







知识图谱系统课程笔记(二)——知识抽取与挖掘
文章目录


OWL、RDF与RDFS关系
RDF是数据模型,定义了知识图谱的图结构,以主谓宾来表示的三元组,对应很多序列化格式。
RDFS也可以用RDF来表示,只是这里的调语和宾语是一些预定 义的词汇,如谓语是rdf:type, rdfs:subClass或rdfs subProperty , domain, range,宾语rdfs:Class和rdfs:Property等.在此基础上, OWL也可以用RDF来表示为三元组,他会增加更多的预定义的词汇.这些词汇使得我们有了更严格并支持本体推理的schema层或称为概念层。
对于了解一些常用的缩写是有价值的,这种多看几个我们说的知识库,并用- -下他们的SPARQL查询接口或浏览界面就会慢慢熟悉了,不要强行去背。
知识抽取任务定义和相关比赛
知识抽取技术
定义:知识抽取是自动地从文本中发现和抽取相关信息。
● 实体抽取
● 关系抽取
● 事件抽取.
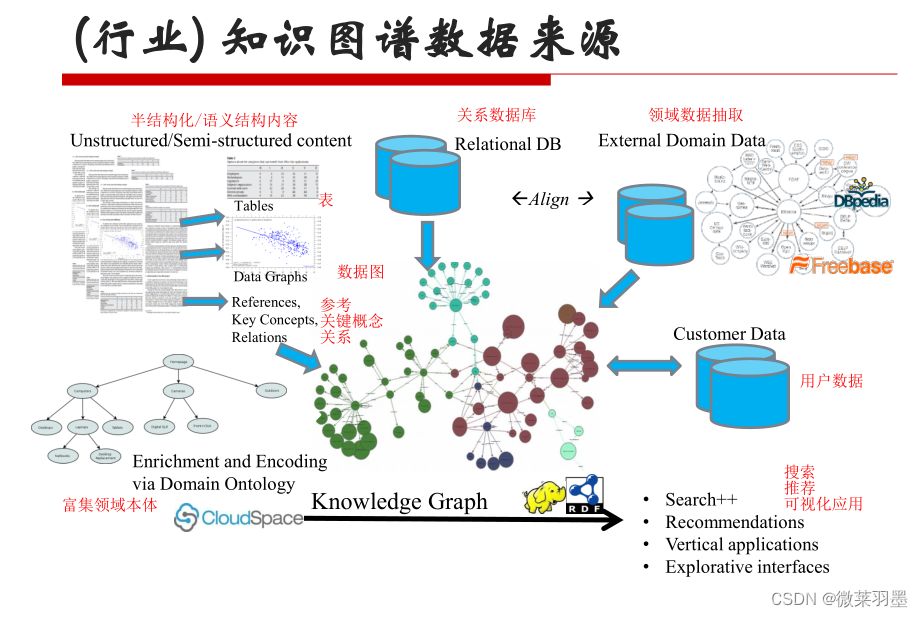
(行业)知识图谱数据来源
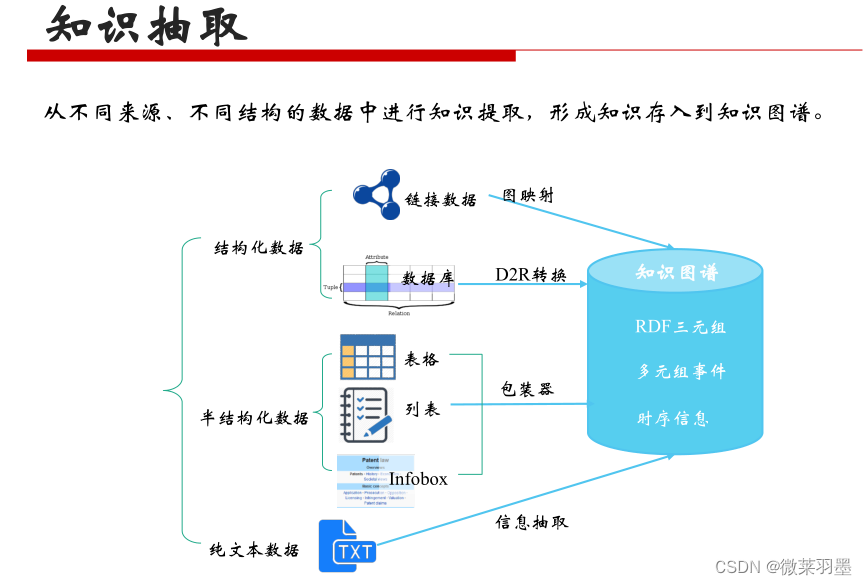
知识抽取的数据类型
从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱。
示例:
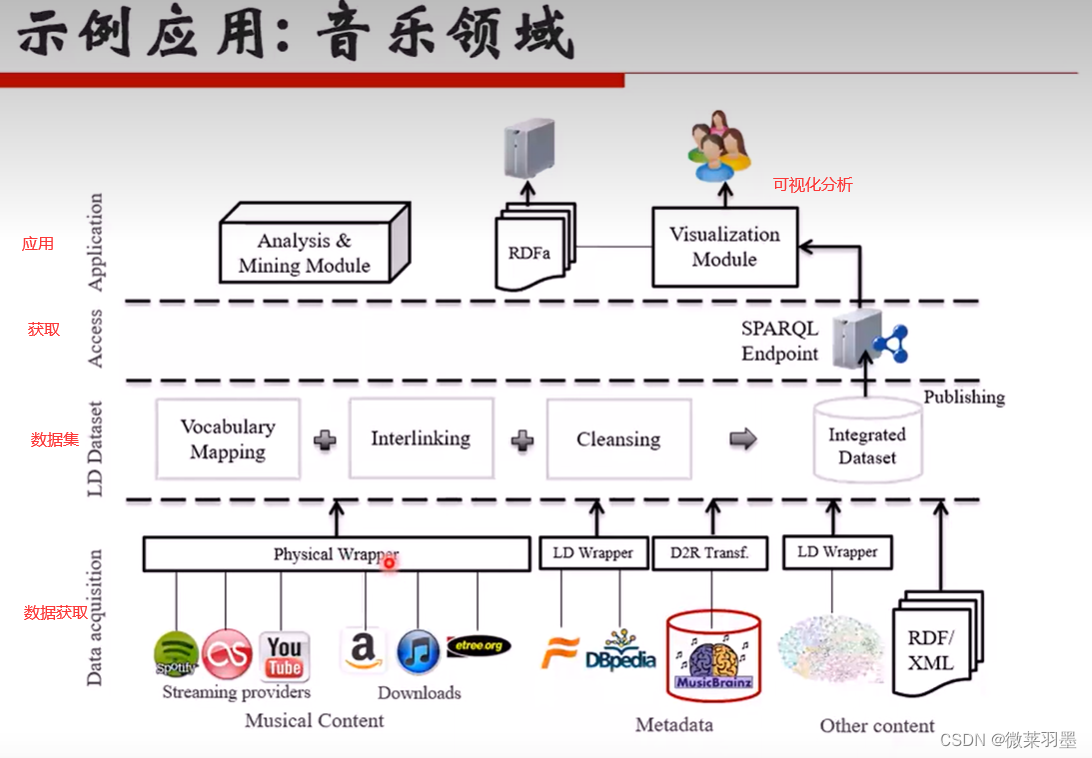
知识获取关键技术与难点
●) 从结构化数据库中获取知识: D2R
●难点:复杂表数据的处理
●从链接数据 中获取知识:图映射
●难点:数据对齐
●从半结构化 (网站)数据中获取知识:使用包装器
●难点:方便的包装器定义方法,包装器自动生成、更新与维护
●从文本中获取知识:信息抽取
● 难点:结果的准确率与覆盖率
知识抽取的子任务
1.命名实体识别
检测:西瓜书的作者是周志华。→[西瓜书]:实体
分类:西瓜书的作者是周志华。→[西瓜书]:书籍

