






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
VMD-TCN-BiGRU-Attention多变量时序预测模型
一、变分模态分解VMD
变分模态分解(Variational Mode Decomposition,简称VMD)是一种用于信号处理和分解的数据驱动方法。它是一种基于数据自适应的分解技术,能够有效地将复杂的信号分解成多个模态成分,并且具有良好的时频局部性质。
VMD 的基本思想是将信号分解为多个振动模态,每个模态都对应于信号中的一个频率成分。与传统的信号分解方法相比,VMD 不需要预先知道信号的频率信息或者采用固定的基函数,而是通过优化问题来自适应地确定模态数和频率。
VMD 的算法过程是通过最小化一个代价函数来实现的,其中包括数据拟合项和约束项。数据拟合项用于确保每个模态与原始信号的拟合程度,而约束项则用于控制模态之间的平滑性和稀疏性,以便更好地反映信号的局部特征。
VMD 的优点之一是能够处理非线性和非平稳信号,并且对于包含噪声的信号也具有较强的稳健性。此外,VMD 还可以适用于多种信号分析任务,如时频分析、信号去噪、特征提取等。
总的来说,VMD 是一种灵活、高效且适用于多种信号处理任务的分解方法,它在处理复杂信号和噪声干扰方面具有优势,并且在许多领域,如通信、医学、地球科学等都有广泛的应用前景。
- 示例数据
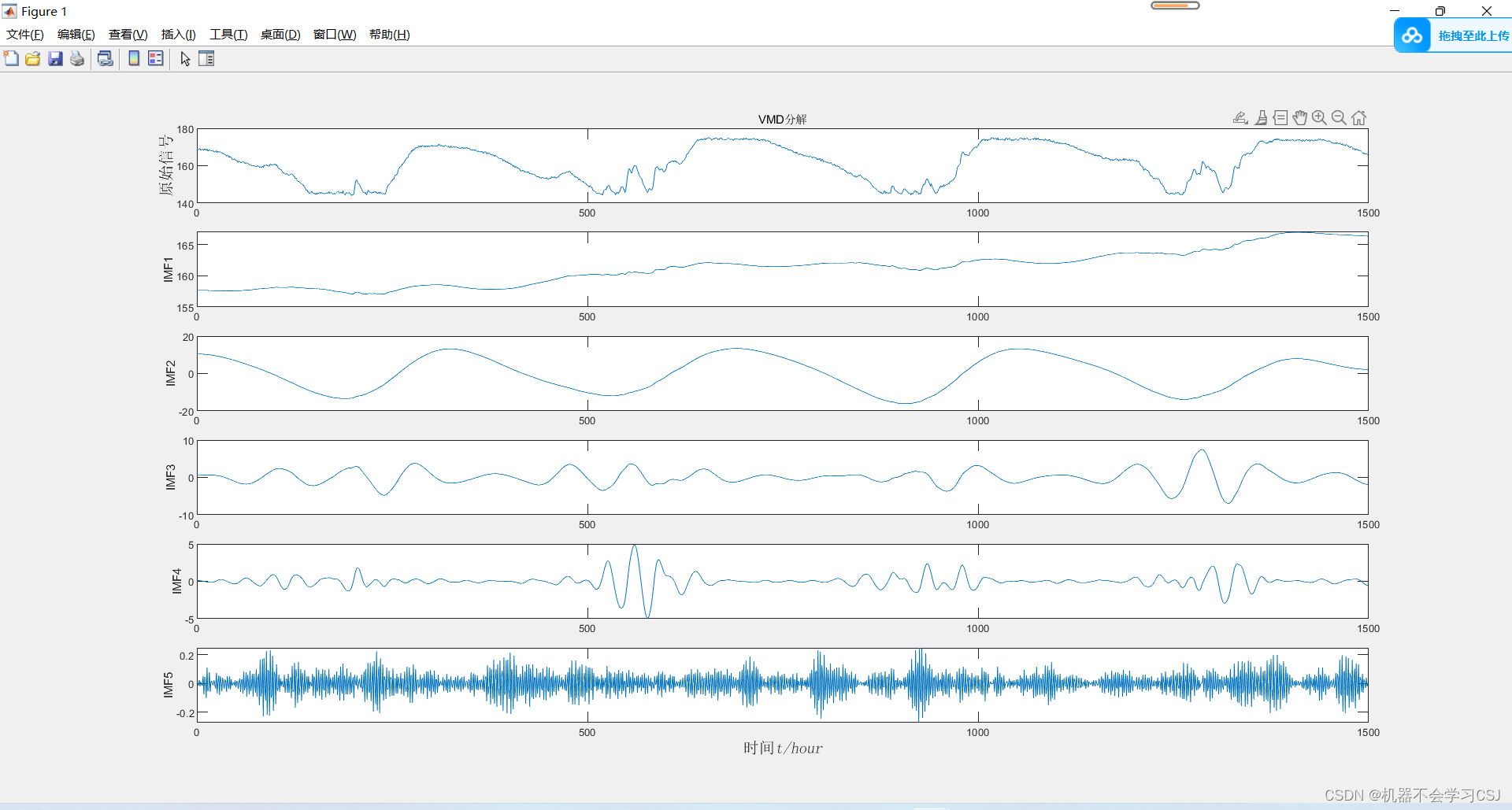
对输出列数据进行VMD分解
- 分解结果:
二、时域卷积网络TCN
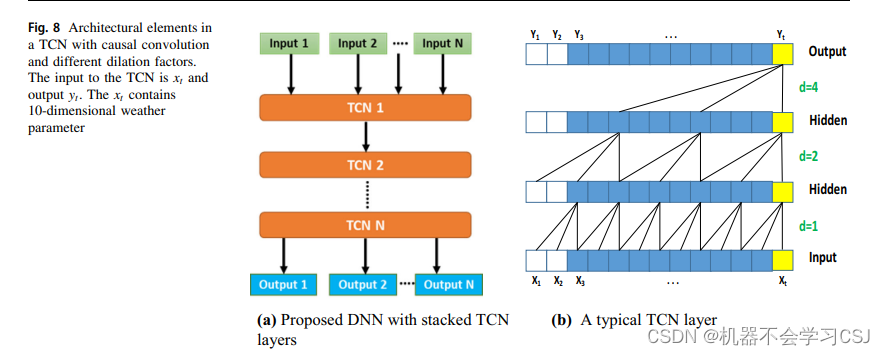
