







 SPP(Spatial Pyramid Pooling)解决了卷积神经网络中因图像尺寸变化导致的特征图大小不一的问题,通过多尺度池化窗口实现固定长度特征输出,增强模型对不同尺度图像的鲁棒性。
SPP(Spatial Pyramid Pooling)解决了卷积神经网络中因图像尺寸变化导致的特征图大小不一的问题,通过多尺度池化窗口实现固定长度特征输出,增强模型对不同尺度图像的鲁棒性。
1.为什么会出现SPP结构,其作用是什么?
通过Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文可以基本了解其作用和基本结构,
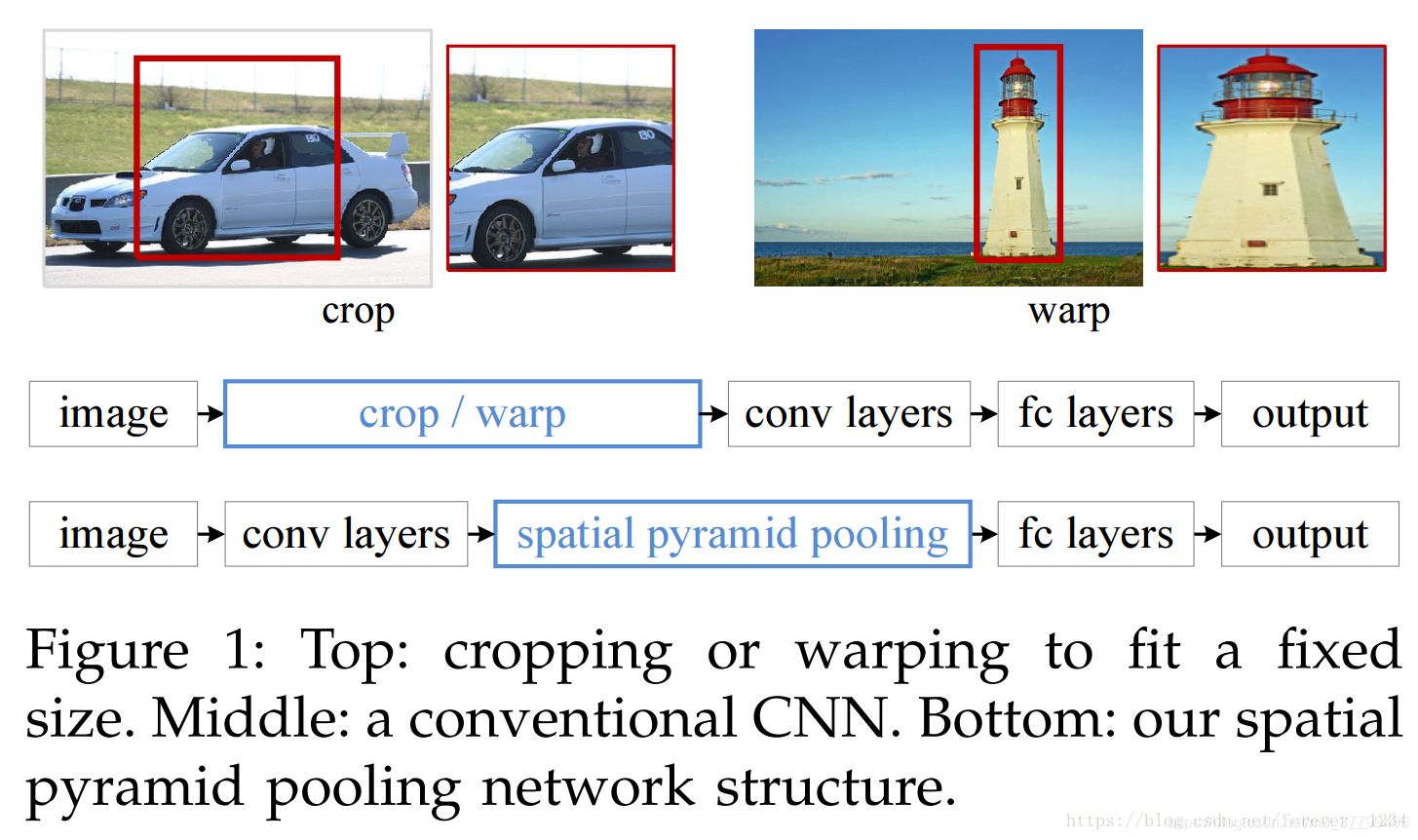
从图中可以看到传统的操作是先将原图crop(裁剪/变换,也就是类似resize操作),直接送入卷积层,然后进入全连接分类。但是每幅图像中目标物体位置和大小难以保持一致,crop必然会影响图像特征的准确性。
由于卷积层与全连接层连接处必须保持固定的维度,若是不crop成统一大小,提取的特征图大小就不一样,没法送进全连接层,所以需要一种新的结构来解决这个问题,SPP就是最合适的方法。如图所示只需要将其加到卷积层后面就可以解决这个问题,其作用就是将不同的特征图转化为固定的特征图,不需要提前crop图像了。
2.其结构如下图所示:
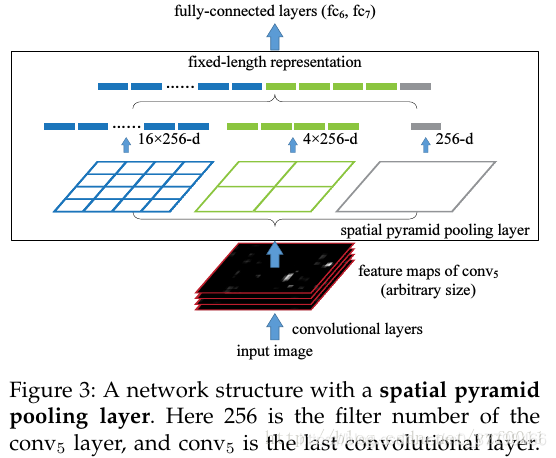
其使用多个窗口(pooling window) 可以同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征,其可行性需要进行证明。证明前首先了解pooling层的计算过程。
设输入的特征图大小为W*H
池化层滤波器大小为F*F
步长为S
用零填充个数P
则池化后的特征图宽为N=(W-F+2P)/S+1
同理可得高;
总结:特征图输出大小=[(输入大小 - 滤波器大小 + 2*P)/步长]+1
接着证明SPP的可行性:
首先由定理: 任何一个数都可以写成若干个数的平方和可得:
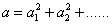
故设输入特征图尺寸为WxH,由于输入图像尺寸是多样的,所以输入特征图尺寸也是不同的;同时设输入特征图个数为C,则全连接层的输出为Cxf, 也就是我们每个特征图要得到f个特征。