2.术语抽取
从语料中发现多个单词组成的相关术语。
3.关系抽取
抽取出实体、属性等之间的关系。
例子:王思聪是万达集团董事长王健林的独子。→[王健林] <父子关系> [王思聪]
4.事件抽取
相当于多元关系抽取
例子:

5.共指消解


其他
- 实体检测与识别
例如:人、组织、地点、工具等。

- 数值检测与识别

- 实体发现与链接
人 person(PER)

- 槽填充
发现并填充 实体的属性。

其他

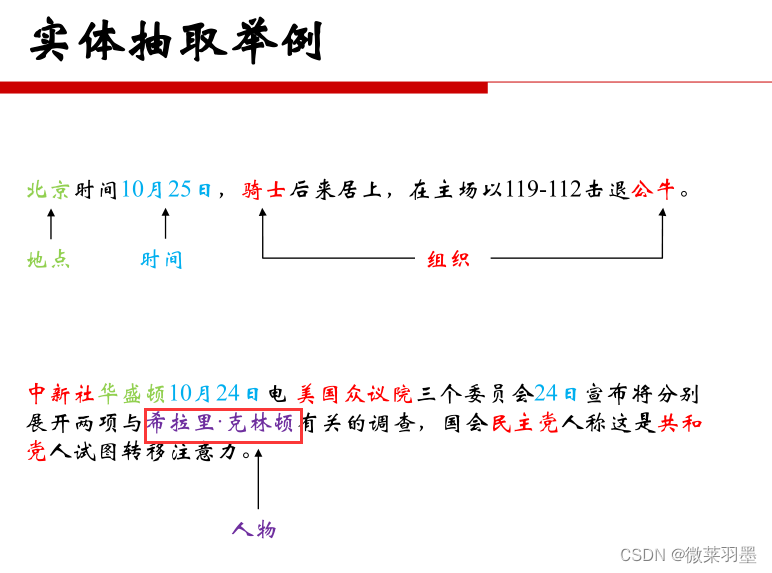
实体抽取
定义:抽取文本中的原子信息元素。
实体:包括人名、组织/机构名、地理位置、时间/日期、字符值、金额值等(原子根据场景来定义)。
例子:
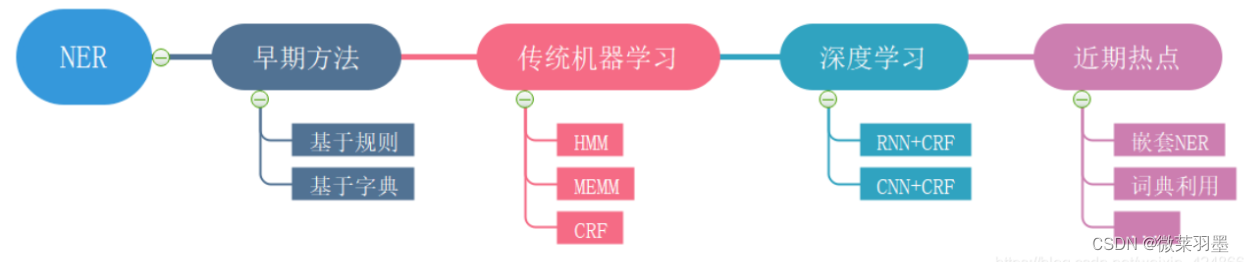
命名实体识别 NER
发展历史:
**定义:**识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。一般而言,主要是识别出待处理文本中七类(人名、机构名、地名、时间、日期、货币和百分比)命
名实体
两个任务:实体边界识别和实体类别标注(Entity Typing)
**功能:**命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。

