







目录
1 Hive概述:大数据时代的SQL化解决方案
在大数据生态系统中,Hive扮演着至关重要的角色,它为海量数据的分析处理提供了SQL-like的接口,极大降低了大数据分析的门槛。Hive最初由Facebook开发,后来成为Apache顶级开源项目,现已成为企业大数据平台的核心组件之一。
1.1 Hive的基本概念
Hive是一个建立在Hadoop之上的 数据仓库基础设施,它提供了一系列工具,可以用来进行 数据提取、转换和加载(ETL)。Hive的核心设计理念是将结构化数据文件映射为数据库表,并通过类SQL语言(HiveQL)进行查询分析。
与传统的数据库管理系统不同,Hive并非为 在线事务处理(OLTP)而设计,它更专注于 在线分析处理(OLAP)场景。Hive将SQL查询转换为MapReduce、Tez或Spark作业,在Hadoop集群上执行,这使得它能够处理PB级别的数据。
1.2 Hive的架构组成

Hive架构主要包含以下核心组件:
- 用户接口:包括CLI、JDBC/ODBC接口、Web UI等
- Hive Server:提供Thrift服务,允许远程客户端提交请求
- 元数据存储(Metastore):存储表结构、分区信息等元数据
- 驱动程序(Driver):接收查询请求,创建会话,维护执行生命周期
- 执行引擎(Execution Engine):解析、优化、执行查询计划
- 计算框架:MapReduce、Tez或Spark等分布式计算引擎
- 分布式存储:通常是HDFS,存储实际数据文件
2 Hive的核心特点与优势解析
2.1 Hive的显著特点
Hive之所以能在大数据领域占据重要地位,主要归功于以下几个 核心特点:
- 类SQL接口(HiveQL):为熟悉SQL的数据分析师降低了学习门槛
- 扩展性强:支持自定义函数(UDF)、序列化/反序列化格式(SerDe)
- 灵活的存储格式:支持文本、ORC、Parquet等多种文件格式
- 分区与分桶:提供数据分区和分桶机制,优化查询性能
- 元数据管理:集中的元数据存储,便于数据发现和管理
- 容错性强:基于Hadoop的容错机制,处理失败任务自动重试
2.2 Hive的核心优势
相比直接使用MapReduce编程或其它大数据处理方式,Hive提供了多重优势:开发效率优势:
- 将复杂的MapReduce程序简化为SQL-like查询
- 减少约90%的代码量,提升开发效率
- 便于传统数据分析师快速上手大数据分析
运维管理优势:
- 内置的元数据管理,便于表结构维护
- 支持多种数据格式和压缩方式
- 与Hadoop生态系统无缝集成
性能优化优势:
- 分区剪枝(Partition Pruning)减少I/O
- 谓词下推(Predicate Pushdown)提前过滤数据
- 本地模式执行小数据集查询
- CBO(基于成本的优化器)优化查询计划

