







目录
1 Hive UDF基础概念
1.1 什么是UDF
UDF(User Defined Function,用户定义函数)是Hive提供的一种重要扩展机制,允许用户根据特定业务需求自定义数据处理逻辑。UDF的核心价值在于:
- 扩展Hive功能:弥补内置函数的不足
- 封装业务逻辑:将复杂处理流程函数化
- 提升代码复用:避免重复开发相同逻辑
- 优化查询性能:减少数据传输和转换开销

1.2 UDF与内置函数对比
| 特性 | 内置函数 | UDF |
| 来源 | Hive系统自带 | 用户开发 |
| 修改灵活性 | 不可修改 | 可随时修改 |
| 功能范围 | 通用数据处理 | 特定业务逻辑 |
| 性能优化 | 高度优化 | 依赖实现质量 |
| 部署方式 | 开箱即用 | 需要手动注册 |
| 语言支持 | Java实现 | Java/Python等 |
1.3 UDF核心价值体现
- 业务适配:处理行业特定数据格式
- 数据清洗:实现定制化的数据标准化逻辑
- 复杂计算:封装机器学习特征工程等复杂算法
- 性能优化:针对特定场景优化处理效率
2 Hive UDF类型详解
2.1 标准UDF(一进一出)
特点:
- 单行输入,单行输出
- 处理单个数据记录
- 类似数学函数f(x) = y
适用场景:
- 数据格式转换
- 字段值计算
- 简单条件判断

2.2 UDAF(多进一出)
特点:
- 多行输入,单行输出
- 实现聚合计算
- 需要维护中间状态
核心方法:
- iterate():处理输入值
- merge():合并部分聚合结果
- terminate():返回最终结果
适用场景:
- 自定义聚合统计
- 复杂指标计算
- 分组数据处理
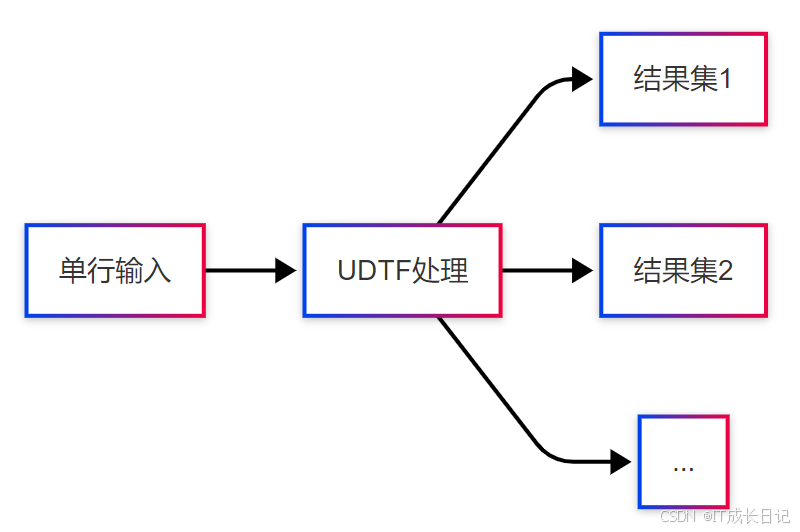
2.3 UDTF(一进多出)
特点:
- 单行输入,多行输出
- 可生成0到多行结果
- 常用于数据展开
适用场景:
- JSON数组展开
- 字符串分割
- 行转列操作
2.4 特殊类型UDF
GenericUDF:
- 更灵活的UDF基类
- 支持复杂类型处理
- 需要实现initialize()和evaluate()方法
动态UDF:
- 运行时参数化
- 通过配置改变行为
- 适合多变业务规则
3 UDF开发全流程指南
3.1 UDF开发示例
- 实现字符串加密函数:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import java.security.MessageDigest;
public class Md5EncryptUDF extends UDF {
private final Text result = new Text();
public Text evaluate(Text input) {
if (input == null) return null;
try {
MessageDigest md = MessageDigest.getInstance("MD5");
md.update(input.getBytes());
byte[] digest = md.digest();
StringBuilder sb = new StringBuilder();
for (byte b : digest) {
sb.append(String.format("%02x", b & 0xff));
}
result.set(sb.toString());
return result;
} catch (Exception e) {
throw new RuntimeException("MD5加密失败", e);
}
}
}- 实现平均值UDAF:
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class AvgUDAF extends UDAF {
public static class AvgEvaluator implements UDAFEvaluator {
private double sum = 0;
private long count = 0;
public void init() {
sum = 0;
count = 0;
}
public boolean iterate(Double value) {
if (value != null) {
sum += value;
count++;
}
return true;
}
public Double terminatePartial() {
return count == 0 ? null : sum / count;
}
public boolean merge(Double other) {
if (other != null) {
sum += other * count;
count++;
}
return true;
}
public Double terminate() {
return count == 0 ? null : sum / count;
}
}
}3.3 UDTF开发示例
- 实现字符串分割UDTF:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class SplitUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
// 参数校验
if (args.length != 2) {
throw new UDFArgumentLengthException("SplitUDTF需要2个参数");
}
// 输出结构定义
ArrayList<String> fieldNames = new ArrayList<>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<>();
fieldNames.add("item");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
String delimiter = args[1].toString();
String[] items = input.split(delimiter);
for (String item : items) {
forward(new Object[]{item});
}
}
@Override
public void close() throws HiveException {
// 清理资源
}
}4 UDF部署与使用
4.1 部署流程

