







原文链接:https://zhuanlan.zhihu.com/p/34788333?utm_source=ZHShareTargetIDMore
SPP背景
传统CNN所需要的固定维度输入这一限制,是造成任意尺度的图片识别准确率低的原因.传统的CNN需要先对训练图片进行处理,使其维度相同.具体有两种做法,裁剪(cropping)和扭曲(warping).如下图.
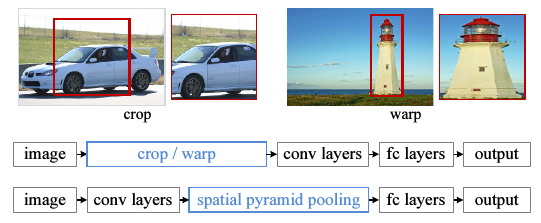
缺点是:裁剪了的区域可能并不包含整个物体,而扭曲则会带入几何方面的失真.另外,即使是裁剪和扭曲,我们仍然是认为规定了一个输入尺度,而真实的物体尺度很多,这个固定维度的输入直接忽略掉了这一点.
为何非要给CNN限制一个固定维度的输入?作者说,CNN就分两块,卷积层和全连层(fully-connected layer),卷积层的输出是特征图(feature map),这个特征图反映出了原始输入图片中对filter(卷积核)激活的空间信息.卷积这一步是不需要固定大小的.是最后的全连层带来的这个限制.
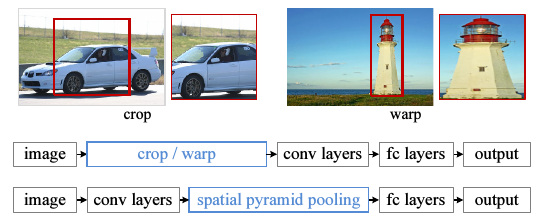
作者针对这个问题,提出了在CNN的最后一个卷积层之后,加入一个SPP层,也就是空间金字塔池化,对之前卷积得到的特征进行”整合”(aggregation),然后得到一个固定长度的特征向量,再传到全连层去.如下图.


SPP是词袋模型(Bag-of-Words)的扩展.为什么说是扩展?词袋模型没有特征的空间信息(就像它只能统计一个句子中每个单词的词频,而不能记录词的位置信息一样).在深层CNN里加入SPP会有3个优势: 1) 相比之前的滑动窗池化(sliding window pooling),SPP可以对不同维度输入得到固定长度输出. 2) SPP使用了多维的spatial bins(我的理解就是多个不同大小的窗),而滑动窗池化只用了一个窗. 3) 因为输入图片尺度可以是任意的,SPP就提取出了不同尺度的特征.作者说这3点可以提高深度网络的识别准确率.
SPP-net既然只在网络的最后几层(深层网络)中加入,而本质上就是池化,所以它可以加入到其他CNN模型中,比如AlexNet.作者的实验表明,加入了SPP的AlexNet效果确实提升了.作者认为SPP应该能提升更复杂的网络的能力.
SPP原理
在输入不同尺寸的图片,经过卷积层会输出的不同大小的feature map.把最以后一次卷积后的池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin(M个不同维度的pyramid),那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了,第二个产生4x256维向量,SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
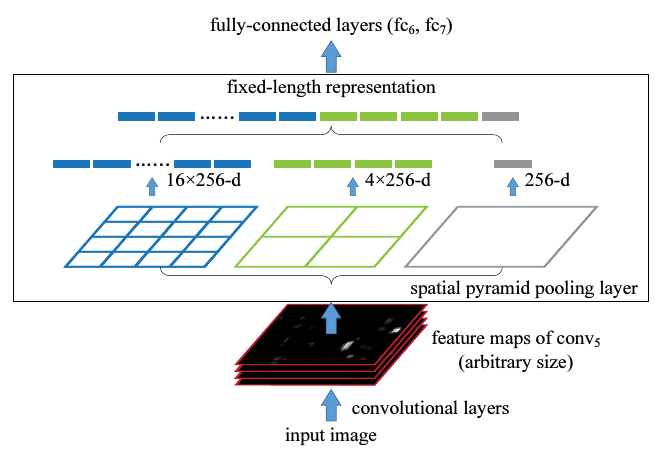