我们想要证明不同大小的特征图都可以通过多个池化层池化得到的f个特征,故就是证明
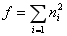
其中n=1,2,3…;首先设池化层滤波器大小为 (p1,p2),在计算是向上取整;
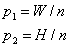
设对应的步长(t1,t2分别水平和竖直的步长),计算时向下取整;
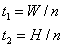
设池化层一种滤波器水平移动时的特征数为f1,同时设k是通过向下取整得出整数,即为步长大小;
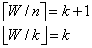
则可得出下式,其中 l=[0,1]
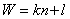
即证明l在两种情况下都符合条件
当l=1时,特征图的宽不可被n整除,p1需要向上取整故为k+1:
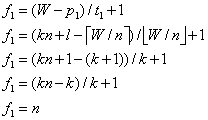
当l=0,特征图的宽可被n整除时:
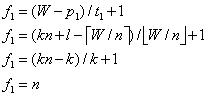
同理可证竖直方向的大小;
所以最终可得一种池化滤波器可得出n*n种特征,则f种特征可以由多个池化滤波后结合得到,即
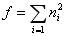
得出结论可是通过设置多个池化层,然后通过n来自动调整池化层的滤波器大小和步长得到相同的特征图,然后将其结合得出最终想要的特征图尺寸。
总结
由论文可知由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变和降低了过拟合,且实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛,SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层);而且其不仅可以用于图像分类还可以用来目标检测。

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