时域卷积网络(Temporal Convolutional Network,TCN)是一种用于处理时间序列数据的深度学习模型,它由Shaojie Bai et al.在2018年提出。TCN结合了卷积神经网络(CNN)的强大特征提取能力和循环神经网络(RNN)对时间序列数据的处理能力,特别适合于需要捕捉长期依赖关系的任务。
TCN的核心原理包括以下几个关键概念:
因果卷积(Causal Convolution):TCN使用因果卷积来确保网络的输出只依赖于当前和之前的输入,而不依赖于未来的输入。这是通过在输入序列的末尾添加零填充,并使用卷积操作时的步长和填充策略来实现的。
扩张卷积(Dilated Convolution):TCN使用扩张卷积来增大感受野,而不需要增加网络的深度。扩张卷积通过在卷积核中插入间隔来实现,这样可以使网络在较浅的层次捕捉到更长时间的依赖关系。
残差连接(Residual Connections):TCN在每个卷积层后引入残差连接,这有助于解决深度网络中的梯度消失问题,并允许训练更深层次的网络。
权重归一化(Weight Normalization):TCN使用权重归一化来稳定训练过程,提高模型的收敛速度。
三、双向门控单元循环神经网络BiGRU
双向门控单元循环神经网络(Bidirectional Gated Recurrent Unit, BiGRU)是一种用于处理序列数据的深度学习模型,它结合了前向和后向时间信息来提高模型对数据的理解和预测能力。BiGRU是门控循环单元(GRU)的扩展。
- BiGRU的结构和原理
BiGRU的核心思想是使用两个GRU层,一个处理正向序列(从过去到未来),另一个处理反向序列(从未来到过去)。这样,每个时间点的输出都包含了该点之前和之后的信息,为模型提供了一个更全面的序列表示。