Hive查询执行流程图解析:
- 用户提交HiveQL查询语句
- Hive进行语法解析,检查语法正确性
- 语义分析阶段验证表、列是否存在,类型是否匹配
- 生成初始逻辑查询计划
- 应用逻辑优化规则(如谓词下推、列剪裁等)
- 转换为物理执行计划
- 进行物理优化(如分区剪枝、Join优化等)
- 最终生成执行计划
- 转换为MapReduce/Tez/Spark作业执行
- 返回查询结果给用户
3 Hive与传统数据库的深度对比
虽然Hive提供了类似SQL的接口,但其与传统关系型数据库(RDBMS)在架构设计和适用场景上存在本质区别。
3.1 技术架构对比
| 对比维度 | Hive | 传统RDBMS |
| 设计目标 | 批处理分析(OLAP) | 事务处理(OLTP)和简单分析 |
| 数据规模 | PB级以上 | TB级以下 |
| 查询延迟 | 分钟级到小时级 | 毫秒级到秒级 |
| 数据更新 | 有限支持(新版本有所改进) | 完全支持 |
| 索引支持 | 有限 | 丰富 |
| 执行引擎 | MapReduce/Tez/Spark | 专用查询引擎 |
| 存储位置 | HDFS/S3等分布式存储 | 本地磁盘或SAN/NAS |
| 扩展性 | 线性扩展,支持数千节点 | 垂直扩展,通常单机或主从架构 |
| 数据加载 | 读时模式(Schema-on-Read) | 写时模式(Schema-on-Write) |
3.2 适用场景对比
Hive更适合的场景:
- 超大规模数据集(TB/PB级)的批处理分析
- 数据仓库建设和历史数据分析
- 需要与Hadoop生态系统集成的场景
- 对延迟不敏感,但对吞吐量要求高的场景
- 半结构化或非结构化数据的处理
- 需要灵活扩展计算和存储资源的场景
传统数据库更适合的场景:
- 需要低延迟(毫秒级)响应的在线事务处理
- 频繁的数据更新和随机读取操作
- 需要强一致性和复杂事务支持的场景
- 中小规模数据集(GB/TB级)的交互式分析
- 已存在成熟的关系模型和严格的数据约束
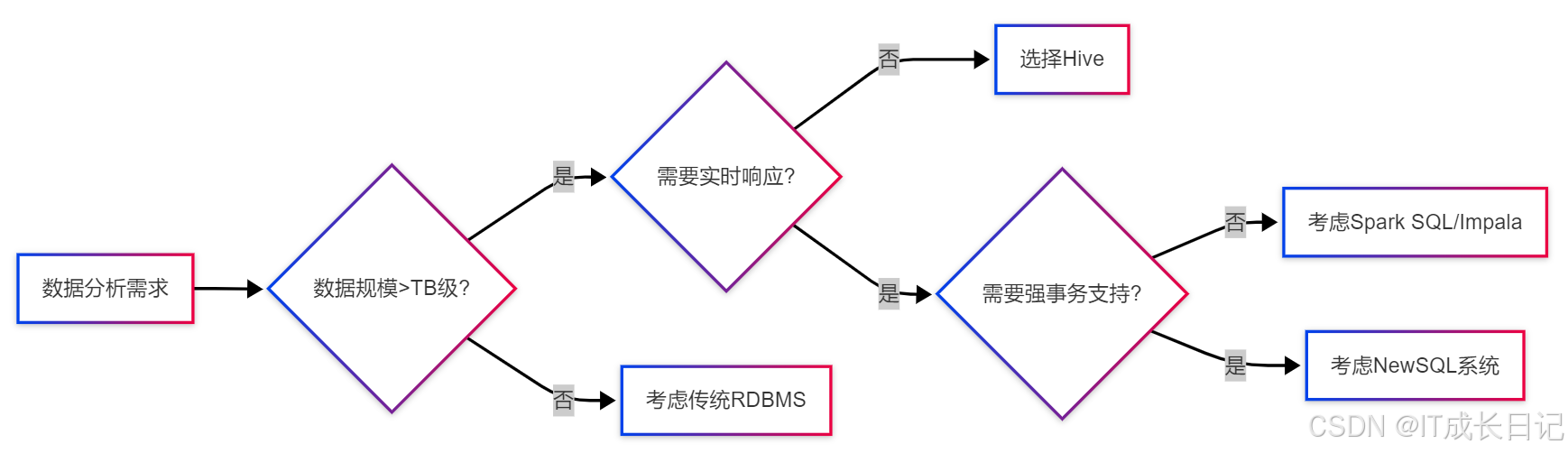
- 首先评估数据规模,小于TB级优先考虑传统数据库
- 大数据场景下,判断是否需要实时响应
- 批处理场景选择Hive,准实时场景考虑Impala等
- 需要强事务支持的大数据场景考虑NewSQL系统
4 总结
Hive作为大数据分析的重要工具,在企业数据仓库建设中发挥着不可替代的作用。
- 适用场景:Hive最适合大规模批处理分析场景,不适合低延迟事务处理
- 性能优化:合理使用分区、分桶和高效存储格式是性能优化的关键
- 技术选型:根据数据规模、延迟要求和事务需求选择合适的技术方案
- 发展趋势:Hive正朝着实时化、云原生化方向发展,保持技术活力
实践建议:
- 对于新项目,建议使用Hive 3.x以上版本
- 生产环境推荐使用ORC/Parquet格式并启用压缩
- 复杂分析场景优先考虑Tez或Spark执行引擎
- 定期维护元数据和统计信息以保证查询性能
- 监控和优化小文件问题,避免性能下降
Hive在大数据生态中的角色仍将长期存在,虽然新兴技术不断涌现,但Hive因其稳定性、成熟度和丰富的功能集,依然是企业大数据平台的核心组件之一。


















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











