







一、Dify
自从 ChatGPT 横空出世之后,其极高的语言理解和交互能力不仅让人惊呼,ChatGPT不仅能够处理事实性问题,还能理解和生成情感色彩更浓厚的对话内容,能够识别用户的情感倾向,并据此作出相应的回应。这么好的东西怎么能运用到具体私有领域来呢?
例如在学校的场景下,我们需要打造一个学习需求问答系统,问一周的课程,可以回答出:周一需要上 JAVA 课,周二上 Python 课,周三上其他课等,对于类似这种私有化的知识库,如果不对 ChatGPT 微调的话很难精准回答出来。
现在 dify 就可以帮助我们低成本的实现上述的功能 ,使其可以精准回答专业领域的知识。
dify介绍文档: https://docs.dify.ai/v/zh-hans/getting-started/intro-to-dify
下面我们借助 dify 简单实现下上述的场景,由于我们是基本 ChatGPT 作为 LLM 支撑,所以你需要有一个 OpenAI 的 API Key。
二、Dify 服务部署
这里也可以使用官方的服务进行操作,就无需进行本地安装了,使用下面地址:
如果需要本地部署,则进行下下面操作:
这里使用 Docker 部署,安装前确定已经部署好 Docker、Docker-compose。
将项目 clone 下来:
git clone https://github.com/langgenius/dify.git
进入 dify 源代码的 docker 目录,使用 docker 启动:
cd dify/docker
docker-compose up -d
下载好镜像启动后,可以看到相关服务:

如果有防火墙需要放行 80、5432 端口。