具体地,在一个CNN里,把最以后一次池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin,那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了.SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像上图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做max pooling后,出来的特征就是(16+4+1)x256 维度。如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256维度。这样就实现了不管图像尺寸如何 池化n 的输出永远是 (16+4+1)x256 维度。SSP后的全连接是由上图绿色,蓝色,灰色产生的向量拼接而成。
实际运用中只需要根据全连接层的输入维度要求设计好空间金字塔即可。
训练
###单一大小训练
如果一个图片大小固定,比如224x224,那么我们就能计算出它的池化窗口(bin)的大小.比如经过第五个卷积层conv5之后得到的feature map是a x a(13x13),如果金字塔大小n x n,那么窗口大小就是ceil(a / n), 步长是floor(a / n).我们可以用ll个不同大小的窗口,比如3x3, 2x2, 1x1.然后把这ll个输出连接起来,送入之后的全连层.下图是这样3个窗口和最后的全连层的的配置文件.


###多个大小的训练
我们再考虑一种输入大小(180x180),两种大小也算是”多个大小训练”啊.这个180x180的直接取224x224图片的按尺度缩放图片,这两张图除了解析度不同别的都相同.180x180的图片经过第五层卷积后的feature map是10x10,这时我们依然用刚才的公式,窗口大小就是ceil(a / n), 步长是floor(a / n),这样的话后得到的特征长度与之前的224x224的特征长度相同.举个例子,如果金字塔是3*3,即n=3,那么对于第一种大小,窗口长为5,步长4,第二中大小,窗口4,步长3,如下图.
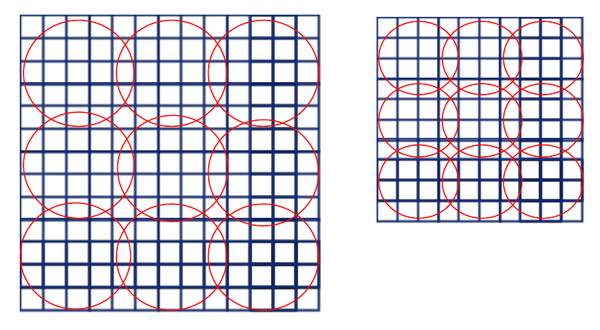

红色区域代表窗口,经过最大池化后,两张图得到的特征向量长度均为3x3=9.所以180的网络和224的网络参数完全一样,于是SPP训练阶段,对于这两种网络只要共享参数即可.
实际训练时,为了减少不停转换网络带来的开销,需要使用全部数据一次训练一个网络,然后再换成第二个,作为一次迭代.所以作者根本没有实现训练不同大小输入的CNN的BP算法,只是针对各种各样大小不同的输入,定义出不同的网络,但这些网络实际上参数都相同,于是就可以用现有工具来训练.
这个是训练阶段,需要不停转化网络,当训练好模型用于测试时,只要输入图片就行了.
该文主要参考:
[论文笔记]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition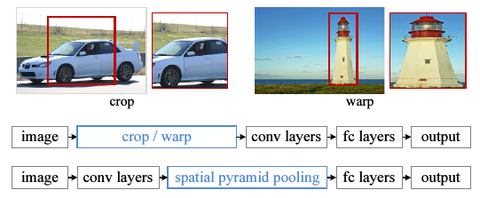 晓雷:SPPNet-引入空间金字塔池化改进RCNN
晓雷:SPPNet-引入空间金字塔池化改进RCNN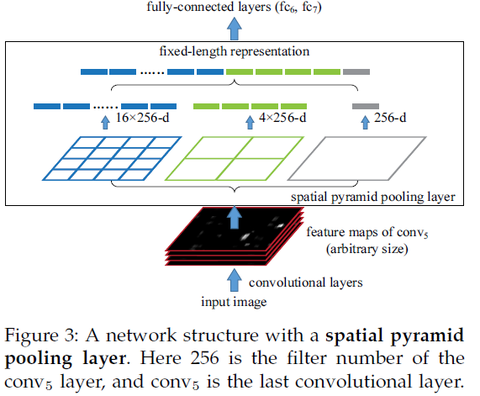














 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









