







原文链接:https://blog.csdn.net/xiaohu2022/article/details/85560788?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
码字不易,欢迎给个赞!
欢迎交流与转载,文章会同步发布在公众号:机器学习算法全栈工程师(Jeemy110)
前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。今天我们要介绍的是DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。本篇文章首先介绍DenseNet的原理以及网路架构,然后讲解DenseNet在Pytorch上的实现。
设计理念
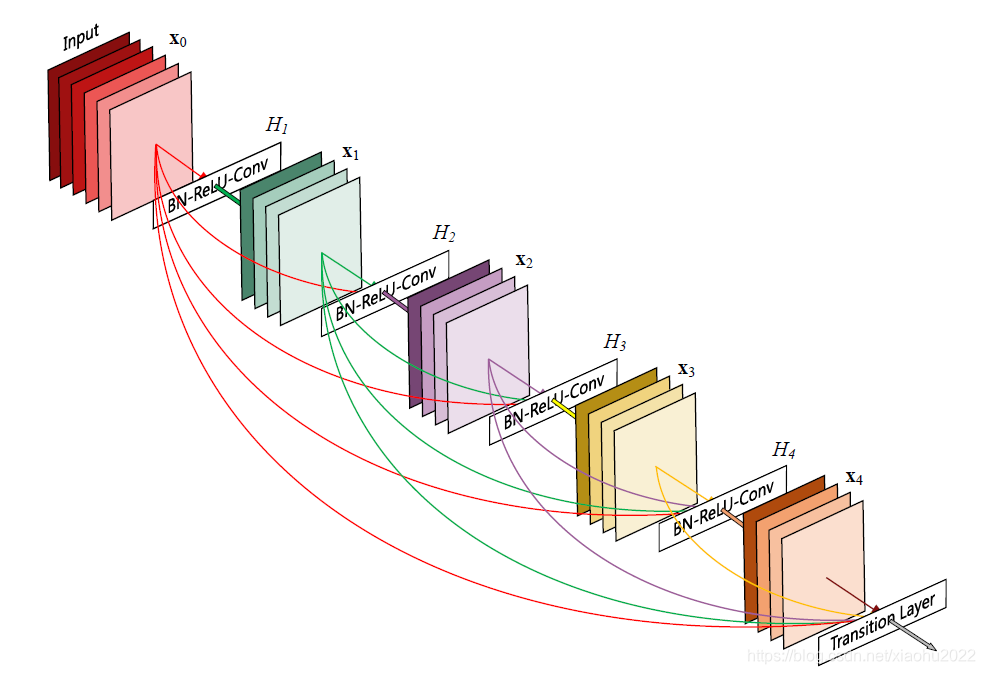
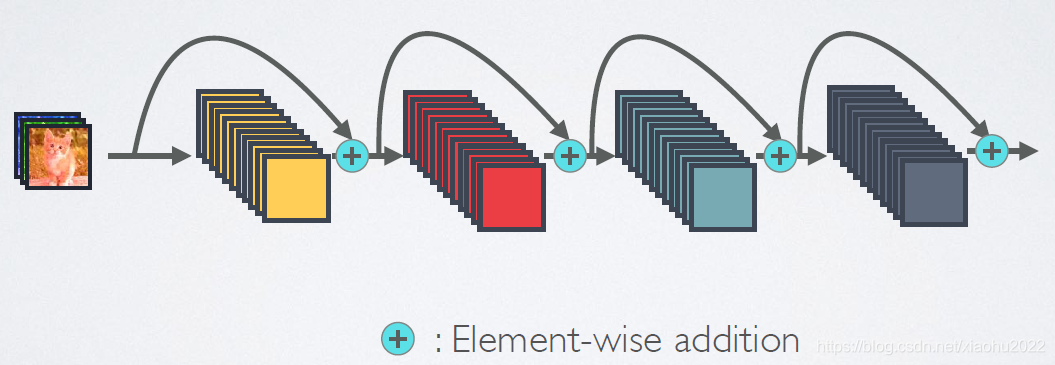
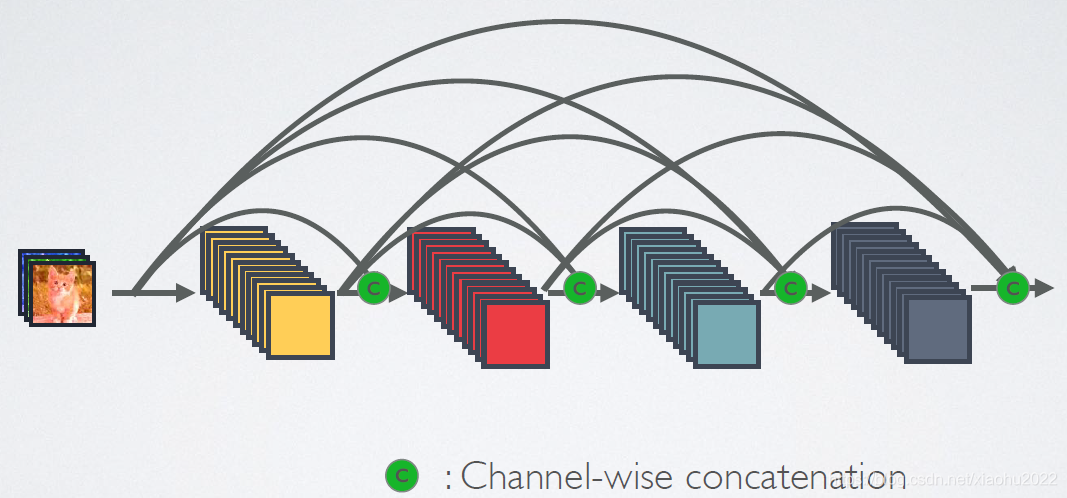
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个
L
L
L
LLL
LLL层的网络,DenseNet共包含
L
(
L
+
1
)
2
L
(
L
+
1
)
2
2
L
(
L
+
1
)
L(L+1)2\frac{L(L+1)}{2}2L(L+1)
