






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、美洲狮优化算法
美洲狮是一种原产于美洲大陆的大型猫科动物,在南美洲的安第斯山脉到加拿大的育空地区都有它们的栖息地。作为美洲第二大的猫科动物,美洲狮适应性强,生活在不同的环境中,以其他动物为食。它们主要在夜间活动,但白天也可以看到它们。
美洲狮非常聪明,具有优秀的记忆力。为了更有效地狩猎,它们经常去之前成功猎物的地方,这是基于它们的经验和记忆。这种有针对性的行为可能是返回之前狩猎过的地点,也可能是探索新的狩猎地点。本文中考虑了美洲狮在回头开发潜在狩猎地点和前往新地区探索的两个阶段。通过借鉴美洲狮的智慧和记忆,以及引入一种新的智能机制,我们提出了一种先进的元启发式算法,可以更好地模拟美洲狮的狩猎策略。

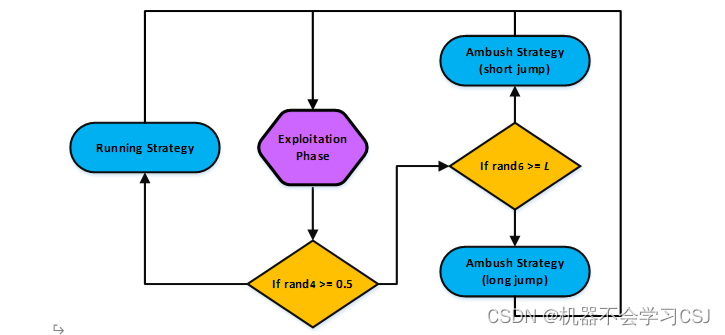

算法具体过程可以查看以下链接
二、CNN卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,广泛用于计算机视觉领域。CNN 的核心思想是通过卷积层和池化层来自动提取图像中的特征,从而实现对图像的高效处理和识别。
在传统的机器学习方法中,图像特征的提取通常需要手工设计的特征提取器,如SIFT、HOG等。而 CNN 则可以自动从数据中学习到特征表示。这是因为 CNN 模型的卷积层使用了一系列的卷积核(filters),通过在输入图像上滑动并进行卷积运算,可以有效地捕捉到图像中的局部特征。
CNN 模型的卷积层可以同时学习多个不同的卷积核,每个卷积核都可以提取出不同的特征。通过堆叠多个卷积层,CNN 可以在不同的层次上提取出越来越抽象的特征。例如,低层次的卷积层可以捕捉到边缘和纹理等基本特征,而高层次的卷积层可以捕捉到更加复杂的语义特征,比如目标的形状和结构。
在卷积层之后,CNN 还会使用池化层来进一步压缩特征图的维度,减少计算量并增强模型的平移不变性。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling),它们可以对特征图进行降采样,并保留最显著的特征。
通过多次堆叠卷积层和池化层,CNN 可以将输入图像逐渐转换为一系列高级特征表示。这些特征表示可以用于各种计算机视觉任务,如图像分类、目标检测、语义分割等。此外,CNN 还可以通过在最后添加全连接层和激活函数来进行预测和分类。
CNN 特征提取的主要优势在于其自动学习特征表示的能力和对图像局部结构的敏感性。相较于传统的手工设计特征提取器,CNN 可以更好地适应不同的数据集和任务,并且能够从大规模的数据集中学习到具有判别性的特征表示。这使得 CNN 成为计算机视觉领域的重要工具,并在许多实际应用中取得了令人瞩目的成果。
