") # 打印训练成功的信息
解析:
- 导入库:
import time: 导入时间库以便记录训练时间。
- 设置训练周期:
epochs = 10: 定义总训练周期数为 10。
- 训练循环:
for epoch in range(epochs): 对每个 epoch 进行循环。begin_time = time.time(): 记录当前时间以计算本 epoch 的训练时间。for step, batch in enumerate(dataset.create_tuple_iterator()): 遍历数据集,获取每个批次的数据。unet_model.set_train(): 将模型设置为训练模式,启用正向传播和反向传播。batch_size = batch[0].shape[0]: 获取当前批次的大小。t = randint(0, timesteps, (batch_size,), dtype=ms.int32): 随机选择时间步,用于扩散过程。noise = randn_like(batch[0]): 生成与当前批次相同形状的随机噪声。loss = train_step(batch[0], t, noise): 调用先前定义的train_step函数进行一次训练,并获得损失值。
- 打印损失:
if step % 500 == 0: 每 500 个步骤打印当前的 epoch、步骤和损失值,便于监控训练过程。
- 计算和打印训练时间:
end_time = time.time(): 记录结束时间。times = end_time - begin_time: 计算本 epoch 的训练时间,并打印出来。
- 生成样本:
unet_model.set_train(False): 将模型设置为评估模式。samples = sample(...): 进行图像生成,生成 64 张图像。plt.imshow(...): 使用 Matplotlib 可视化生成的图像,展示最后生成的样本。
- 训练成功提示:
print("Training Success!"): 在所有训练完成后,打印训练成功的信息。
使用场景:
- 该代码段实现了对 U-Net 模型的训练过程,并且在训练过程中监控损失值,输出训练时间,并在每个 Epoch 结束后进行样本生成和可视化。适用于图像生成、恢复或分割等任务的深度学习模型训练,能够帮助开发者观察模型的训练动态和生成效果。

推理过程(从模型中采样)
要从模型中采样,我们可以只使用上面定义的采样函数:
# 采样64个图片
unet_model.set_train(False) # 设置模型为评估模式,关闭训练时的正向传播和反向传播
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels) # 生成64张样本图片
# 展示一个随机效果
random_index = 5 # 随机选择一个索引
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray") # 可视化第random_index张生成的图片
plt.axis('off') # 关闭坐标轴显示
plt.show() # 显示图片
解析:
- 设置模型为评估模式:
unet_model.set_train(False): 将模型设为评估模式,以确保在采样时不进行正向传播和反向传播,这在进行推理时是必要的。
- 进行样本生成:
samples = sample(...): 调用sample函数生成 64 张图像,传入图像的大小、批次大小和通道数。
- 展示随机效果:
random_index = 5: 定义要展示的随机索引,选择第 6 张生成的图像(由于索引从 0 开始)。plt.imshow(...): 使用 Matplotlib 显示选择的生成图像。samples[-1][random_index]: 访问最后一组生成的样本并选择随机索引的图像。reshape(image_size, image_size, channels): 将图像数据重塑为适合显示的形状。
- 关闭坐标轴显示:
plt.axis('off'): 关闭坐标轴的显示,使图像更加清晰。
- 显示图像:
plt.show(): 显示生成的图像。
使用场景:
- 该代码段用于展示通过 U-Net 模型生成的图像。适用于分析模型生成效果,并观察生成图像的质量和多样性。常见于图像生成、图像恢复和图像分割等任务的结果可视化。通过随机选择图像,可以帮助研究者了解模型在不同输入下的表现。
<matplotlib.image.AxesImage at 0x7f5175ea1690>