标签类型:进行命名实体识别时,通常需要对每个字进行标注,中文为单个字,英文为单词,空格分割。标注的标签类型如下表所示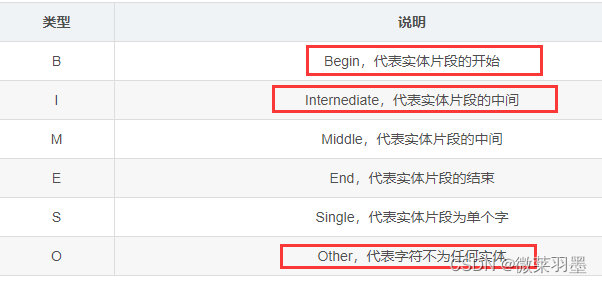
————————————————
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421
非结构化数据的实体抽取
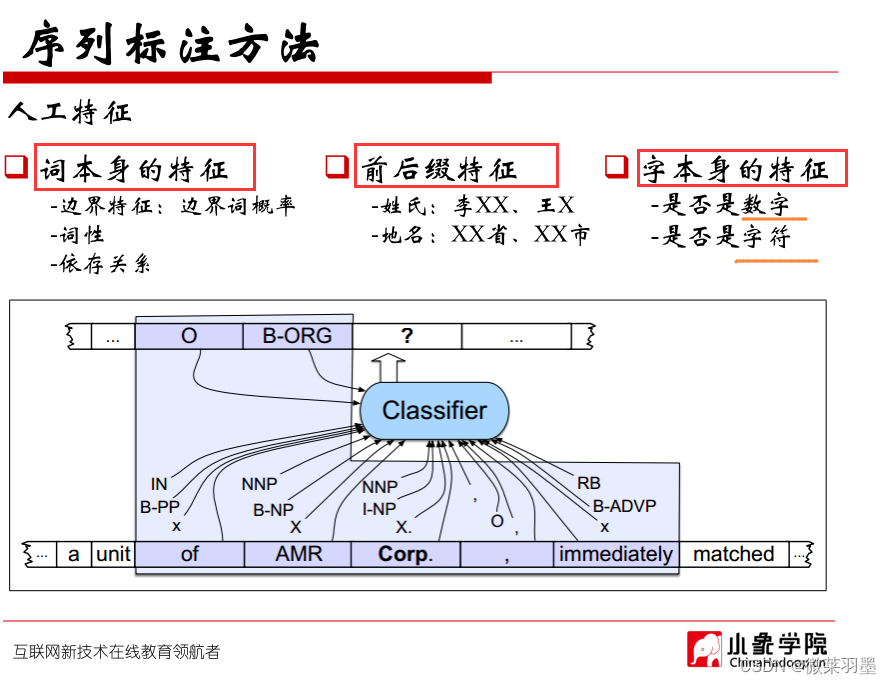
非结构化数据的实体抽取可以认为是一个序列标注问题,于是我们可以使用序列标注的方法,例如使用HMM、CRF等方法,也可以使用LSTM+CRF的方法,
序列标注方法
序列标注定义:序列标注(Sequence Tagging)是NLP中最基础的任务,应用十分广泛,如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)等实质上都属于序列标注的范畴。
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421
- 简述序列标注的三种方法
实体识别三种常见的序列标注方法如下:
**BIO:**标识实体的开始,中间部分和非实体部分
**BMES:**增加S单个实体情况的标注
**BIOSE:**增加E实体的结束标识
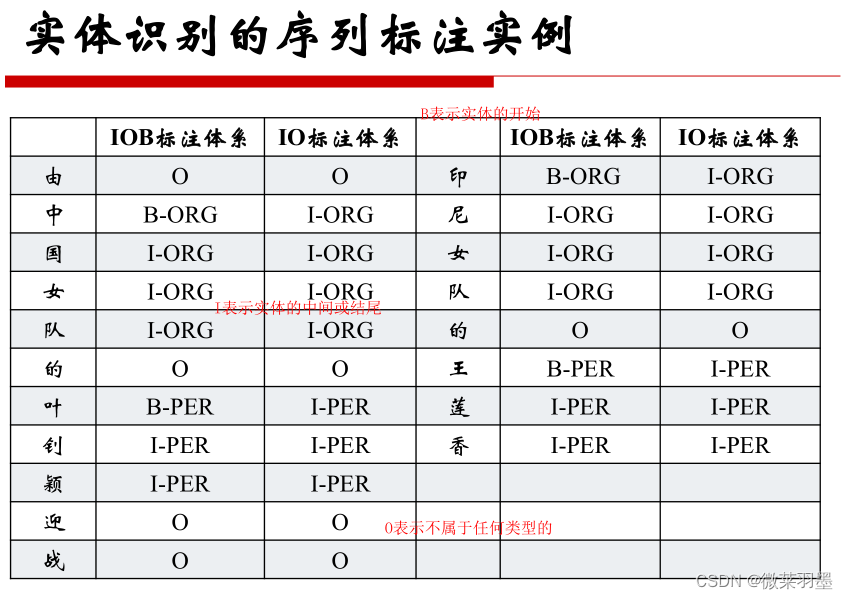
1.BIO-三位序列标注法(B-begin,I-inside,O-outside)
B-X代表实体X的开头
I-X代表实体X的中间或结尾
O代表不属于任何类型的
样例:
我是李果冻,我爱中国,我来自四川。
我 O
是 O
李 B-PER
果 I-PER
冻 I-PER
, O
我 O
爱 O
中 B-ORG
国 I-ORG
, O
我 O
来 O
自 O
四 B-LOC
川 I-LOC
。 O
2.BMES-四位序列标注法(B-begin,M-middle,E-end,S-single)
B 表示一个词的词首位值
M 表示一个词的中间位置
E 表示一个词的末尾位置
S 表示一个单独的字词
样例:
我是四川人
我 S
是 S
四 B
川 M
人 E
3.BIOES-四位序列标注法(B-begin,I-inside,O-outside,E-end,S-single)
B表示开始
I表示内部
O表示非实体
E表示实体尾部
S表示改词本身就是一个实体
样例:
我是李果冻,我爱中国,我来自四川。
我 O
是 O
李 B-PER
果 I-PER
冻 E-PER
, O
我 O
爱 O
中 B-LOC
国 E-LOC
, O
我 O
来 O
自 O
四 B-LOC
川 E-LOC
。 O
————————————————
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421
序列标注的实例:
序列标注的经典方法:HMM,MEMM,CRF
参考序列标注的经典方法:HMM,MEMM,CRF
添加链接描述
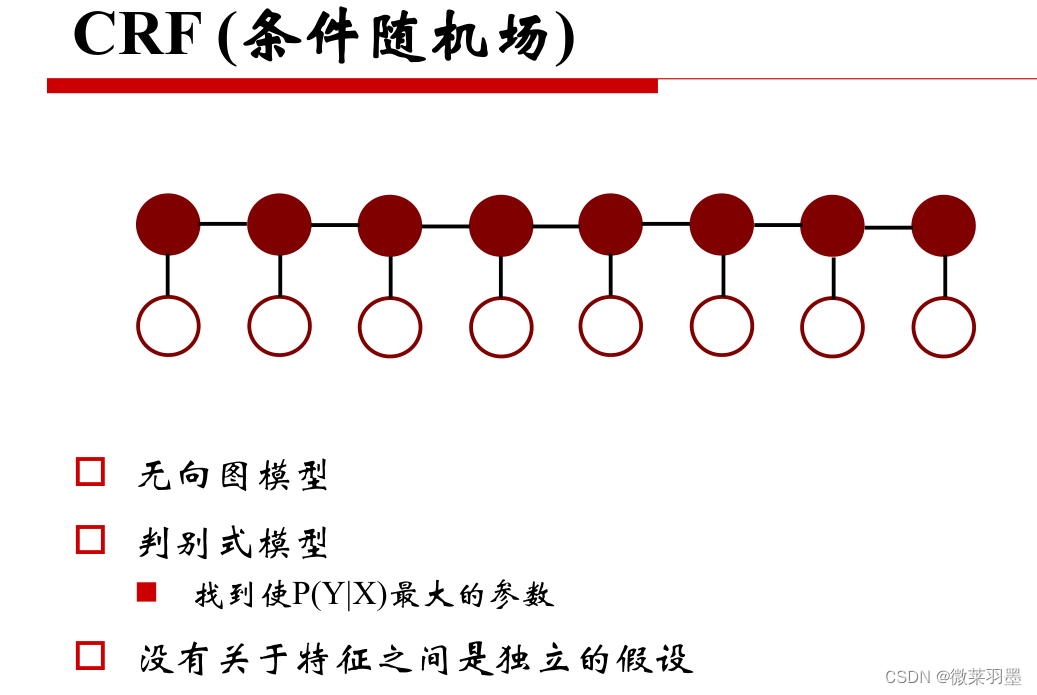
HMM(隐马尔可夫模型)

