






日期:2023/12/11
论文:Learning Transferable Visual Models From Natural Language Supervision
链接:CLIP - MLR2021
目录
CLIP
正文
1 摘要翻译
训练最先进的计算机视觉系统用来预测一组固定的物体类别。这种受限制的形式(指模型对于数据集没有的数据它并不能做得很好)限制了系统的泛化性和可用性,因为如果想要识别其他的视觉信息,还需要额外的数据进行训练(言外之意就是做不到zero-shot)。直接从关于图像的原始文本中去学习是一个很有前景的替代方式,它利用了更广泛的监督来源(网上都是,且只要是语言描述过的都可以被用作是监督信号)。我们证实通过一种简单的预训练任务去预测该标题和哪张图像匹配的方法,是一种学习到SOTA图像特征的高效且可扩展性的方法,且数据集是从网上爬虫爬取下来的4亿个(图像,文本)对。预训练之后,自然语言被用来作为学习到的视觉信息的参考(或者说被用来描述新的视觉特征),使得模型能够zero-shot迁移到下游任务中。我们通过30多个不同的现有计算机视觉数据集进行基准测试来研究该方法的性能,跨越任务包括OCR、视频中的动作识别、地理定位和多种细粒度对象分类。该模型可以很好的转移到大多数任务(特指被用来评测的这几个数据集),并且通常可以和完全监督的baseline进行竞争,而不需要任何特定于数据集的训练(真正的zero-shot啊老铁)。具体来说,我们的zero-shot在不使用ImageNet的128万张训练数据中的任何一个做训练的情况下,与原始的ResNet50模型在ImageNet上取得的准确率相同。
流程总览图初步学习(入门版)
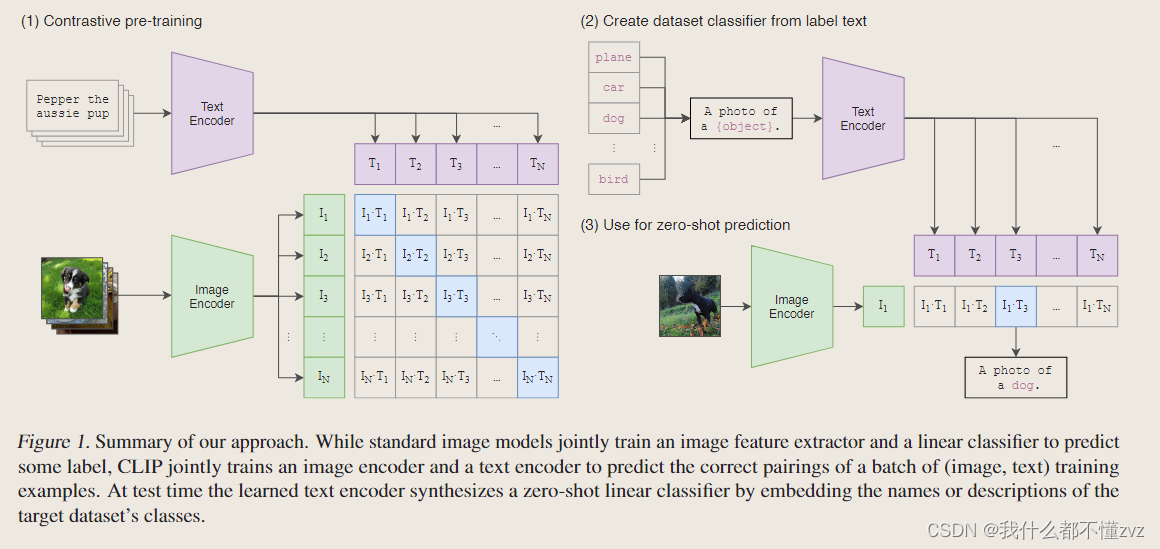
(1)的部分是说CLIP是如何进行预训练的 (多模态对比学习)
- 模型的输入是一个(图像,文字)的配对,比如说图像是一个小狗,配对的文字则是pepper。图文分别通过Image Encoder以及Text Encoder得到一个特征。假如有N个配对,则分别会得到N个Image features和N个Text features,在这些特征上去做对比学习。
- 对比学习只要能定义正负样本即可,该图中,对角线上的蓝色部分就是正样本,剩下矩阵的元素都是负样本对,然后在定义度量空间距离的loss function,模型就能学习起来了。
(2)(3)的部分是说CLIP是如何进行zero-shot的推理的
- 假如我们是要预测ImageNet上的图像,则图像可能的类别有1000类,如plane, car, dog…将这些类别名通过prompt template的方法生成一个句子 A photo of a [object] ,输入到Text encoder中得到1000个Text features
- 要预测的图像传入到Image encoder中得到1个image feature,然后去计算两个模态features的余弦相似度,在做一个softmax处理,取概率最大的一个就是该图像对应的句子。
Question:
- 为什么这就是zero-shot呢? 因为这两个encoders完全没有在ImageNet上去进行fine-tune,相当于没有见过该数据就直接预测了。更形象的例子就是如果让在ImageNet上进行预训练的监督模型预测一个红包的图像,大概率是不能预测出来的,因为ImageNet上没有。但是如果让CLIP来预测并给他关于红包的词汇,它是可以预测出红包的(既红包的词生成的概率最大)。