可以看到这个模型能产生一件衣服!
请注意,我们训练的数据集分辨率相当低(28x28)。
我们还可以创建去噪过程的gif:
import matplotlib.animation as animation # 导入动画库
random_index = 53 # 定义要展示的随机索引
fig = plt.figure() # 创建一个图形对象
ims = [] # 初始化图像列表
for i in range(timesteps):
# 创建每个时间步的图像并添加到列表中
im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)
ims.append([im]) # 将图像添加为列表中的一个项
# 创建动画
animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=100)
# `interval=50`: 每帧之间的间隔为50毫秒
# `blit=True`: 指定是否使用blitting优化
# `repeat_delay=100`: 动画完成后的延迟时间(毫秒)
animate.save('diffusion.gif') # 保存动画为GIF文件
plt.show() # 显示动画
解析:
- 导入动画库:
import matplotlib.animation as animation: 导入 Matplotlib 的动画模块,以便创建和保存动画。
- 定义随机索引:
random_index = 53: 选择要展示的具体图像索引。
- 创建图形对象:
fig = plt.figure(): 创建一个新的图形对象,用于展示动画。
- 初始化图像列表:
ims = []: 创建一个空列表,用于存储每个时间步的图像帧。
- 生成图像序列:
for i in range(timesteps): 遍历每个时间步。im = plt.imshow(...): 生成当前时间步的图像,并将其添加到ims列表中。samples[i][random_index].reshape(image_size, image_size, channels): 从样本中获取指定索引的图像,并调整形状以适合显示。cmap="gray": 设置颜色映射为灰度。animated=True: 指定图像为动画帧。
- 创建动画:
animate = animation.ArtistAnimation(...): 使用ArtistAnimation创建动画对象。interval=50: 每帧之间的时间间隔为 50 毫秒。blit=True: 启用 blitting 模式,以提高动画的性能。repeat_delay=100: 动画完成后的延迟时间设置为 100 毫秒。
- 保存动画:
animate.save('diffusion.gif'): 将生成的动画保存为 GIF 文件,文件名为diffusion.gif。
- 显示动画:
plt.show(): 显示生成的动画。
使用场景:
- 该代码段用于创建和保存一个动画,展示模型在不同时间步生成的图像变化。这在研究图像生成、扩散模型或任何动态过程时非常有用,能够直观地显示模型如何逐步生成或恢复图像。通过将结果保存为 GIF,便于分享和展示。

总结
请注意,DDPM论文表明扩散模型是(非)条件图像有希望生成的方向。自那以后,diffusion得到了(极大的)改进,最明显的是文本条件图像生成。下面,我们列出了一些重要的(但远非详尽无遗的)后续工作:
- 改进的去噪扩散概率模型(Nichol et al., 2021):发现学习条件分布的方差(除平均值外)有助于提高性能
- 用于高保真图像生成的级联扩散模型([Ho et al., 2021):引入级联扩散,它包括多个扩散模型的流水线,这些模型生成分辨率提高的图像,用于高保真图像合成
- 扩散模型在图像合成上击败了GANs(Dhariwal et al., 2021):表明扩散模型通过改进U-Net体系结构以及引入分类器指导,可以获得优于当前最先进的生成模型的图像样本质量
- 无分类器扩散指南([Ho et al., 2021):表明通过使用单个神经网络联合训练条件和无条件扩散模型,不需要分类器来指导扩散模型
- 具有CLIP Latents (DALL-E 2) 的分层文本条件图像生成 (Ramesh et al., 2022):在将文本标题转换为CLIP图像嵌入之前使用,然后扩散模型将其解码为图像
- 具有深度语言理解的真实文本到图像扩散模型(ImageGen)(Saharia et al., 2022):表明将大型预训练语言模型(例如T5)与级联扩散结合起来,对于文本到图像的合成很有效
请注意,此列表仅包括在撰写本文,即2022年6月7日之前的重要作品。
目前,扩散模型的主要(也许唯一)缺点是它们需要多次正向传递来生成图像(对于像GAN这样的生成模型来说,情况并非如此)。然而,有正在进行中的研究表明只需要10个去噪步骤就能实现高保真生成。















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