CNN详细解释可以参考以下链接
三、BiLSTM双向长短期记忆网络
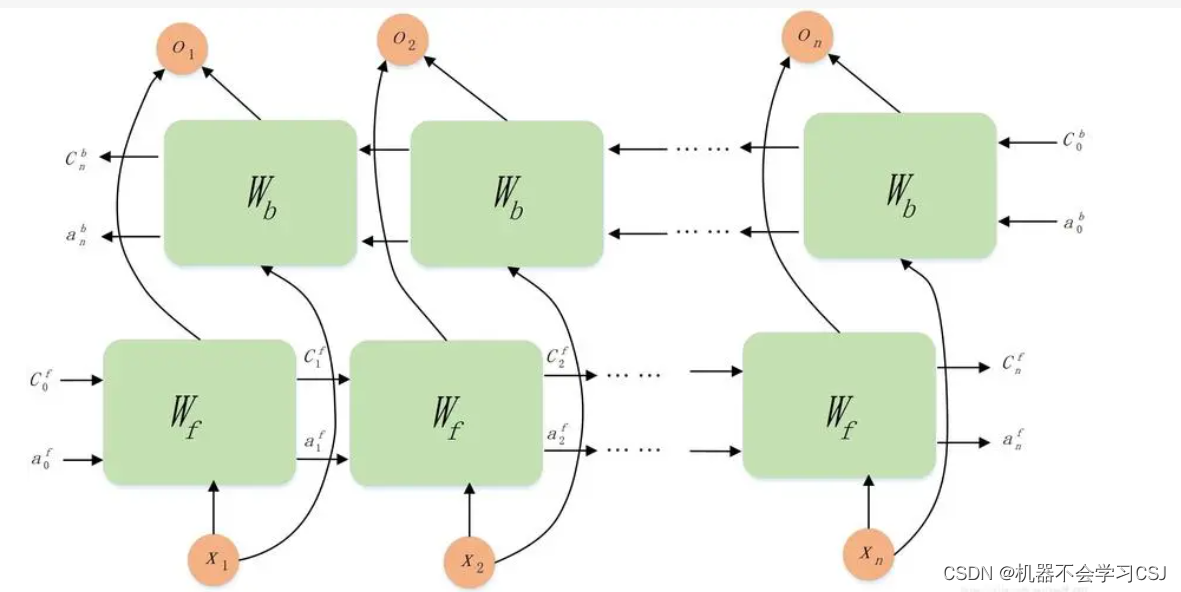
双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)是一种常用于序列数据建模的深度学习模型,特别适用于自然语言处理和时间序列分析等任务。BiLSTM结合了长短期记忆网络(LSTM)和双向循环神经网络(BiRNN)的特性,能够有效地捕捉序列数据中的长期依赖关系。
LSTM网络
首先,让我们来介绍一下LSTM网络。LSTM是一种特殊的循环神经网络(RNN),它通过门控机制来有效地捕捉和存储长期依赖关系。LSTM单元包括一个输入门、遗忘门、输出门和细胞状态,通过这些门控单元可以选择性地传递信息和控制信息流动,从而有效地解决了传统RNN中梯度消失和梯度爆炸等问题。
双向循环神经网络
双向循环神经网络是一种具有两个方向的循环连接的神经网络结构,分别从前向和后向对输入序列进行建模。这允许网络在每个时间步同时考虑过去和未来的信息,有助于更全面地理解序列数据中的上下文关系。
BiLSTM结构
BiLSTM将LSTM和双向循环神经网络结合起来,以便同时利用过去和未来的信息。在BiLSTM中,输入序列首先通过一个前向LSTM网络进行处理,然后再通过一个反向LSTM网络进行处理。最后,将前向和反向LSTM的输出进行连接或者合并,以获得对整个序列上下文信息的双向建模。
BiLSTM网络具有以下优点:
- 能够有效地捕捉序列数据中的长期依赖关系,适用于各种自然语言处理和时序数据建模任务。
- 结合了前向和后向信息,可以更全面地理解序列数据中的上下文关系。适用于诸如序列标注、情感分析、命名实体识别、机器翻译等需要全局序列信息的任务。应用领域。
详细介绍可以参考以下链接
四、注意力机制
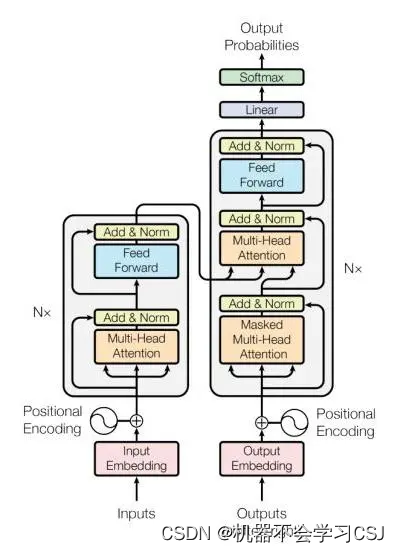
自注意力机制(Self-Attention)是一种用于序列数据处理的机制,最早由Vaswani等人在Transformer模型中引入。它能够捕捉序列中不同位置之间的依赖关系,实现对每个位置的信息加权聚合,从而更好地理解和表示序列中的重要特征。
自注意力机制的核心思想是通过计算每个位置与其它位置之间的关联度来确定每个位置的权重。这种关联度是通过将当前位置的特征与其他位置的特征进行相似性计算得到的。相似性计算通常采用点积(Dot Product)或者加性方式(Additive)。
具体来说,自注意力机制包括以下几个步骤:
- 查询(Query)、键(Key)和值(Value)的计算:通过线性变换将输入序列映射为查询、键和值的表示。
- 相似性计算:对于每个查询,计算其与所有键之间的相似性得分。相似性计算可以使用点积或加性方式完成。