- 为什么要变成句子呢?因为在pre-train的时候图片看到的就是一个个句子,所以在预测的时候也效仿。且句子如何构建是很有讲究的,并且句子相比于词汇有更少的歧义性,后面都会讨论到。
2 介绍
NLP领域
- NLP领域的模型通过大数据集做自监督任务就可以得到一个很好的预训练模型(比如GPT3),并且无需或仅需很少的特定数据就可以在很多任务上保持竞争性。
- NLP的成功证实,在这种"text-to-text"的利用自监督信号去训练的模型,这种大规模无标注数据是要比手工标注的金标准数据要吃香的。
CV领域
- 作者先提出问题:这种直接从文字结果学习的可拓展的预训练方法能否也相似的运用到CV领域呢?然后作者就介绍了20多年的前人工作(略过。。)
- 在CLIP之前,这种zero-shot的模型的效果并不好,大家都热情多数是放在weak supervised上的(weak supervised强调标签比任务要弱)。但还是存在局限性的,比如类别是固定的,且都是用固定的softmax分类头去预测(输出是固定的!并不能随心所欲),没有灵活做zero-shot的能力。
- 作者认为这种弱监督和本文工作的最大区别在于SCALE 规模。 该文数据:4亿个图文配对,且使用8个模型(规模最大为Vit-Large)
- 作者发现迁移学习的效果和模型的规模其实是呈正比的。作者在30个现存数据集去做zero-shot的对比,用linear probe的方法展示在ImageNet上的效果要比最好的寻来你模型要好,且CLIP的鲁棒性要远远好于其他在ImageNet上监督训练出来的模型。
一些概念
- accelerator days:大家训练会用不同的TPU和GPU,反正比CPU快所以叫加速器天。假如是 2500个TPU V3天,就是说如果用一个TPU V3核的话要训练2500天。
3 方法
3.1 自然语言监督
- 自打有了transformer之后,就有了可以利用大量文本类监督的工具。(原文是deep contextual representation learning)
- 学习自然语言的好处1: 自然语言不会被受限于N个类别里酱紫,因此可以从网络上大量的文本中学习。
- 学习自然语言的好处2:不仅学习图像的语义信息,还学习自然语言的语义信息,多模态语义信息能使zero-shot照进现实。
3.2 创造超大规模数据集
- WIT(WebImage Text), 4亿个图文对
3.3 选择一种高效的预训练方法
- (problem) 我们发现训练的效率是自然语言监督获得成功的关键
- (原始方法) 借鉴于VirTex的方法,使用CNN提取Image特征,使用transformer提取Text特征。并且对每个图片都与预测精确的words去匹配。这样做的难点是words的多语义性以及图片本身就可以有很多种不同描述。
- (对比学习) 对比学习的工作则可以比预测任务更好的学习到特征,对比任务就是将图文进行配对,这个约束放宽了很多。生成式学习也可以学习到很好的特征但是计算开销太大。
- (其他训练细节) 由于数据集太大,过拟合的现象可能不会发生,所以
1) 两个encoders均不使用预训练权重,从头开始训练
2) 在特征之后只接linear projection而不接non-linear projection,因为实验发现没啥区别(并猜测可能仅在自监督的图像单模态中有作用)
3) 数据增强只做random crop and resize
4) 温度系数 τ \tau τ设置成一个可学习标量(因为调参成本太大)
不同预训练方法的效率和准确度对比