CRF(条件随机场)
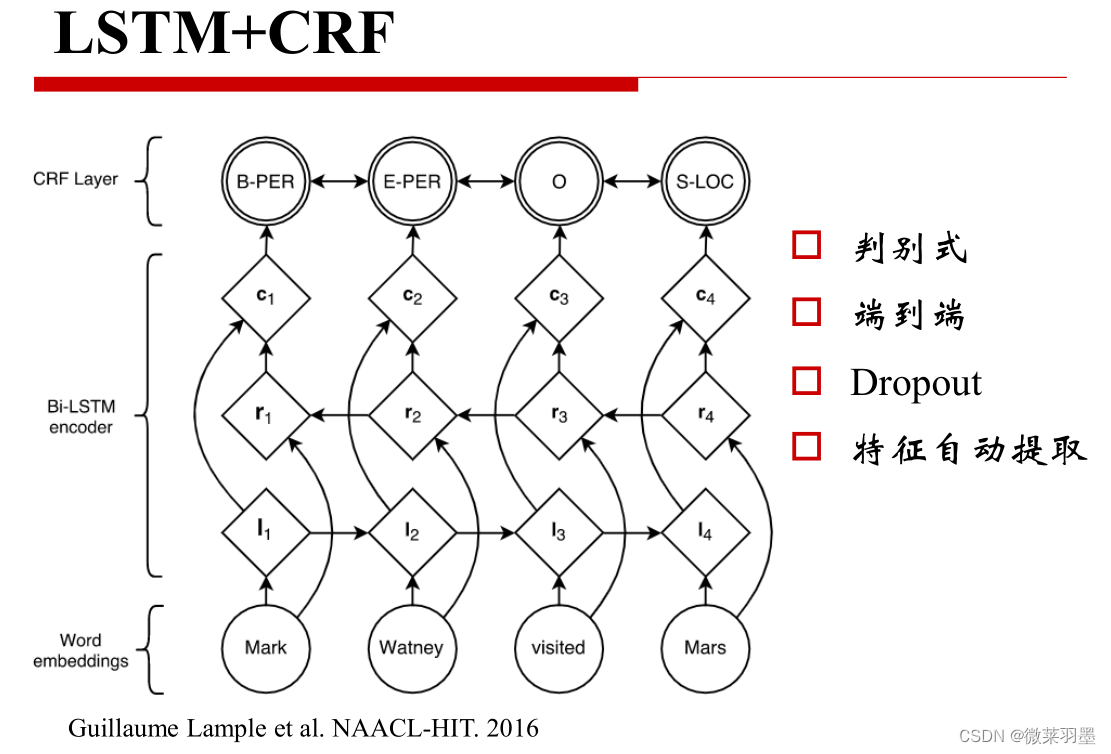
LSTM+CRF
每个句子按照词序逐个输入双向LSTM中,结合正反向隐层输出得到每个词属于每个实体类别标签的概率,输入CRF中,优化目标函数,从而得到每个词所属的实体类别.
几种方法通过F1值的比较如下:

参考文献
实体抽取:
- hiheng Huang, Wei Xu, Kai Yu. Bidirectional LSTM-CRF Models for Sequence Tagging. CoRR. 2015
- Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, Chris Dyer. Neural Architectures for Named Entity Recognition. The 2016 Conference of the North American Chapter of the Association for Computational Linguistics. 2016: 260-270
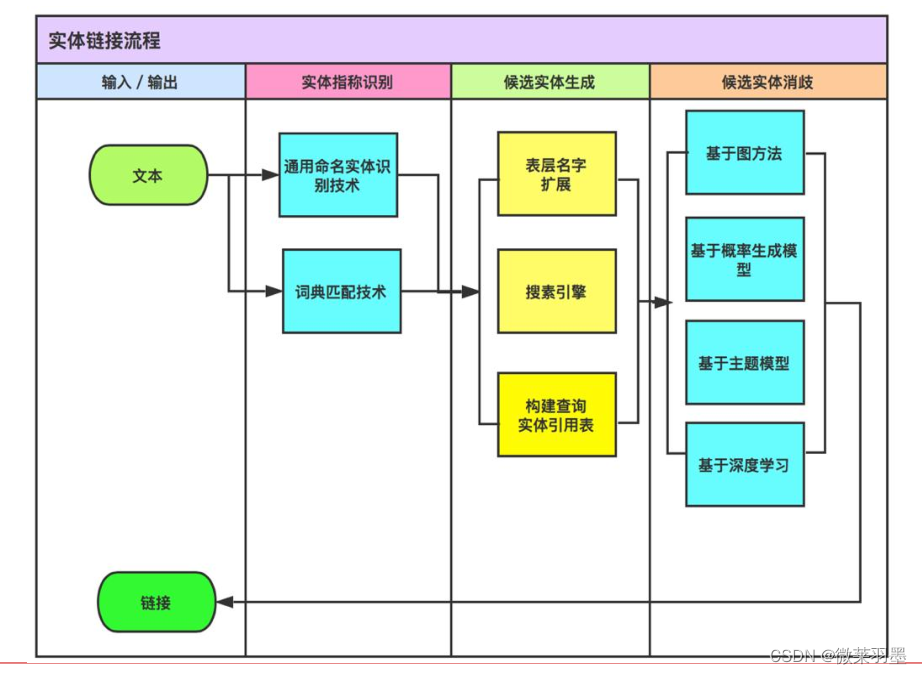
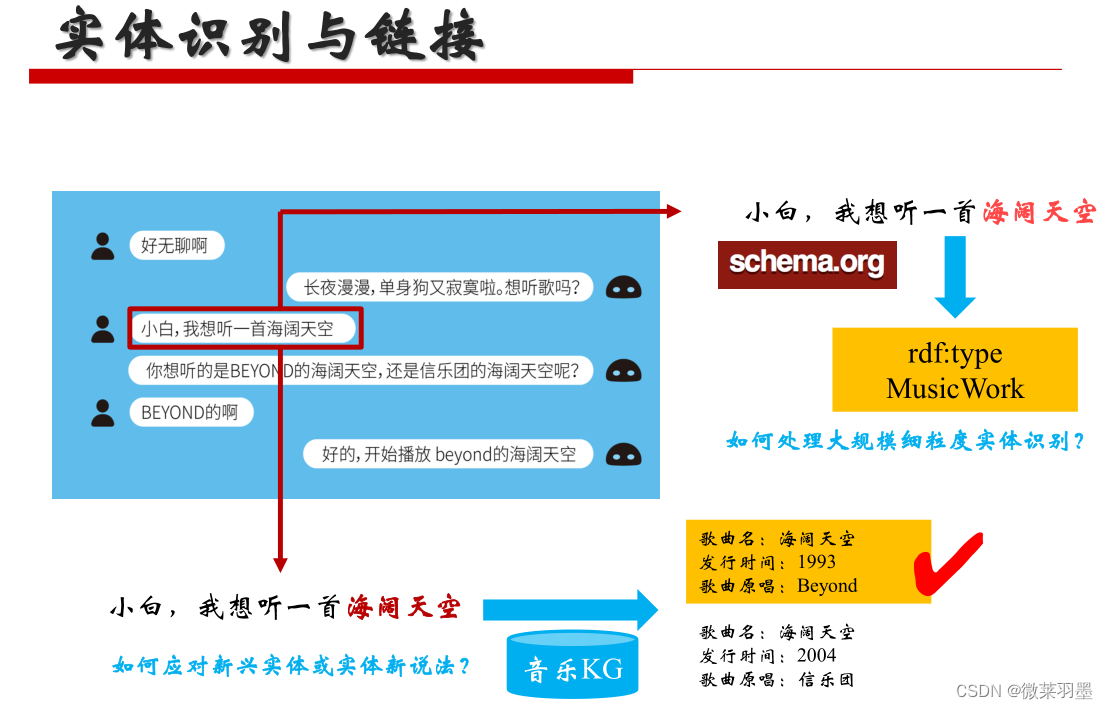
实体识别与链接
实体链接:识别非结构化数据(文本)中的实体,并将它们链接到知识库中,是让机器理解自然语言的第一步,也是至关重要的一步。
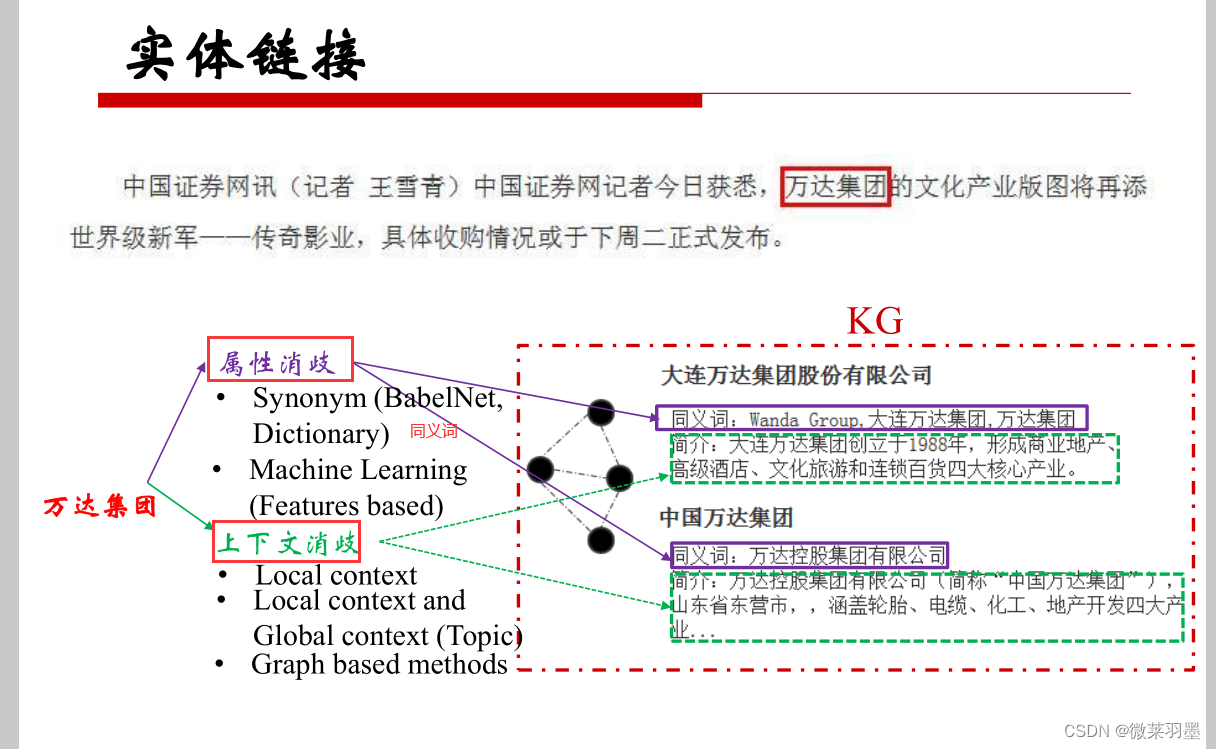
实体消歧的原因:实体识别出来的实体名可能是有歧义的,可能有多个实体都对应着某个实体名,也可能摸个实体对应着多个实体名,如china可能是中国也可能是瓷器,此时我们需要对实体进行消歧与链接。
过程:
DBpedia Spotlight
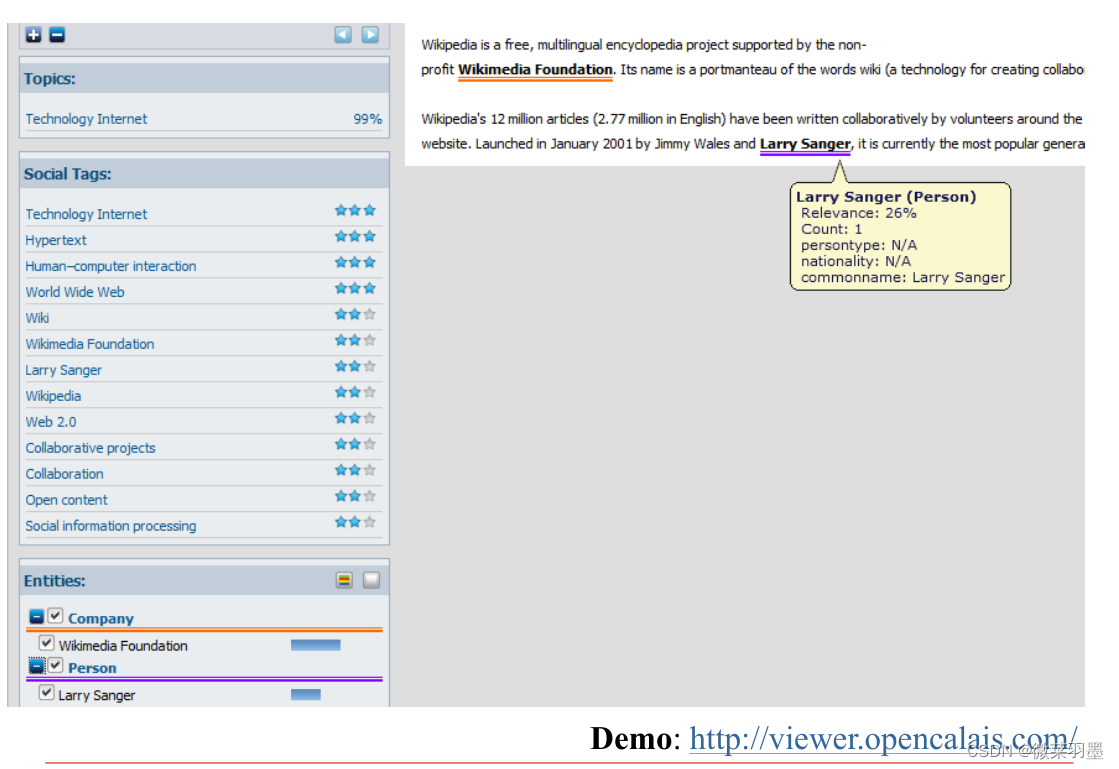
DBpedia Spotlight可以把我们输入的文本中的实体抽取出来,将其对应到知识图谱DBpedia。官方提供了一个示例网站:https:/demo.dbpedia-spotlight.org
dbpedia-spotlight网站