- 注意力权重计算:将相似性得分进行归一化处理,得到注意力权重,表示每个位置在当前位置的重要程度。
- 加权求和:将值乘以注意力权重,并对所有位置进行加权求和,得到自注意力聚合后的表示。
五、PO-CNN-BiLSTM-Attention时间序列数据预测模型
- PO-CNN-BiLSTM-Attention时间序列数据预测模型是一种基于元启发式算法的先进模型,用于处理时间序列数据预测问题。
- 该模型采用了卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)和注意力机制(Attention)三种不同的结构,并引入了美洲狮优化器(PO)进行优化。
- 通过PO算法的智能搜索和优化,该模型可以更好地捕捉时间序列数据的非线性关系,并提高预测精度。
- 同时,CNN结构可有效提取数据特征,BiLSTM结构可处理长序列数据,而Attention机制则可以加强关键信息的学习和表达。
- 这些结构的结合使PO-CNN-BiLSTM-Attention时间序列数据预测模型在时间序列预测任务中表现出较高的准确性和实用性。
六、核心代码
读取数据
%% 导入数据
result = xlsread('数据集.xlsx');
%% 时序数据转换
num_samples = length(result); % 样本个数
kim = 15; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
%% 划分数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)];
end
%% 数据分析
num_size = 0.8; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
模型构建
%% 建立模型
lgraph = layerGraph(); % 建立空白网络结构
tempLayers = [
sequenceInputLayer([f_, 1, 1], "Name", "sequence") % 建立输入层,输入数据结构为[num_dim, 1, 1]
sequenceFoldingLayer("Name", "seqfold")]; % 建立序列折叠层
lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中
tempLayers = [
convolution2dLayer([3, 1], 16, "Name", "conv_1", "Padding", "same") % 建立卷积层,卷积核大小[3, 1],16个特征图
reluLayer("Name", "relu_1") % Relu 激活层
% Relu 激活层
lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中