- Figure2中 bag of words prediction的含义是不用去逐字逐句去预测图像中的信息,而是去预测一些全局化的特征,相应的约束就放宽了。而bag of words contrastive则是去预测是否是图文匹配,约束更宽了。
- 约束放宽,效率更高,同时在同样参数的情况下,准确率也更高。
CLIP伪代码

- Image encoder可以用resnet或ViT,text encoder可以用CBOW或text transformer
- 图像和文本通过对应的encoders生成features,然后需要投射到embedding层进行多模态融合(
np.dot(I_f,W_i)这一步),相当于使维度相同,然后做归一化。 - 计算余弦相似度得到logits
- 通过与正样本计算交叉熵损失,正样本为矩阵中对角线位置上的值
3.5 Training
先不看,是一个很工程化的步骤,阅读以下了解更多:
How to Train Really Large Models on Many GPUs?
4 实验部分
4.1 zero-shot transfer
动机
自监督学习虽然能让encoder学到好的特征,但是迁移到下游任务的时候,我们还是需要labeled数据来进行微调,这就牵扯到一些数据收集或者数据分布的问题了。如何训练一个model,然后不用再微调呢,这就是研究动机。
推理
前面讲过了,略
与Visual N-GRAMS的对比

- 大幅度提升,但作者强调了说这不是一个公平的对比(数据集、模型、各种技术。。)
Prompt engineering and ensembling
- 问题1 : 单个词汇是有很大的多义性的,比如remote可能是遥远,也可能是遥控器
- 问题2 : 预训练的时候图像匹配的是一个文本而不是句子
- 为了解决这种distribution gap,使用prompt template,把词汇嵌入到一个句子模板里,简单粗暴就将性能提升了1.3%。且作者发现,如果你提前知道一些信息,对zero-shot的推理还是有帮助的 ,比如在句子模板后面再加上 “a type of pet/food” 来表示这是一个宠物/食物的数据集。
- prompt ensembling,就是多用一些提示模板,做多次推理,将结果综合起来(用了80个提示模板)
ZERO-SHOT CLIP 性能分析
ImageNet预训练的ResNet50作为baseline