L(L+1)22L(L+1)2L(L+1)个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
如果用公式表示的话,传统的网络在
l
l
l
lll
lll层的输出为:
x
l
=
H
l
(
x
l
−
1
)
x
l
=
H
l
(
x
l
−
1
)
x
l
=
H
l
(
x
l
−
1
)
xl=Hl(xl−1)x_l = H_l(x_{l-1})xl=Hl(xl−1)
xl=Hl(xl−1)xl=Hl(xl−1)xl=Hl(xl−1)而对于ResNet,增加了来自上一层输入的identity函数:
x
l
=
H
l
(
x
l
−
1
)
+
x
l
−
1
x
l
=
H
l
(
x
l
−
1
)
+
x
l
−
1
x
l
=
H
l
(
x
l
−
1
)
+
x
l
−
1
xl=Hl(xl−1)+xl−1x_l = H_l(x_{l-1}) + x_{l-1}xl=Hl(xl−1)+xl−1
xl=Hl(xl−1)+xl−1xl=Hl(xl−1)+xl−1xl=Hl(xl−1)+xl−1在DenseNet中,会连接前面所有层作为输入:
x
l
=
H
l
(
[
x
0
,
x
1
,
.
.
.
,
x
l
−
1
]
)
x
l
=
H
l
(
[
x
0
,
x
1
,
.
.
.
,
x
l
−
1
]
)
x
l
=
H
l
(
[
x
0
,
x
1
,
.
.
.