下面在浏览器访问 http://部署服务ip ,即可进入到 dify ,刚开始需要设置邮箱、用户名密码信息:

设置完成并登录后即可来到主页面:
三、构建私有化知识库问答应用
3.1 构建本地知识库
现在我们定义下课程信息,将内容放入一个 txt 文本中:
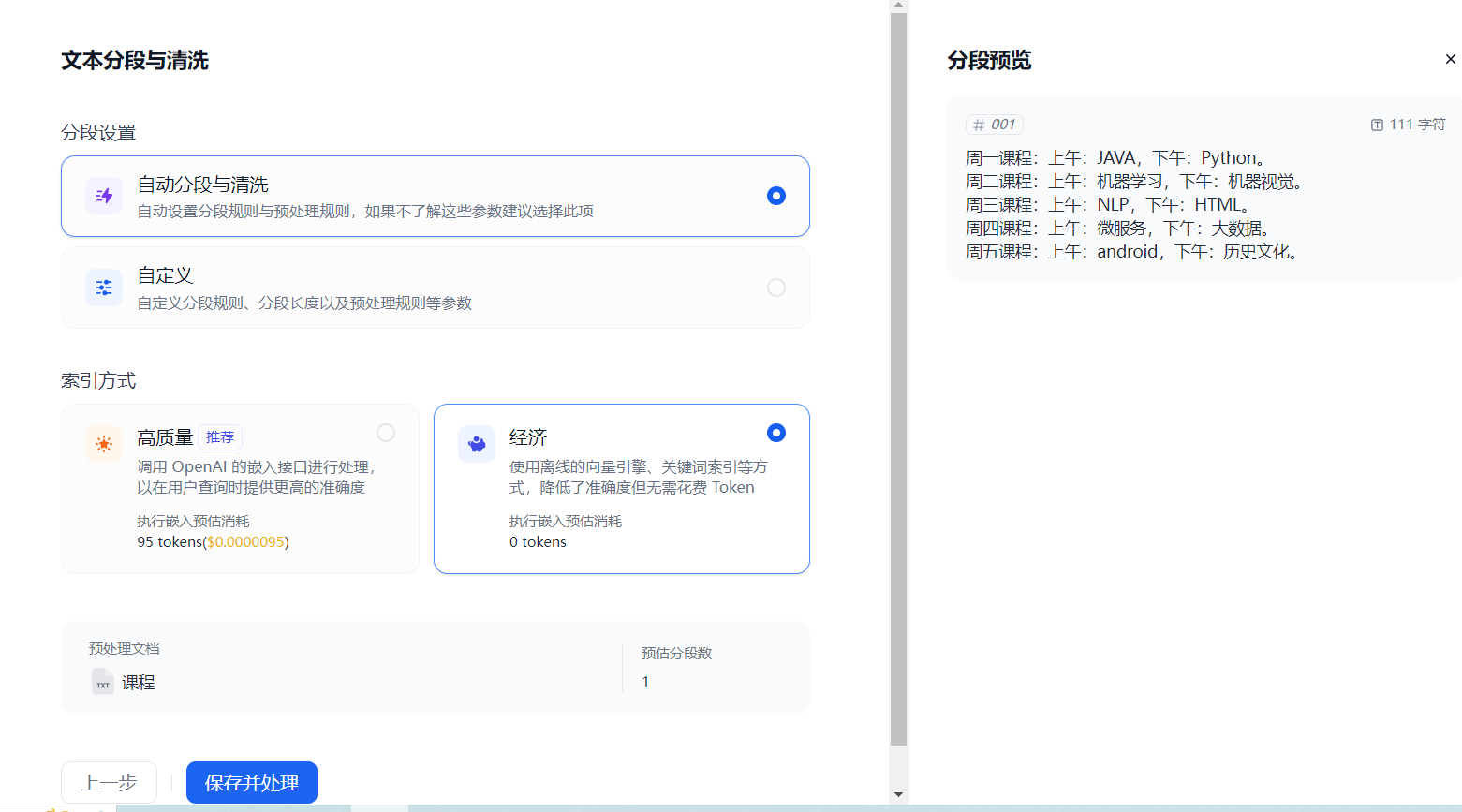
周一课程:上午:JAVA,下午:Python。
周二课程:上午:机器学习,下午:机器视觉。
周三课程:上午:NLP,下午:HTML。