- 好消息是,对于一些比较简单的包含物体的数据集(这样可以用文本来描述),Zero-shot大多数会比ResNet50 linear probe要好。
- 对于一些比较难的数据集,比如DTD(纹理)以及CLEVRCounts(计数)的数据集,对于CLIP来说很难(或者说难以描述) ,对于这种难的数据集不给任何标签信息确实强人所难了。比如对于肿瘤分类,如果没有先验知识,对于人来说同样是无法识别的。
Zero-shot and few-shot
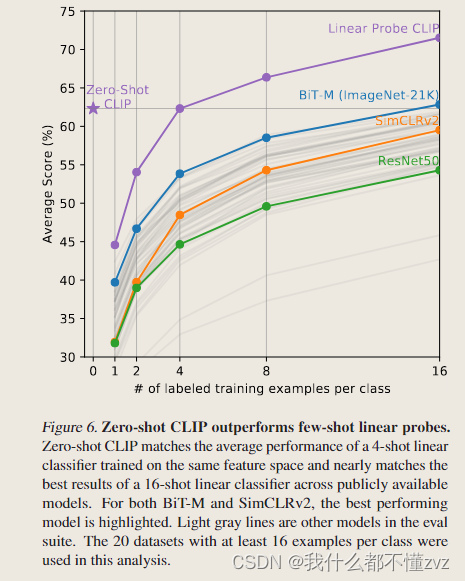
- 该图选取的数据集每个类至少包含16个examples,1-shot ,2-shot的意思是每个类别里选取1、2个样本。然后取平均分类准确度。
- 可以发现,Zero-shot竟然还要比1、2、3-shot的CLIP要好,与4-shot的CLIP持平,但是之后的few-shot的性能要好很多。
- Zero-shot要比BiT要好,BiT是为迁移学习量身定制的,可以算是很强的baseline。
- 对于难的数据集,有一些few-shot还是有必要的
4.2 Representation Learning(全部数据)
- 作者使用linear probe的方法,原因如下:
1)CLIP的任务关注于构建一个高性能的任务,与数据集无关;如果使用fine-tune,原本预训练不太好的模型可能通过微调之后就变好了
2)如果数据集很大并且质量很高,微调会有很多超参选择和技巧,那么对于模型本身的好坏评估就不太准。
Linear probe
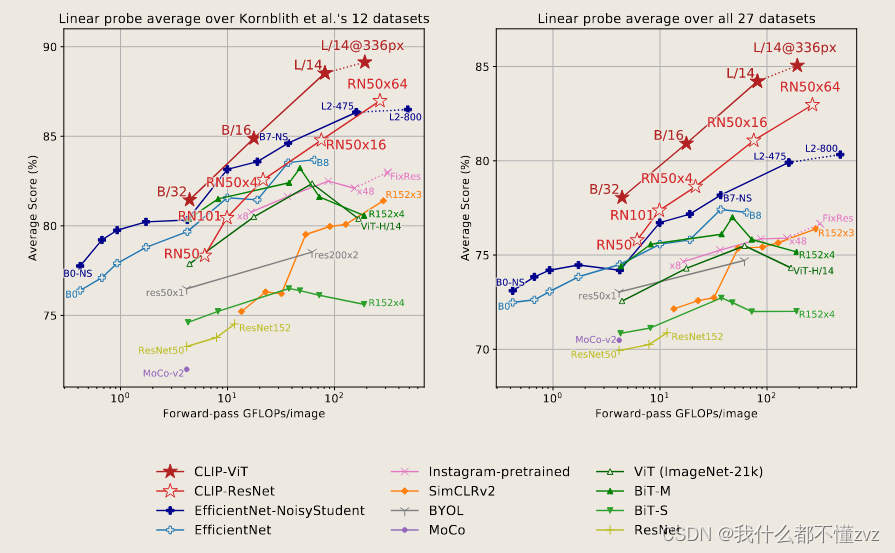
- 左图是在12个datasets上比对,右图是在27个datasets上比对(12个datasets是比较火的一种比对方法,并且作者按时这个dataset和ImageNet的相关性高,能泛化到这上面很正常)
- 可以发现CLIP吊打,CLIP所生成的特征对于泛化到下游任务更具代表性
与SOTA EfficientNet L2 NS抽取features进行对比

- 分别使用两个模型抽取特征去进行linear probe,可以发现CLIP在21个数据集上吊打EfficientNet,说明学习到的特征是更好的
鲁棒性
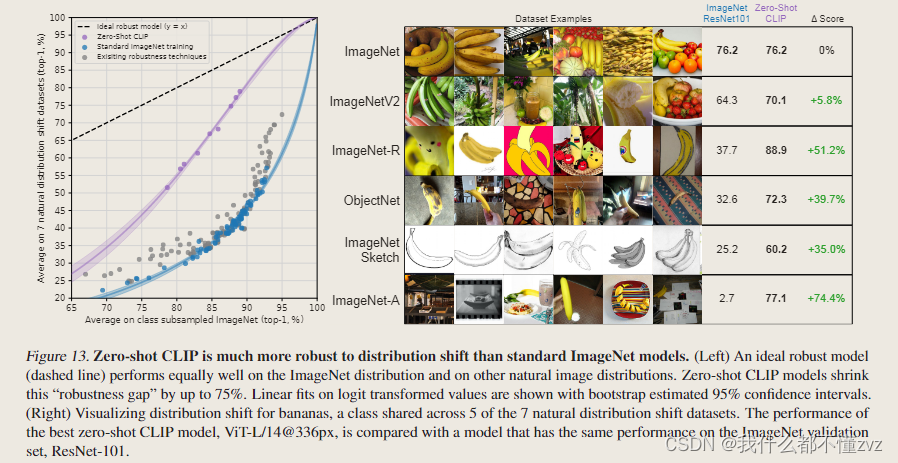
- 主要看右图,CLIP对于香蕉的识别,在不同数据分布的数据集上都表现得很好。但是ImageNet ResNet101就不行,泛化能力极差。















 2381
2381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