,
x
l
−
1
]
)
xl=Hl([x0,x1,...,xl−1])x_l = H_l([x_0, x_1, ..., x_{l-1}])xl=Hl([x0,x1,...,xl−1])
xl=Hl([x0,x1,...,xl−1])xl=Hl([x0,x1,...,xl−1])xl=Hl([x0,x1,...,xl−1])其中,上面的
H
l
(
⋅
)
H
l
(
⋅
)
H
l
(
⋅
)
Hl(⋅)H_l(\cdot)Hl(⋅)
Hl(⋅)Hl(⋅)Hl(⋅)代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里
l
l
l
lll
lll层与
l
−
1
l
−
1
l
−
1
l−1l-1l−1
l−1l−1l−1层之间可能实际上包含多个卷积层。
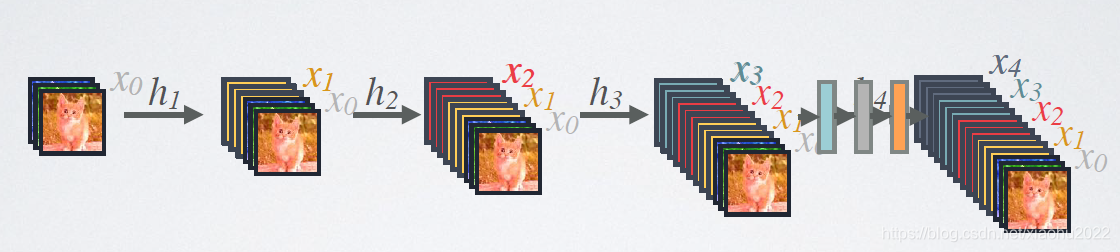
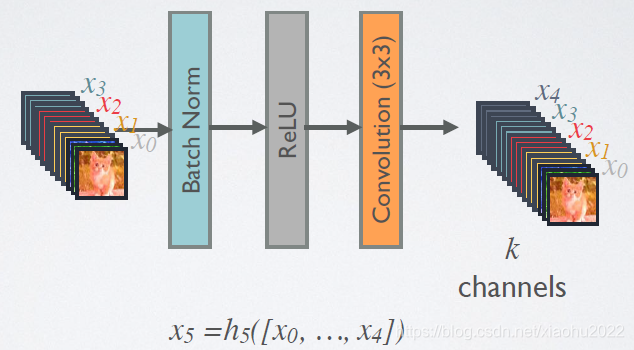
DenseNet的前向过程如图3所示,可以更直观地理解其密集连接方式,比如 h 3 h 3 h 3 h3h_3h3 h3h3h3的输入不仅包括来自 h 2 h 2 h 2 h2h_2h2 h2h2h2的 x 2 x 2 x 2 x2x_2x2 x2x2x2,还包括前面两层的 x 1 x 1 x 1 x1x_1x1 x1x1x1和 x 2 x 2 x 2 x2x_2x2 x2x2x2,它们是在channel维度上连接在一起的。
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。
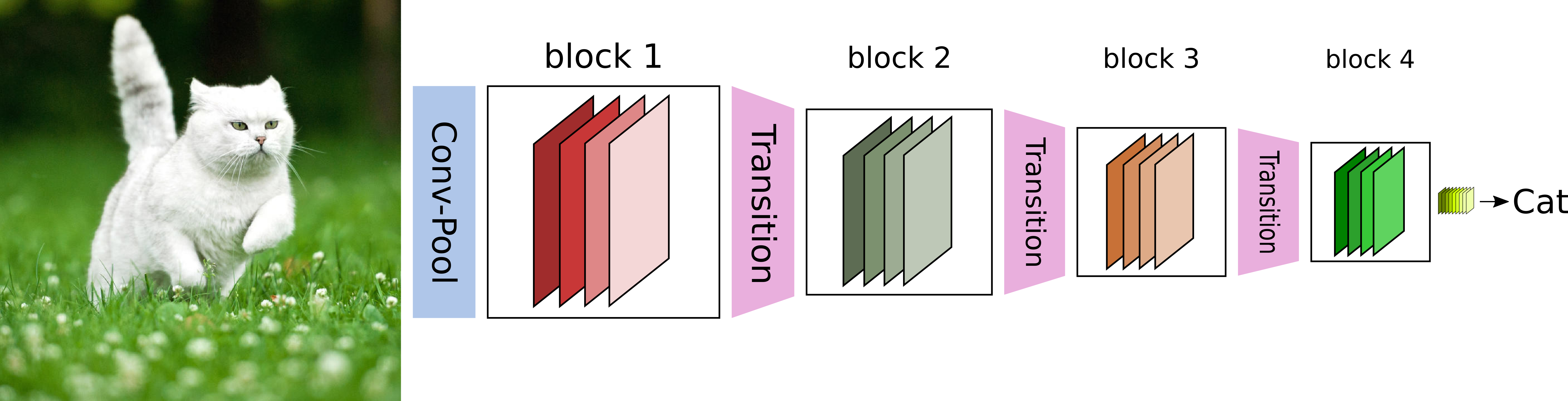
网络结构
如前所示,DenseNet的网络结构主要由DenseBlock和Transition组成,如图5所示。下面具体介绍网络的具体实现细节。
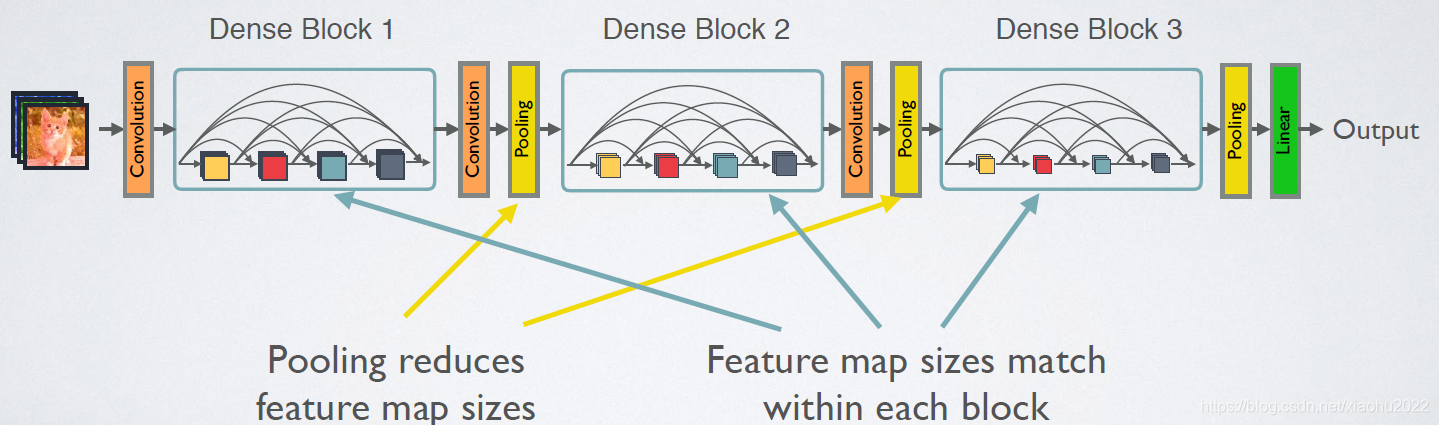
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数