这是一个VMD-TCN-BiGRU的结构图
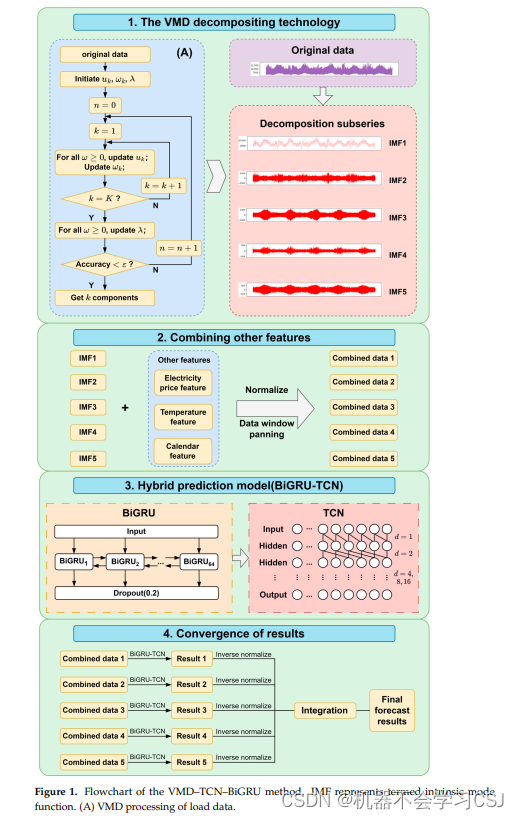
Zou, Z.; Wang, J.; E, N.; Zhang, C.; Wang, Z.; Jiang, E. Short-Term Power Load Forecasting: An Integrated Approach Utilizing Variational Mode Decomposition and TCN–BiGRU. Energies 2023, 16, 6625. https://doi.org/10.3390/en16186625
四、注意力机制
注意力机制(Attention Mechanism)是一种在深度学习模型中模拟人类注意力的机制,它允许模型在处理信息时能够聚焦于当前最为重要的部分。注意力机制最初在计算机视觉领域提出,并在自然语言处理(NLP)领域得到了广泛的应用,尤其是在序列到序列(Seq2Seq)的任务中,如机器翻译、文本摘要和问答系统等。
注意力机制的基本原理
人类的注意力是有选择性的,我们通常只关注环境中的一小部分信息,而忽略其他不相关的信息。在序列处理任务中,注意力机制使模型能够动态地选择输入序列中与当前处理状态最相关的部分。
注意力机制的核心计算过程涉及以下几个步骤:
计算权重:模型首先计算输入序列中每个元素的权重,这些权重反映了各个元素对当前处理状态的重要性。
权重归一化:通过softmax函数对权重进行归一化处理,确保了所有权重的和为1,这样模型就可以将概率分布作为权重使用。
加权求和:将每个输入元素乘以对应的权重,然后对所有加权后的元素求和,得到一个聚合的表示,这个表示能够捕捉输入序列中的关键信息。