【DBpedia Spotlight】知识图谱实体链接/抽取文本实体

Demo:http://dbpedia-spotlight.github.io/demo/网址
opencalais
http://www.opencalais.com/

Demo: http://viewer.opencalais.com/
实体链接举例:
实体识别和链接的开源系统
【1】http://acube.di.unipi.it/tagme/
【2】https://github.com/parthatalukdar/junto
【3】http://orion.tw.rpi.edu/~zhengj3/wod/wikify.php
【4】https://github.com/yahoo/FEL
【5】https://github.com/yago-naga/aida
【6】http://www.nzdl.org/wikification/about.html
【7】http://aksw.org/Projects/AGDISTIS.html
【8】https://github.com/dalab/pboh-entity-linking
关系抽取
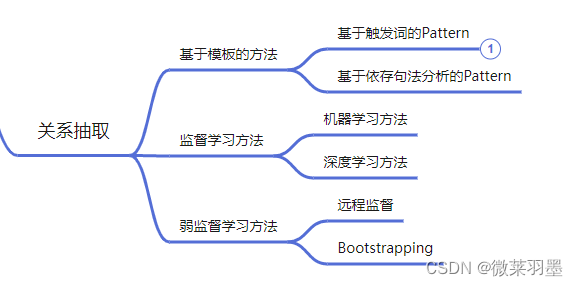
简介:信息抽取 (Information Extraction)研究领域的任务之一, ==从文本中抽取出两个或者多个实体之间的语义关系。==关系抽取主要有基于模板的方法、监督学习方法和弱监督学习方法。
举例:


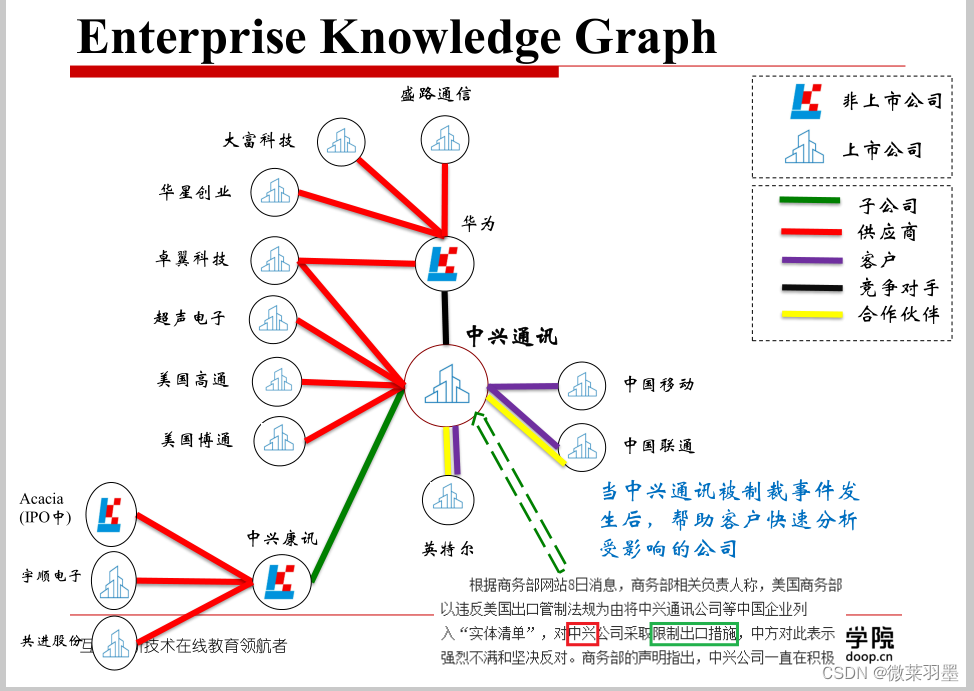
举例:企业知识图谱
关系抽取的方法:
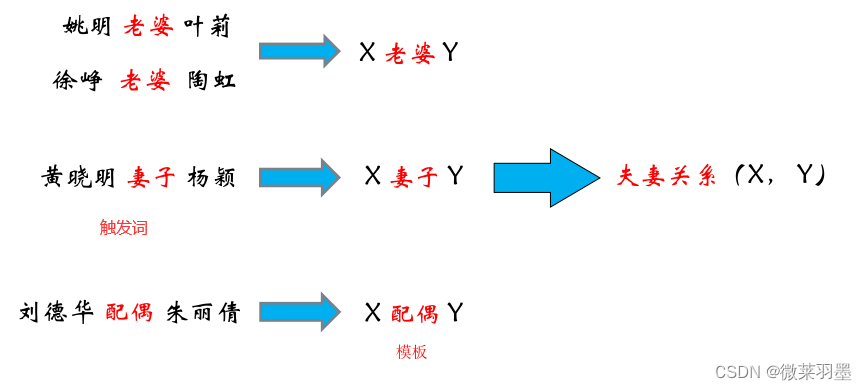
1.基于模板的方法
- 基于触发词的Pattern
首先确定一个触发词(trigger word),然后根据触发词做pattern的匹配及抽取,然后做一个映射。
例子:
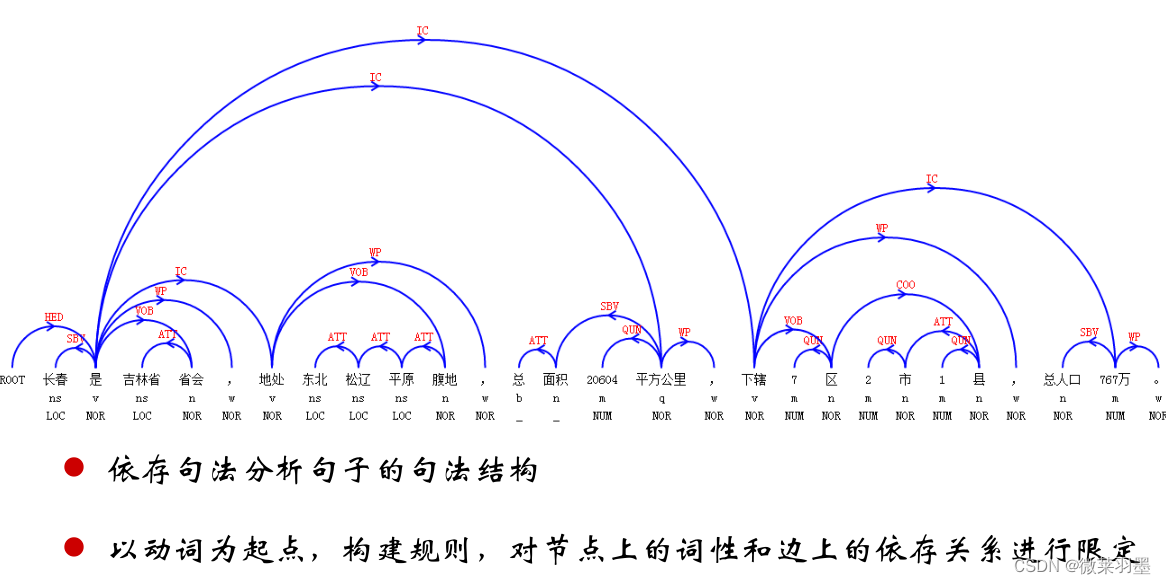
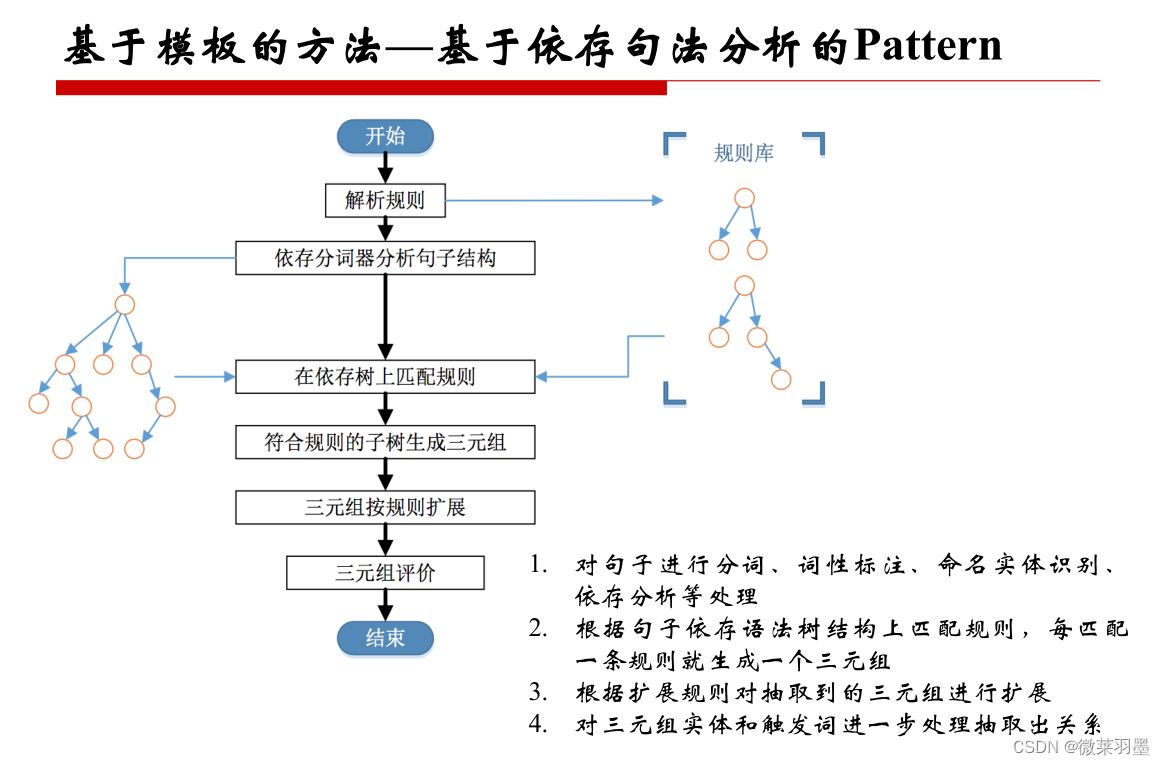
- 基于依存句法分析的Pattern
文本一般具有一些句法结构,如主谓结构、动宾结构、从句结构、这些结构可以是跨多个词所产生的。最常见的情况是动宾短语,所以我通常以动词为起点,构建规则,对节点上的词性和边上的依存关系进行限定(可以理解为泛化的正则表达式)。