H
(
⋅
)
H
(
⋅
)
H
(
⋅
)
H(⋅)H(\cdot)H(⋅)
H(⋅)H(⋅)H(⋅)采用的是BN+ReLU+3x3 Conv的结构,如图6所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出
k
k
k
kkk
kkk个特征图,即得到的特征图的channel数为
k
k
k
kkk
kkk,或者说采用
k
k
k
kkk
kkk个卷积核。
k
k
k
kkk
kkk在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的
k
k
k
kkk
kkk(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为
k
0
k
0
k
0
k0k_0k0
k0k0k0,那么
l
l
l
lll
lll层输入的channel数为
k
0
+
k
(
l
−
1
)
k
0
+
k
(
l
−
1
)
k
0
+
k
(
l
−
1
)
k0+k(l−1)k_0+k(l-1)k0+k(l−1)
k0+k(l−1)k0+k(l−1)k0+k(l−1),因此随着层数增加,尽管
k
k
k
kkk
kkk设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有
k
k
k
kkk
kkk个特征是自己独有的。
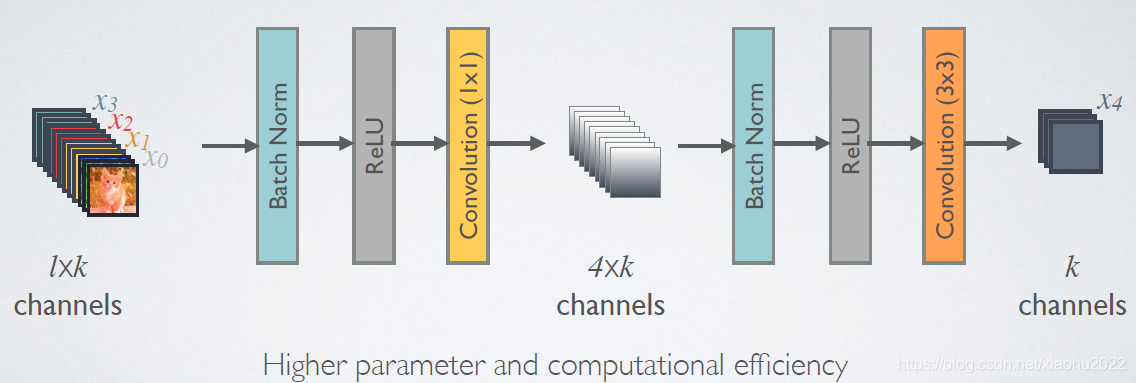
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 4 k 4 k 4 k 4k4k4k 4k4k4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m m m mmm mmm,Transition层可以产生 ⌊ θ m ⌋ ⌊ θ m ⌋ ⌊ θ m ⌋ ⌊θm⌋\lfloor\theta m\rfloor⌊θm⌋ ⌊θm⌋⌊θm⌋⌊θm⌋个特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] θ ∈ ( 0 , 1 ] θ ∈ ( 0 , 1 ] θ∈(0,1]\theta \in (0,1]θ∈(0,1] θ∈(0,1]θ∈(0,1]θ∈(0,1]是压缩系数(compression rate)。当 θ = 1 θ = 1 θ = 1 θ=1\theta=1θ=1 θ=1θ=1θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 θ = 0.5 θ = 0.5 θ=0.5\theta=0.5θ=0.5 θ=0.5θ=0.5θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为 32 × 3232 × 3232 × 32 32×3232\times 3232×32 32×3232×3232×32,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3x3卷积(stride=1),卷积核数为16(对于DenseNet-BC为 2 k 2 k 2 k 2k2k2k 2k2k2k)。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为 32 × 3232 × 3232 × 32 32×3232\times 3232×32 32×3232×3232×32, 16 × 1616 × 1616 × 16 16×1616\times 1616×16 16×1616×1616×16和 8 × 88 × 88 × 8 8×88\times 88×8 8×88×88×8,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置: L = 40 , k = 12 { L = 40 , k = 12 } L = 40 , k = 12 {L=40,k=12}\{L=40, k=12\}{L=40,k=12} L=40,k=12{L=40,k=12}L=40,k=12, L = 100 , k = 12 { L = 100 , k = 12 } L = 100 , k = 12 {L=100,k=12}\{L=100, k=12\}{L=100,k=12} L=100,k=12{L=100,k=12}L=100,k=12, L = 40 , k = 24 { L = 40 , k = 24 } L = 40 , k = 24 {L=40,k=24}\{L=40, k=24\}{L=40,k=24} L=40,k=24{L=40,k=24}L=40,k=24。而对于DenseNet-BC结构,使用如下三种网络配置: L = 100 , k = 12 { L = 100 , k = 12 } L = 100 , k = 12 {L=100,k=12}\{L=100, k=12\}{L=100,k=12} L=100,k=12{L=100,k=12}L=100,k=12, L = 250 , k = 24 { L = 250 , k = 24 } L = 250 , k = 24 {L=250,k=24}\{L=250, k=24\}{L=250,k=24} L=250,k=24{L=250,k=24}L=250,k=24, L = 190 , k = 40 { L = 190 , k = 40 } L = 190 , k = 40 {L=190,k=40}\{L=190, k=40\}{L=190,k=40} L=190,k=40{L=190,k=40}L=190,k=40。这里的 L L L LLL LLL指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。对于普通的 L = 40 , k = 12 { L = 40 , k = 12 } L = 40 , k = 12 {L=40,k=12}\{L=40, k=12\}{L=40,k=12} L=40,k=12{L=40,k=12}L=40,k=12网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。