五、实验结果
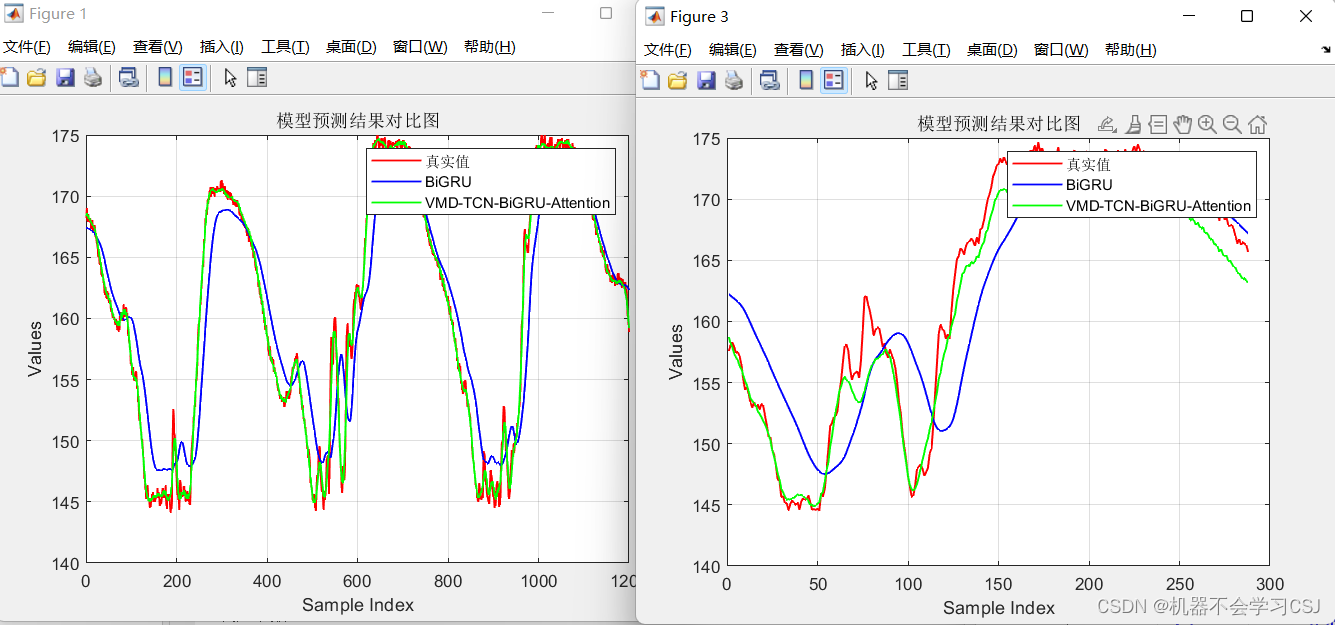
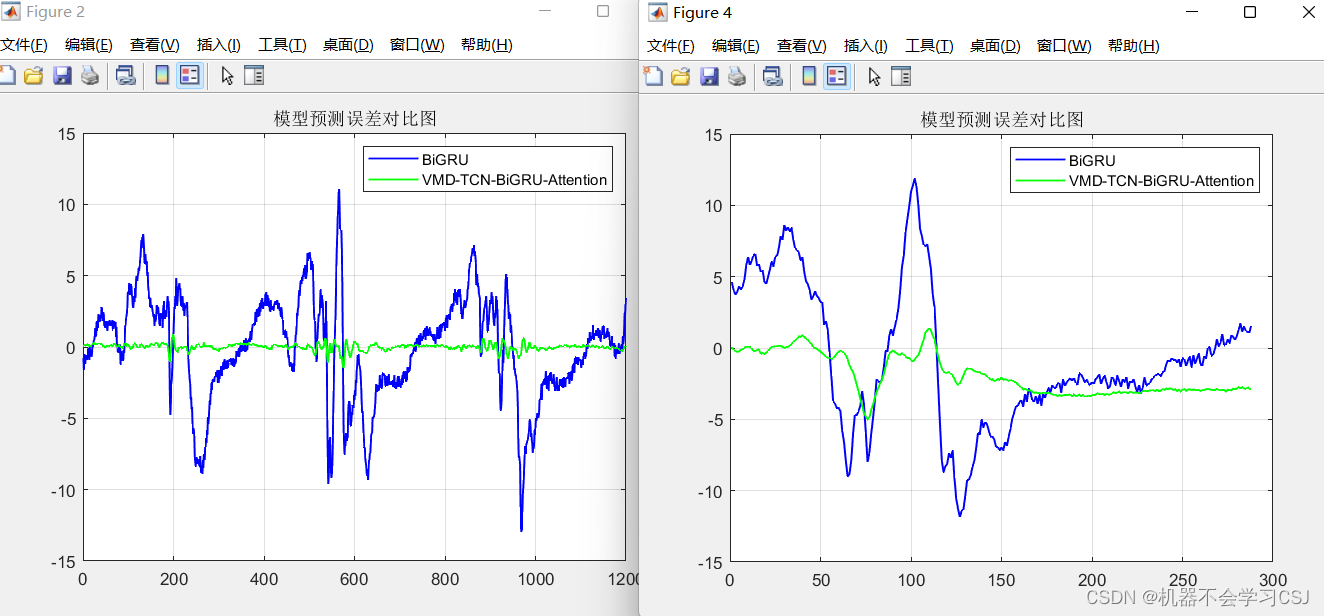
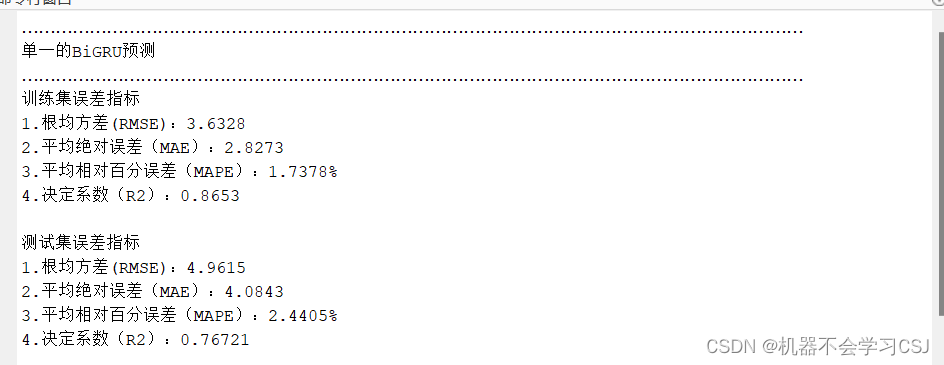
BiGRU实验结果:
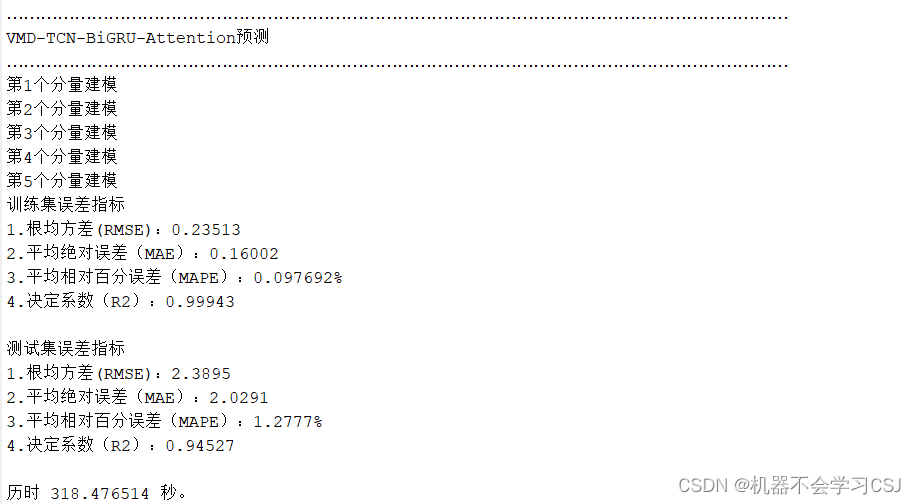
VMD-BiTCN-BiGRU-Attention实验结果:
六、参考文献
Humphrey W, Dalke A, Schulten K. VMD: visual molecular dynamics[J]. Journal of molecular graphics, 1996, 14(1): 33-38.
Hewage P, Behera A, Trovati M, et al. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station[J]. Soft Computing, 2020, 24: 16453-16482.
She D, Jia M. A BiGRU method for remaining useful life prediction of machinery[J]. Measurement, 2021, 167: 108277.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
变分模态分解VMD论文链接:http://wwws.ks.uiuc.edu/Publications/Papers/PDF/HUMP96/HUMP96.pdf
时域卷积TCN论文连接:https://link.springer.com/article/10.1007/s00500-020-04954-0
双向卷积BiGRU论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0263224120308162
注意力机制论文链接:https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
七、获取方式
| 代码名称 | 链接 |
|---|---|
| VMD-TCN-BiGRU-Attention时序预测 | https://mbd.pub/o/bread/mbd-ZpWVkpZq |
| VMD-TCN-GRU-Attention时序预测 | https://mbd.pub/o/bread/mbd-ZpWUm55w |
| VMD-TCN-BiLSTM-Attention时序预测 | https://mbd.pub/o/bread/mbd-ZZ6ZlZhu |
| BiTCN-BiGRU时序预测 | https://mbd.pub/o/bread/ZZ6UmZ5v |
| QRLSTM分位数回归区间预测 | https://mbd.pub/o/bread/ZpWTlZ9q |
| 深度可分离卷积时序预测SeparableConv | https://mbd.pub/o/bread/mbd-ZZ2clppt |
| FTTA-BiTCN-BiGRU时序预测 | https://mbd.pub/o/bread/ZZ6Vk5tu |














 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