具体的流程如下:
- 对句子进行分词、词性标注、命名实体识别、依存分析等处理
- 根据句子依存语法树结构上匹配规则,每匹配一条规则就生成一个三元组
- 根据扩展规则对抽取到的三元组进行扩展
- 对三元组实体和触发词进一步处理抽取出关系
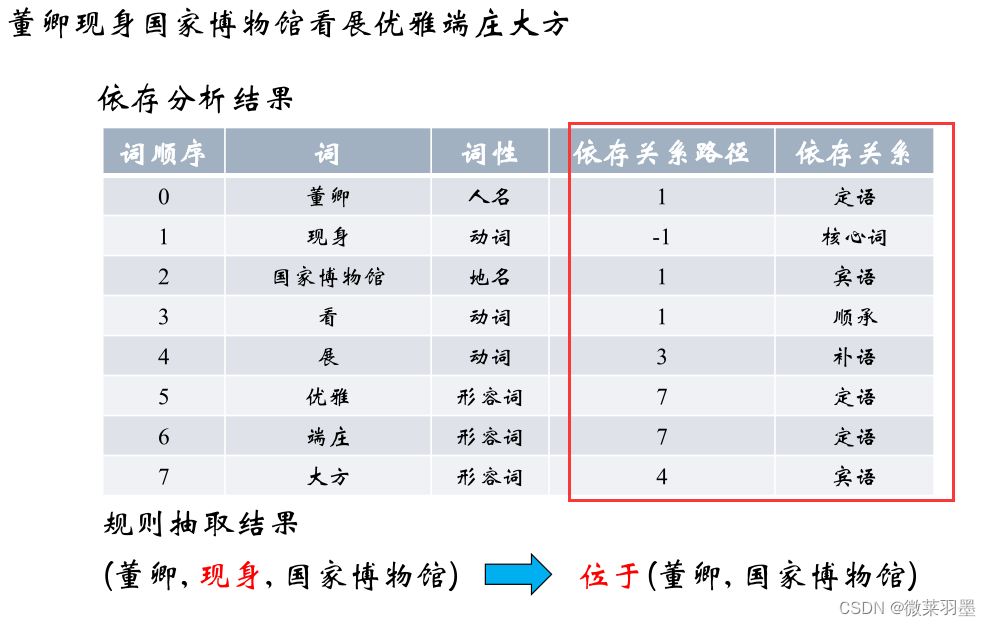
例子:董卿现身国家博物馆看展优雅端庄大方。
依存分析:
基于模板的方法的优缺点:
优点
➢ 在小规模数据集上容易实现
➢ 构建简单
缺点
➢特定领域的模板需要专家构建
➢难以维护
➢可移植性差
➢规则集合小的时候,召回率很低。(召回率召回率详解也叫查全率,旨在找到实际为正的样本中多少被预测为正。)


















 5776
5776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