周四课程:上午:微服务,下午:大数据。
周五课程:上午:android,下午:历史文化。
下面点到数据集下,点击创建数据集:
下面将上面的 txt 文本拖入或选中进来:
下面进行文本的分段与清洗,由于内容不多,可以分到一个段中:
下面点击保存就成功创建了一个知识库:
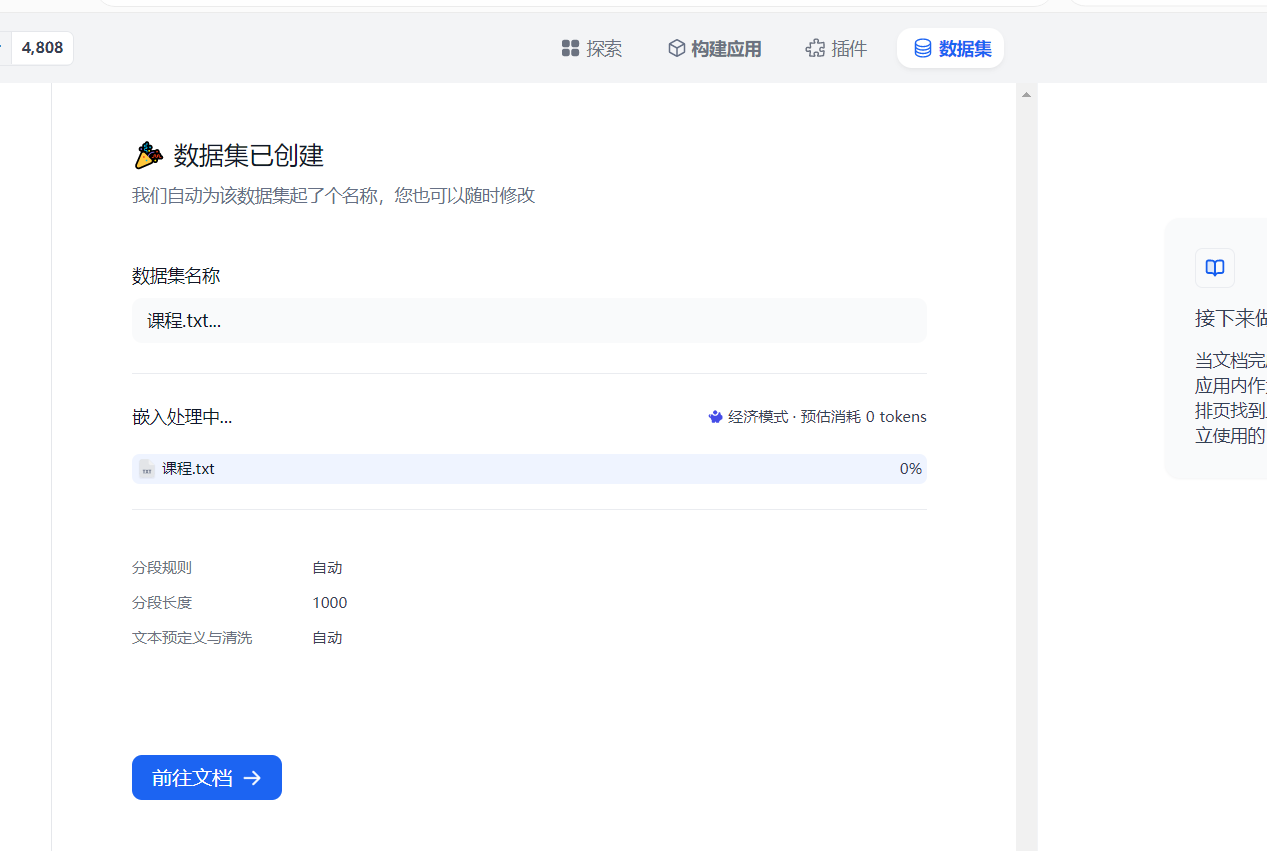
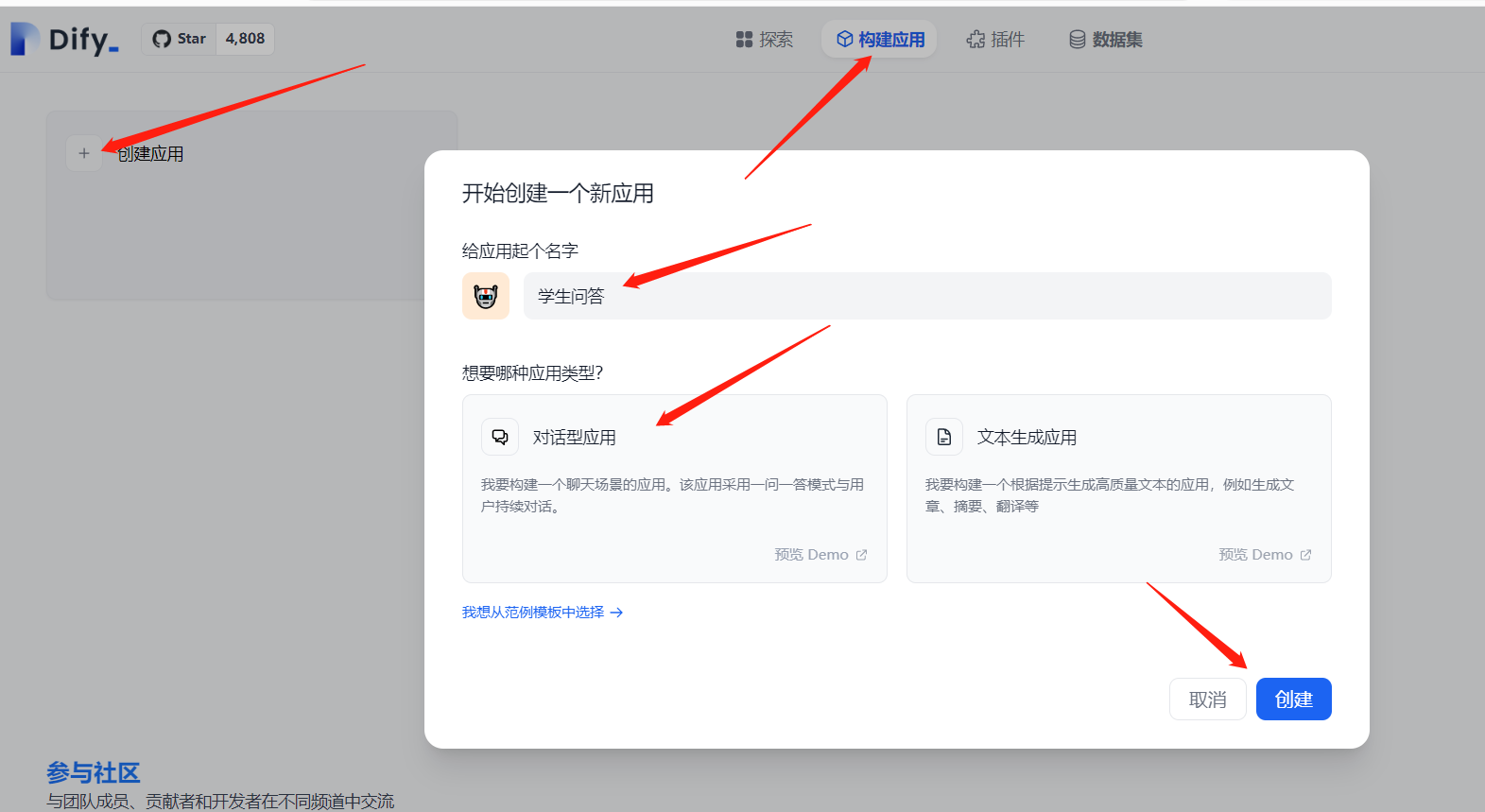
3.2 构建问答应用
下面构建一个问答的应用:
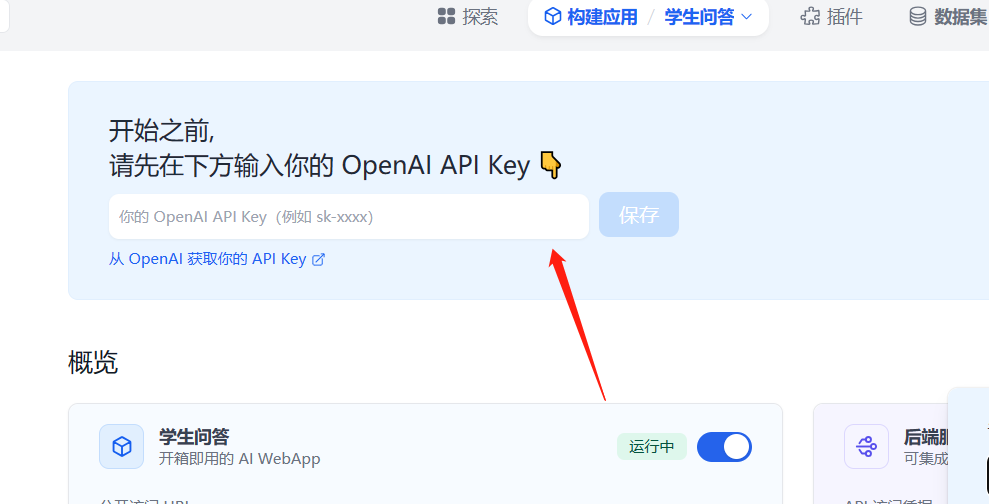
由于是使用 ChatGPT 下面先给它指定一个 API key:
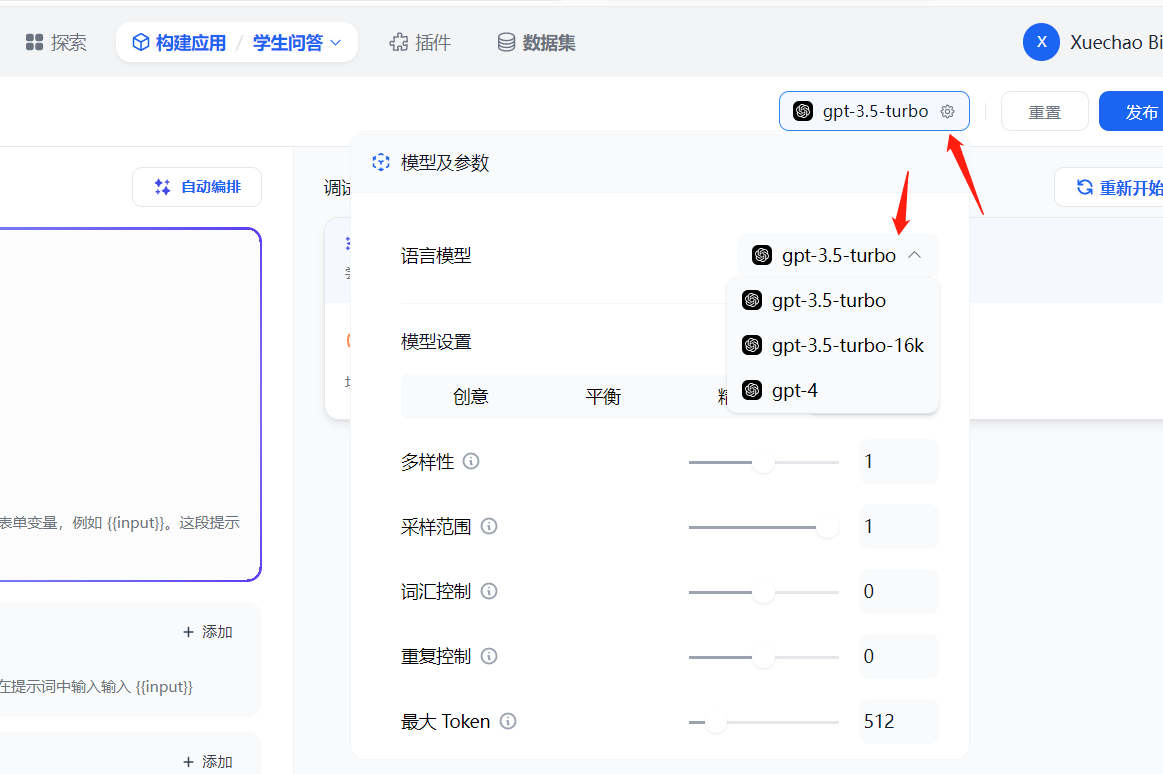
对于 ChatGPT 的版本,这里以 gpt-3.5-turbo 为例:
下面在 提示词编排 中使用上面的知识库:
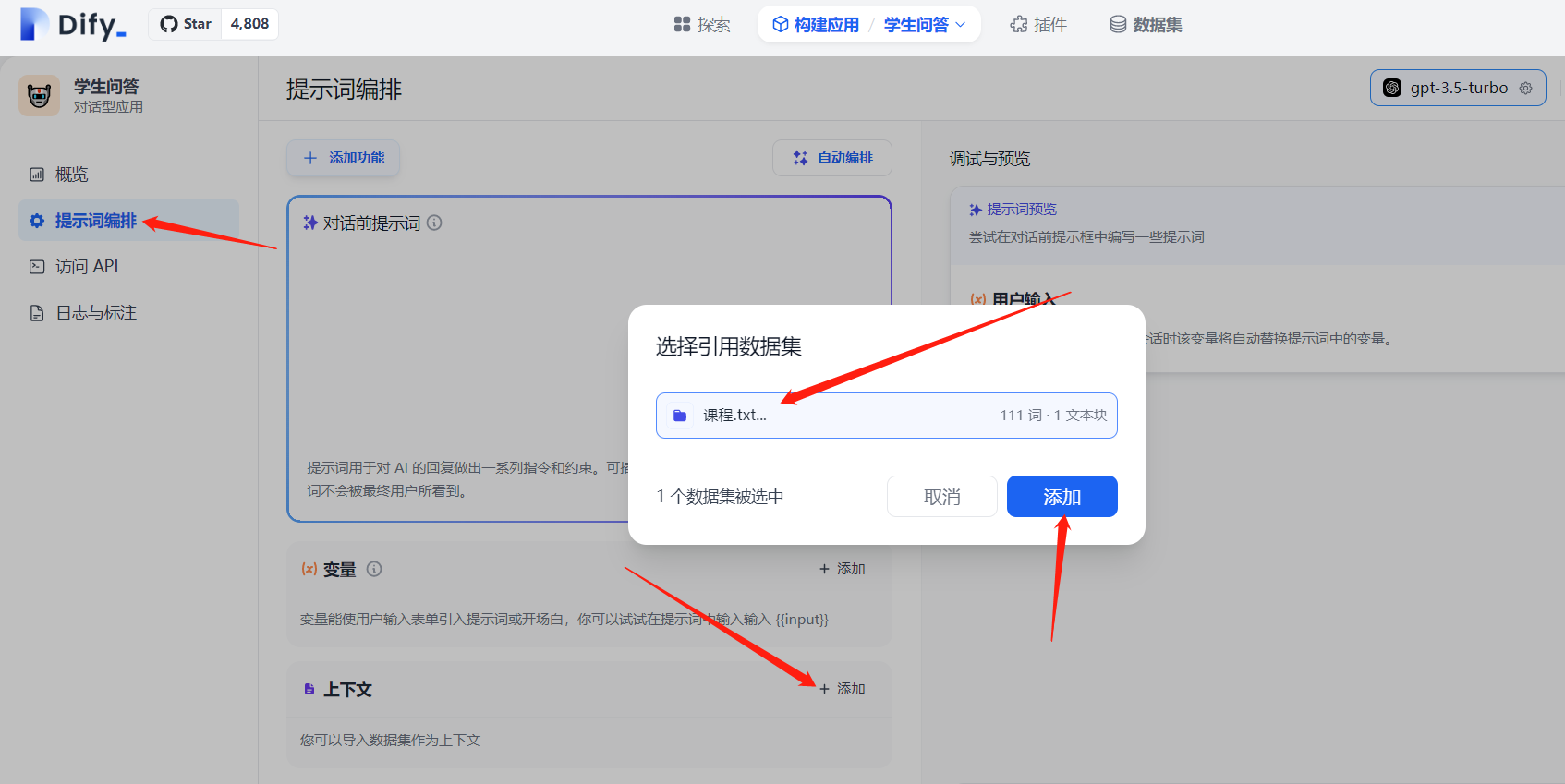
此时可以在右侧进行调试:
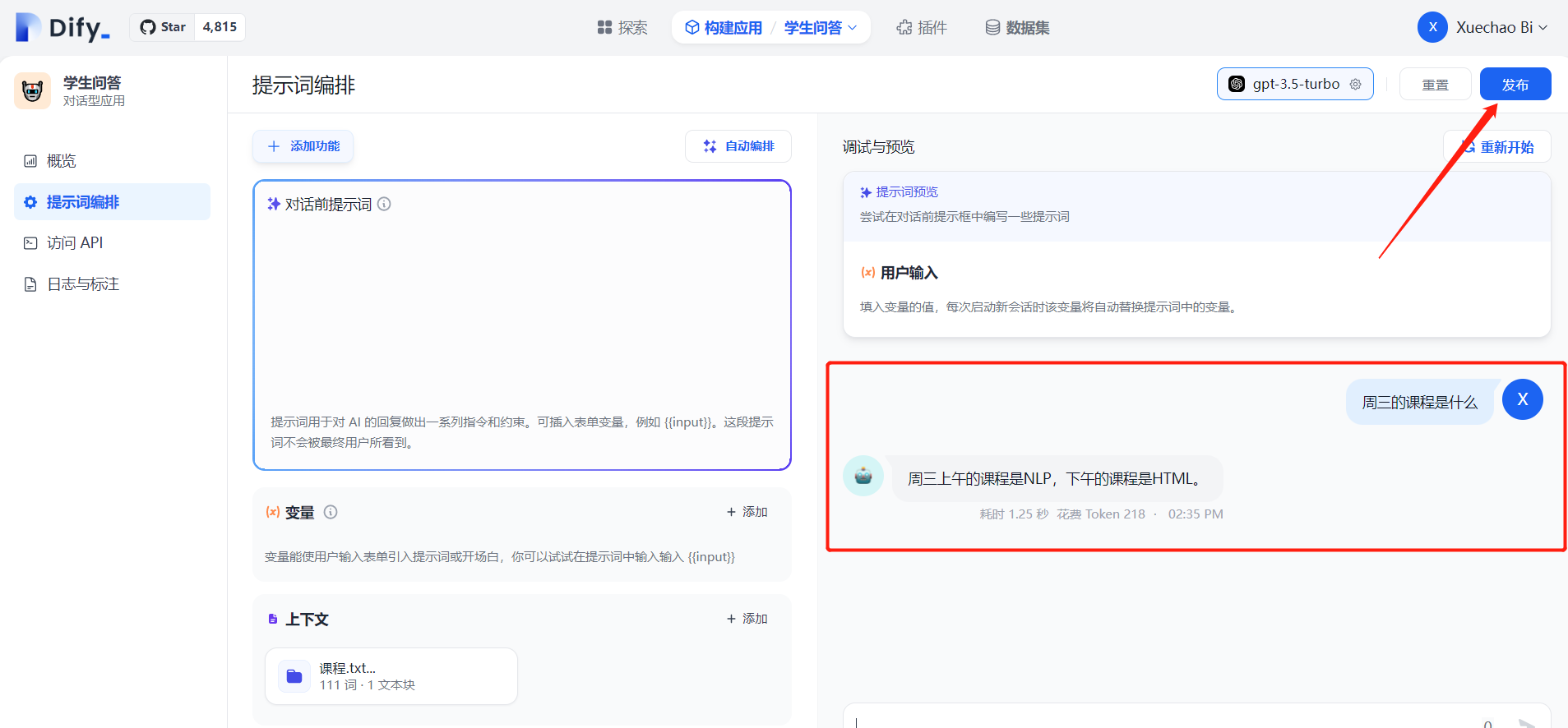
