







数据集划分
满足条件:
训练集和测试集都要保证是从样本真实分布中独立同分布采样而得
训练集和测试集互斥
留出法
尽可能保证数据分布的一致性
采用分层采样
大约2/3~4/5的样本作为训练集,其余的作为测试集
交叉验证法
将数据集D分为k份,其中k-1份作为训练集,剩余的一份作为测试集,这样就可以获得k组训练/测试集,可以进行k次训练与测试,最终返回的是k个测试结果的均值。
留一法: k=1
分层采样
自助法
我们每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为m次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。
约有36.8%的数据没有在训练集中出现过
有放回重复采样
对于数据量充足的时候:留出法 or k折交叉验证法
- 对于数据集小且难以有效划分训练/测试集:自助法;
- 对于数据集小且可有效划分的时候:留一法
模型介绍
逻辑回归
优点:
模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
适合二分类问题,不需要缩放输入特征
缺点:
-
需要预先处理缺失值和异常值
-
不能解决非线性模型
-
多重共线性数据敏感
-
很难处理数据不平衡的问题
-
准确率不高,难拟合数据的真实分布
逻辑回归的损失函数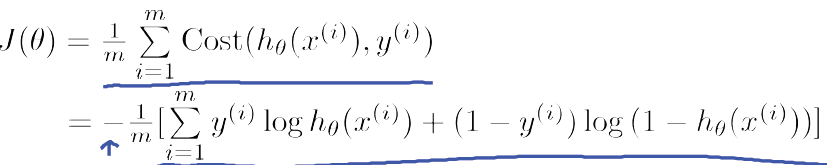
模型调参
lightgbm
贪心调参
日常调参过程中常用的参数和调参顺序:
- ①:max_depth、num_leaves
- ②:min_data_in_leaf、min_child_weight
- ③:bagging_fraction、 feature_fraction、bagging_freq
- ④:reg_lambda、reg_alpha
- ⑤:min_split_gain















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