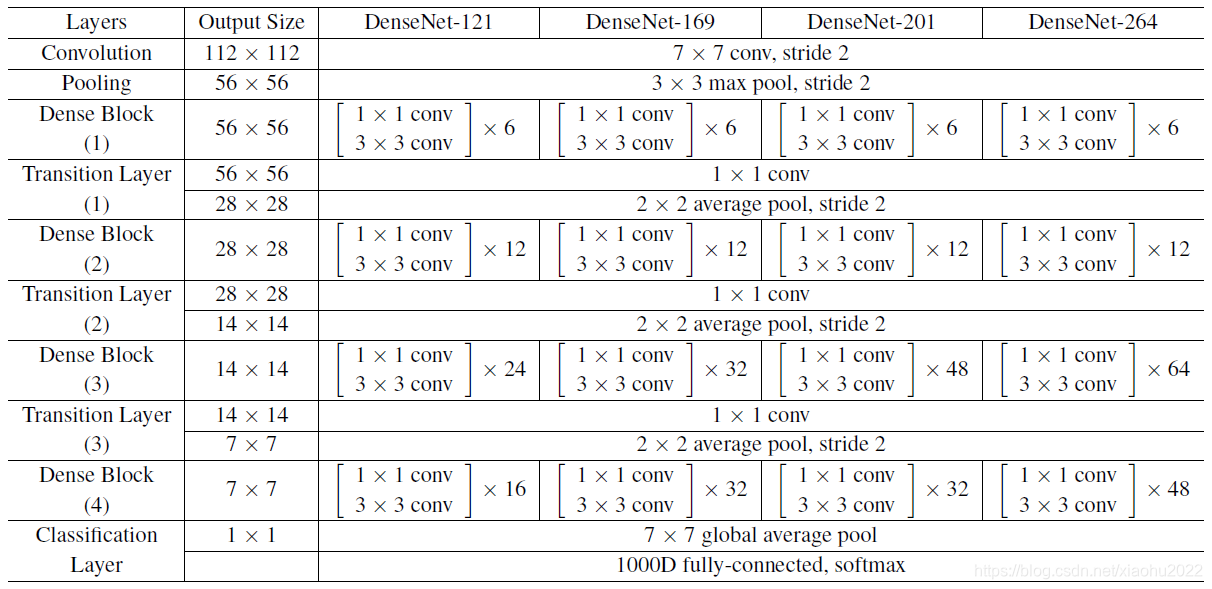
对于ImageNet数据集,图片输入大小为 224 × 224224 × 224224 × 224 224×224224\times 224224×224 224×224224×224224×224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层(卷积核数为 2 k 2 k 2 k 2k2k2k 2k2k2k),然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:
实验结果及讨论
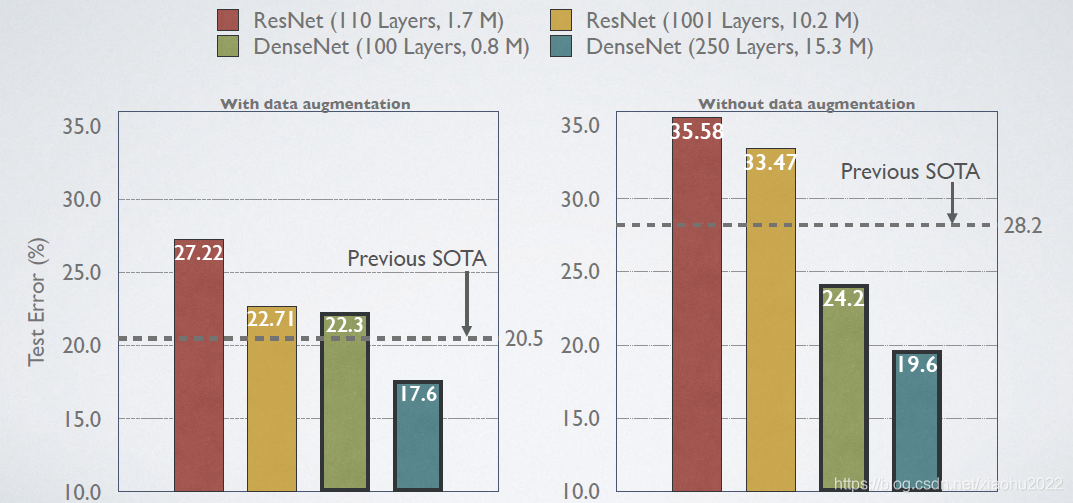
这里给出DenseNet在CIFAR-100和ImageNet数据集上与ResNet的对比结果,如图8和9所示。从图8中可以看到,只有0.8M的DenseNet-100性能已经超越ResNet-1001,并且后者参数大小为10.2M。而从图9中可以看出,同等参数大小时,DenseNet也优于ResNet网络。其它实验结果见原论文。
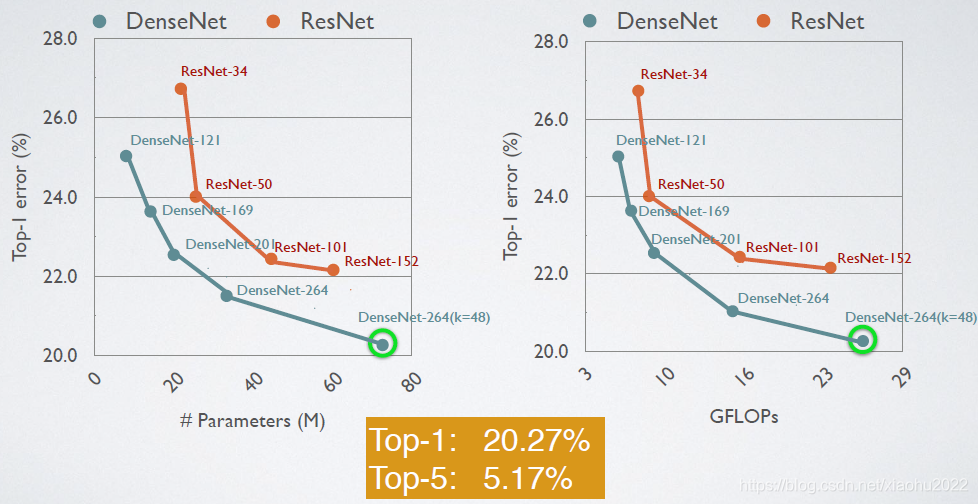
综合来看,DenseNet的优势主要体现在以下几个方面:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
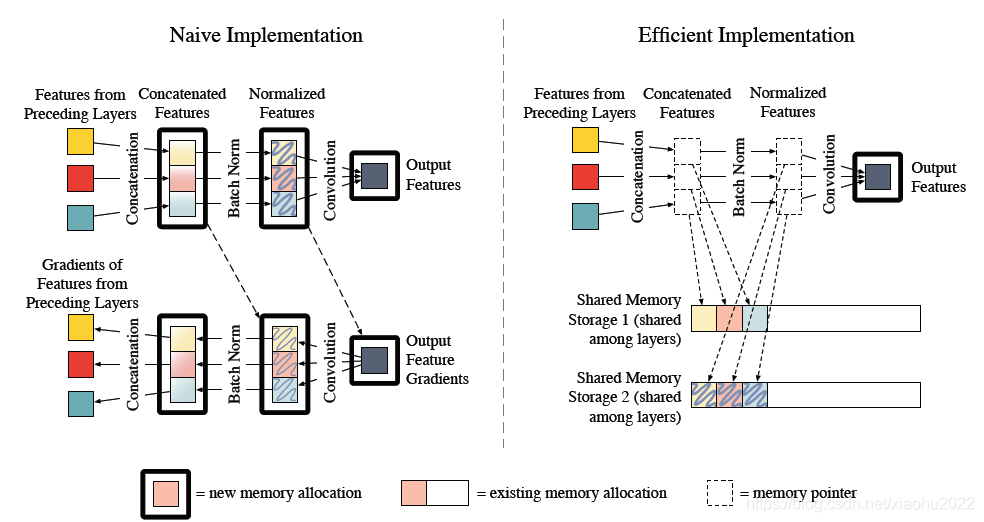
要注意的一点是,如果实现方式不当的话,DenseNet可能耗费很多GPU显存,一种高效的实现如图10所示,更多细节可以见这篇论文Memory-Efficient Implementation of DenseNets。不过我们下面使用Pytorch框架可以自动实现这种优化。














 2077
2077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