- 打包UDF:
mvn clean package- 上传HDFS:
hdfs dfs -put hive-udf-1.0.jar /user/hive/udfs/- Hive会话注册:
ADD JAR hdfs:///user/hive/udfs/hive-udf-1.0.jar;- 创建临时函数(会话级):
CREATE TEMPORARY FUNCTION md5_encrypt AS 'com.example.Md5EncryptUDF';- 创建永久函数(元存储):
CREATE FUNCTION db_name.md5_encrypt AS 'com.example.Md5EncryptUDF'
USING JAR 'hdfs:///user/hive/udfs/hive-udf-1.0.jar';4.2 使用示例
- 标准UDF调用:
SELECT username, md5_encrypt(password) AS encrypted_pwd FROM users;- UDAF调用:
SELECT department, avg_salary(value) AS avg_salary FROM employee GROUP BY department;- UDTF调用:
SELECT
user_id,
split_item
FROM user_tags
LATERAL VIEW split(tags, ',') t AS split_item;5 UDF性能优化策略
5.1 设计优化原则
减少对象创建:
- 重用输出对象
- 避免频繁内存分配
优化数据类型:
- 使用Writable类型
- 避免不必要类型转换
惰性计算:
- 延迟复杂计算
- 短路逻辑判断
5.2 配置参数调优
| 参数名 | 默认值 | 优化建议 |
| hive.exec.parallel | false | UDF密集型设为true |
| hive.exec.parallel.thread.num | 8 | 根据集群资源调整 |
| hive.vectorized.execution.enabled | false | 向量化执行设为true |
| hive.vectorized.execution.reduce.enabled | false | 向量化reduce设为true |
5.3 监控与诊断
UDF性能指标:
- 执行时间:Counter: UDF_TIME
- 处理记录数:Counter: RECORDS_PROCESSED
- 内存使用:Counter: MEMORY_USAGE
- GC时间:Counter: GC_TIME
6 总结
Hive UDF作为大数据处理的重要扩展手段,为复杂业务场景提供了灵活高效的解决方案。在实际应用中,建议:
- 优先考虑使用标准UDF满足简单需求
- 合理设计UDAF处理聚合场景
- 善用UDTF实现行列转换
- 持续监控和优化UDF性能
随着大数据技术的演进,UDF将继续发挥关键作用,同时也将迎来更多创新和发展。掌握UDF开发技能,将使大数据工程师能够更灵活地应对各种数据处理挑战。


















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