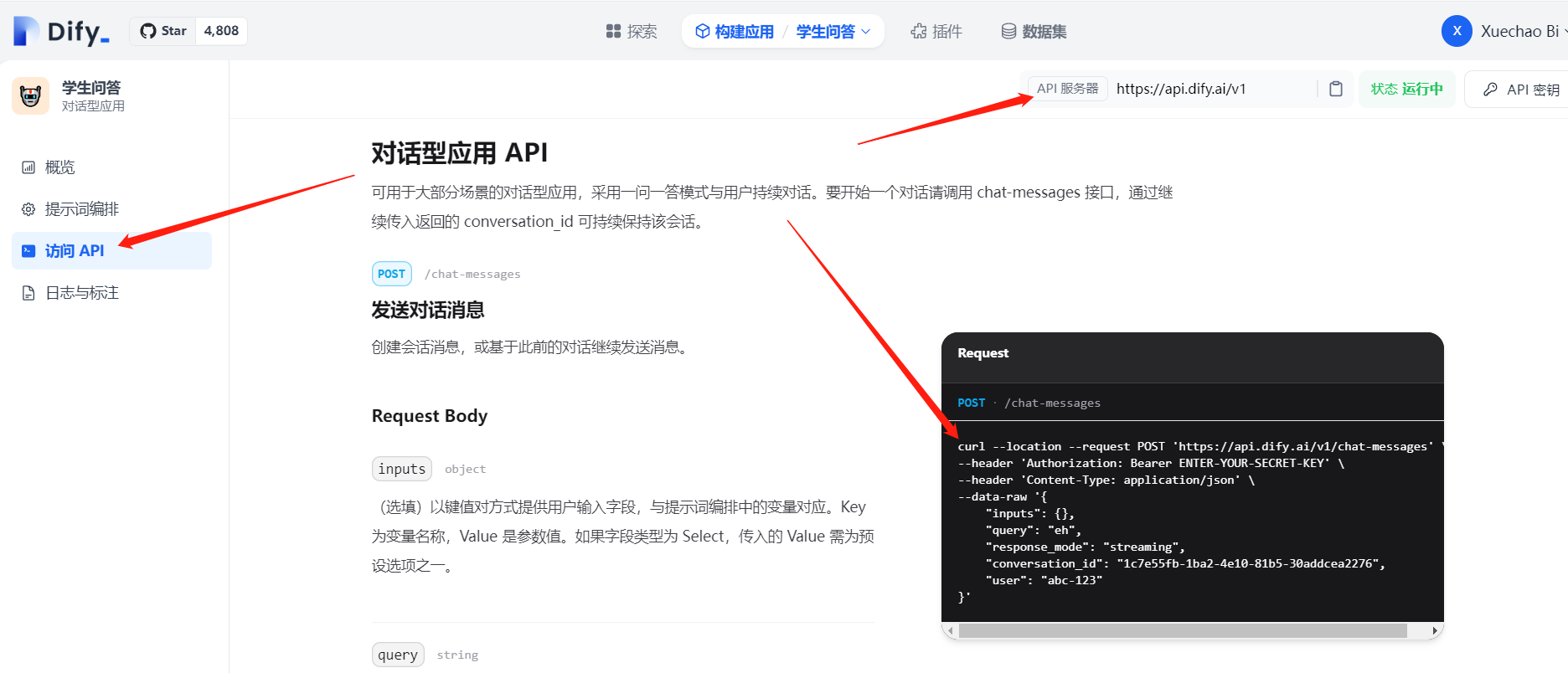
可以看到已经有了我们想要的效果,最后感觉不错的话,一定要点下右上角的发布,下面我们通过 API 的方式去使用它,在访问API 中可以看到API接口地址,并给出了访问示例:
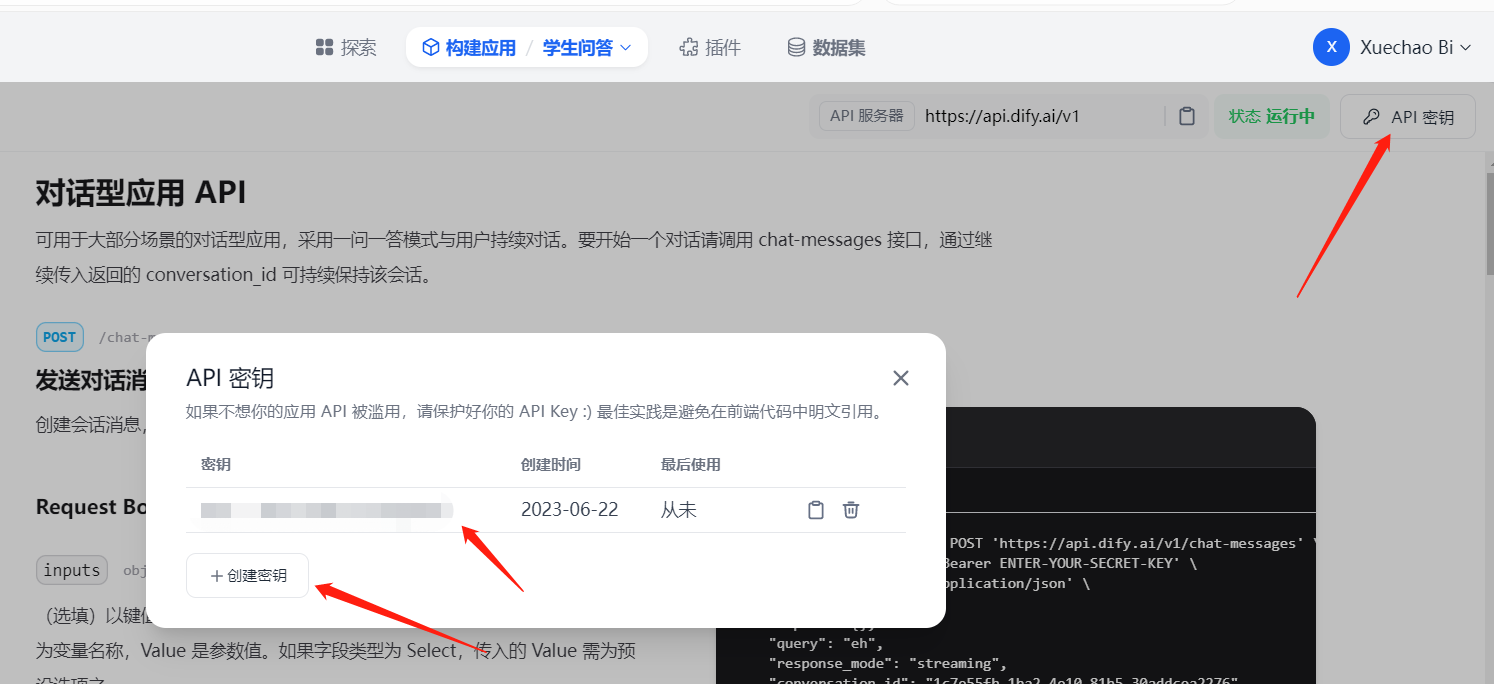
访问前需要生成 API 秘钥,可以点击 API 秘钥 生成:
下面我们就可以使用 PostMan 进行访问了。
