







目录
- 模型结构详解
- 数学原理与推导
- 代表性变体及改进
- 应用场景与优缺点
- PyTorch代码示例
1. 模型结构详解
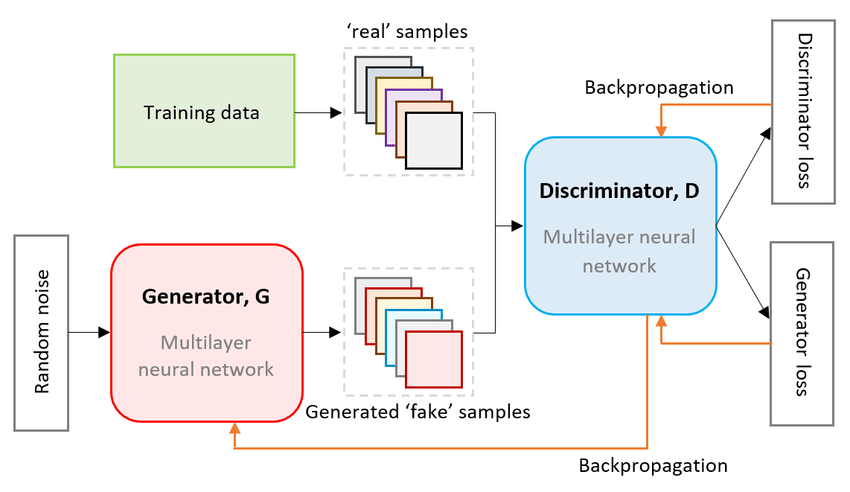
1.1 核心架构
GAN由生成器(Generator)和判别器(Discriminator)组成,通过对抗博弈优化:
噪声z → 生成器G → 假数据G(z) 真实数据x ↔ 判别器D → 真伪概率
1.1.1 生成器G
- 输入:随机噪声向量 z∼N(0,1)
- 层级结构(以DCGAN为例):
FC(100→1024) → ReLU → Transposed Conv(4x4, stride=2) → ReLU → Transposed Conv(4x4, stride=2) → Tanh → 输出(3x64x64) - 激活函数:
- 中间层:ReLU/LeakyReLU
- 输出层:Tanh(图像值域[-1,1])或Sigmoid([0,1])
1.1.2 判别器D
- 输入:真实数据x或生成数据G(z)
- 层级结构(与G对称):
Conv(4x4, stride=2) → LeakyReLU(0.2) → Conv(4x4, stride=2) → LeakyReLU(0.2) → FC(1024→1) → Sigmoid → 真伪概率 - 激活函数:
- LeakyReLU(防止梯度消失)
- 输出层:Sigmoid(概率值[0,1])
2. 数学原理与推导
2.1 目标函数
对抗博弈的极小极大目标:
2.2 优化过程
- 判别器D的更新:
- 生成器G的更新:
或更稳定的目标:
2.3 JS散度解释
当D达到最优时,GAN等价于最小化真实分布pdata与生成分布pg的JS散度:
3. 代表性变体及改进
3.1 架构改进系列
3.1.1 DCGAN
- 改进点:
- 使用卷积层替代全连接
- 引入BatchNorm层稳定训练
- 结构规范:
- 去除池化层,用步幅卷积实现上下采样
- 生成器使用转置卷积
3.1.2 Progressive GAN
- 渐进训练:
从低分辨率(4x4)开始,逐步增加层到高分辨率(1024x1024) - 消融技巧:
平滑过渡阶段,避免训练突变
3.2 损失函数改进系列
3.2.1 WGAN
- 改进点:
- 用Wasserstein距离替代JS散度
- 移除判别器的Sigmoid,输出实数分数
- 损失函数:
- 梯度惩罚(WGAN-GP):
添加梯度范数惩罚项:
3.2.2 LSGAN
- 最小二乘损失:
- 优势:缓解梯度消失,生成质量更稳定
3.3 应用专用系列
3.3.1 CycleGAN
- 核心思想:无配对图像到图像翻译
- 循环一致性损失:
- 应用场景:风格迁移(照片→油画)、季节转换
3.3.2 StyleGAN
- 风格混合:
通过AdaIN(自适应实例归一化)控制生成细节 - 噪声注入:
在每一层添加人工噪声,增加多样性 - 映射网络:
将潜在向量z映射到中间空间w,解耦特征
4. 应用场景与优缺点
4.1 应用场景
| 领域 | 适用变体 | 案例 |
|---|---|---|
| 图像生成 | DCGAN/StyleGAN | 人脸生成、艺术品创作 |
| 数据增强 | WGAN/DCGAN | 医学影像合成 |
| 图像翻译 | CycleGAN | 卫星地图↔航拍照片 |
| 超分辨率 | SRGAN | 4K图像重建 |
| 文本到图像 | StackGAN | 根据描述生成场景图像 |
4.2 优缺点对比
| 优点 | 缺点 |
|---|---|
| 生成质量高,细节丰富 | 训练不稳定,易模式崩溃 |
| 无需明确数据分布假设 | 评估指标(如FID)计算复杂 |
| 支持多种数据模态 | 生成结果不可控风险 |
| 启发生成式模型新范式 | 训练资源消耗大 |
5. PyTorch代码示例
5.1 DCGAN实现(生成MNIST)
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self, latent_dim=100):
super().__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 256, 4, 1, 0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 3, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 1, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, z):
return self.main(z)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(1, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, img):
return self.main(img).view(-1)
# 训练循环示例
G = Generator().to(device)
D = Discriminator().to(device)
criterion = nn.BCELoss()
opt_G = torch.optim.Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))
opt_D = torch.optim.Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
for epoch in range(epochs):
for real_imgs, _ in dataloader:
# 训练判别器
z = torch.randn(batch_size, 100, 1, 1, device=device)
fake_imgs = G(z)
real_labels = torch.ones(real_imgs.size(0), device=device)
fake_labels = torch.zeros(fake_imgs.size(0), device=device)
D_real_loss = criterion(D(real_imgs), real_labels)
D_fake_loss = criterion(D(fake_imgs.detach()), fake_labels)
D_loss = (D_real_loss + D_fake_loss) / 2
opt_D.zero_grad()
D_loss.backward()
opt_D.step()
# 训练生成器
G_loss = criterion(D(fake_imgs), real_labels)
opt_G.zero_grad()
G_loss.backward()
opt_G.step()5.2 WGAN-GP实现片段
# 梯度惩罚计算
def compute_gradient_penalty(D, real_samples, fake_samples):
alpha = torch.rand(real_samples.size(0), 1, 1, 1, device=device)
interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)
d_interpolates = D(interpolates)
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=torch.ones_like(d_interpolates),
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# WGAN-GP损失
D_loss = -torch.mean(D(real_samples)) + torch.mean(D(fake_samples)) + lambda_gp * gradient_penalty核心总结
- 对抗本质:生成器与判别器的动态博弈平衡
- 数学基础:JS/Wasserstein距离衡量分布差异
- 工程难点:模式崩溃、训练不稳定的调参技巧
- 演进方向:
- 更稳定的训练方法(如Diffusion GAN)
- 多模态可控生成(如Text-to-Video GAN)
- 轻量化部署(移动端GAN压缩)

















 7523
7523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