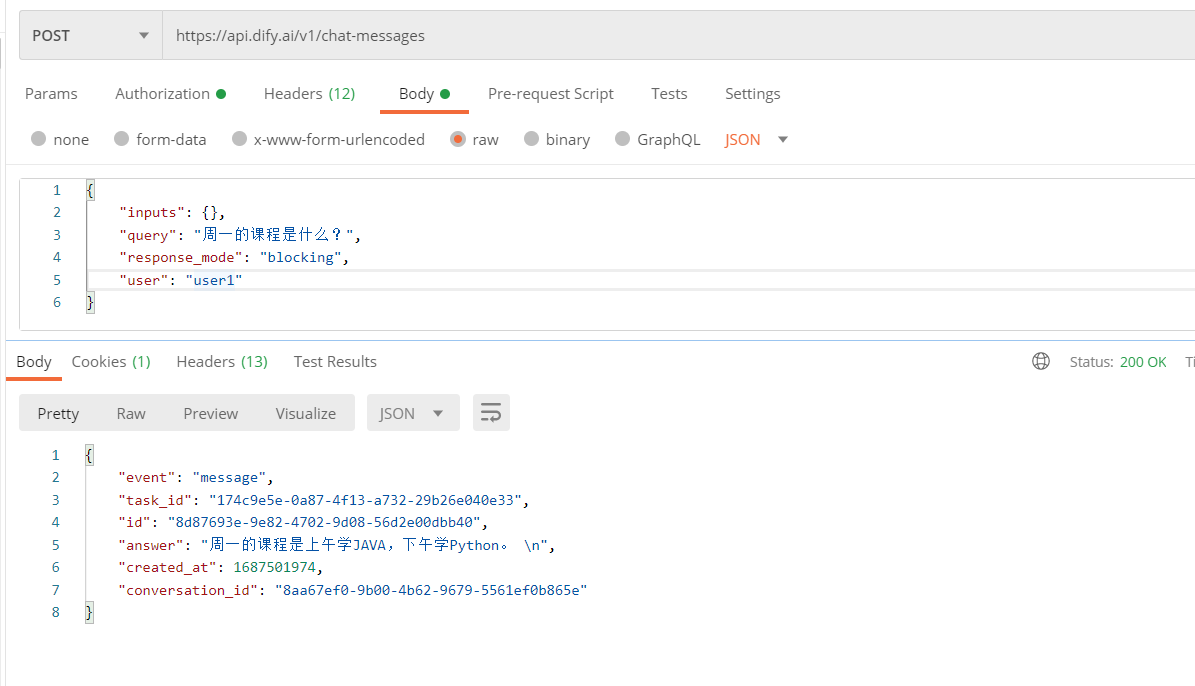
3.3 效果测试
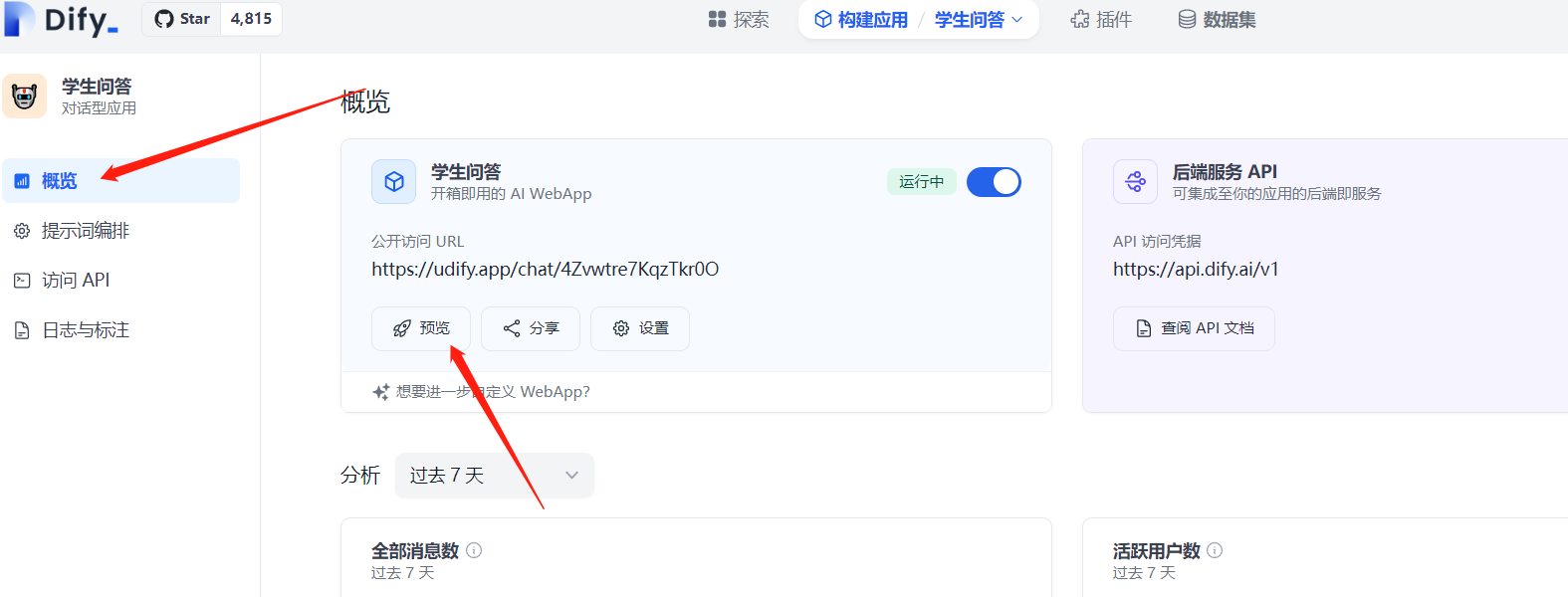
这里使用自带的预览:
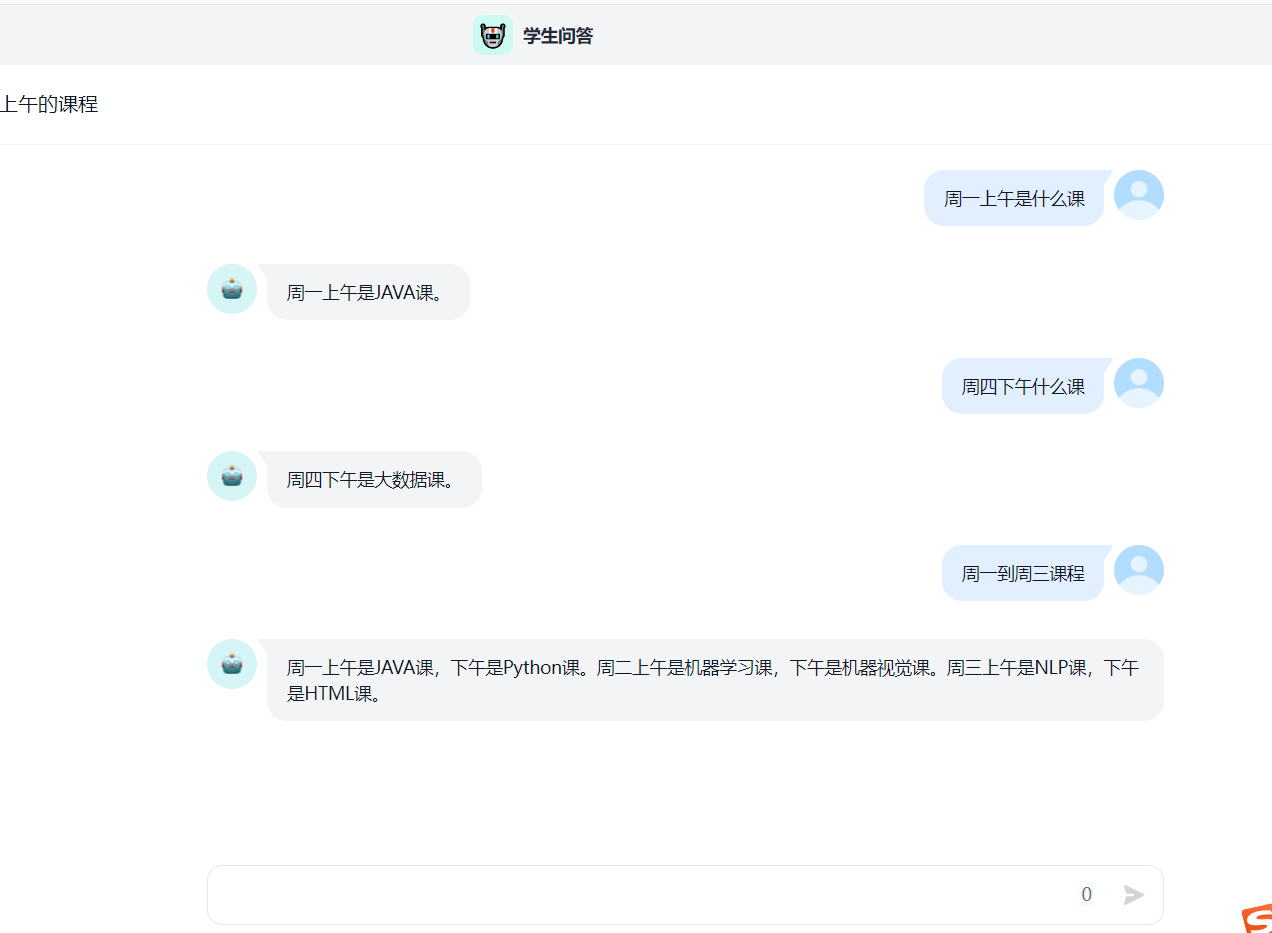
下面就可以进行一些针对性的问答了:


















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