tempLayers = [
sequenceUnfoldingLayer("Name", "sequnfold") % 建立序列反折叠层
flattenLayer("Name", "flatten") % 网络铺平层
bilstmLayer(best_hd, "Name", "bilstm_1",'Outputmode','sequence') % LSTM层
dropoutLayer(0.3,"Name","drop_1")
% LSTM层
dropoutLayer(0.3,"Name","drop_2")
%注意力层
fullyConnectedLayer(outdim, "Name", "fc") % 全连接层
regressionLayer("Name","regression") ]; % 回归层
lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中
lgraph = connectLayers(lgraph, "seqfold/out", "conv_1"); % 折叠层输出 连接 卷积层输入
lgraph = connectLayers(lgraph, "seqfold/miniBatchSize", "sequnfold/miniBatchSize"); % 折叠层输出连接反折叠层输入
lgraph = connectLayers(lgraph, "relu_2", "sequnfold/in"); % 激活层输出 连接 反折叠层输入
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 500,... % 最大训练次数
'MiniBatchSize', 500, ... % 批大小
'InitialLearnRate', best_lr,... % 初始学习率为0.001
'L2Regularization', best_l2,... % L2正则化参数
'LearnRateDropFactor', 0.1,... % 学习率下降因子 0.1
'LearnRateDropPeriod', 400,... % 经过训练后 学习率为 0.001*0.1
'Shuffle', 'every-epoch',... % 每次训练打乱数据集
'ValidationPatience', Inf,... % 关闭验证
'Plots', 'training-progress',... % 画出曲线 可关闭
'Verbose', false);
七、结果展示
BilSTM预测结果
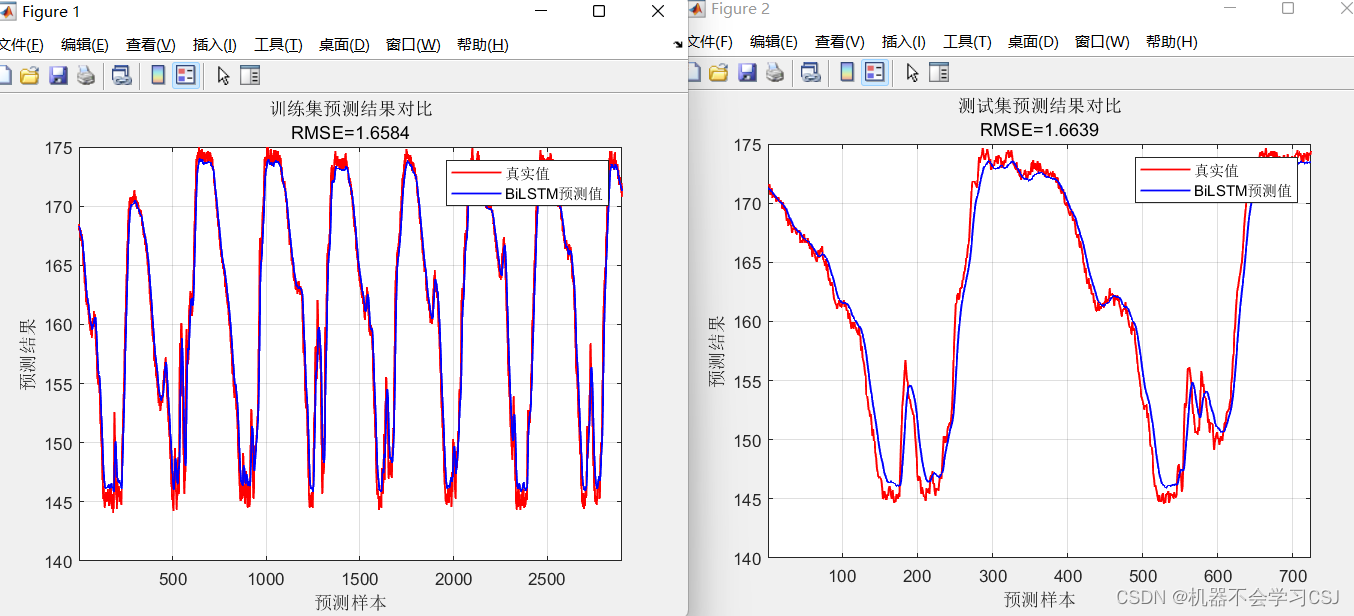
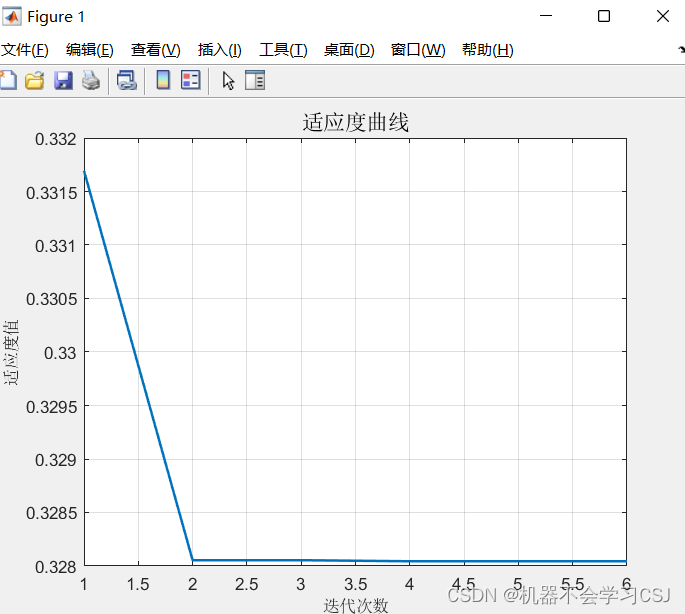
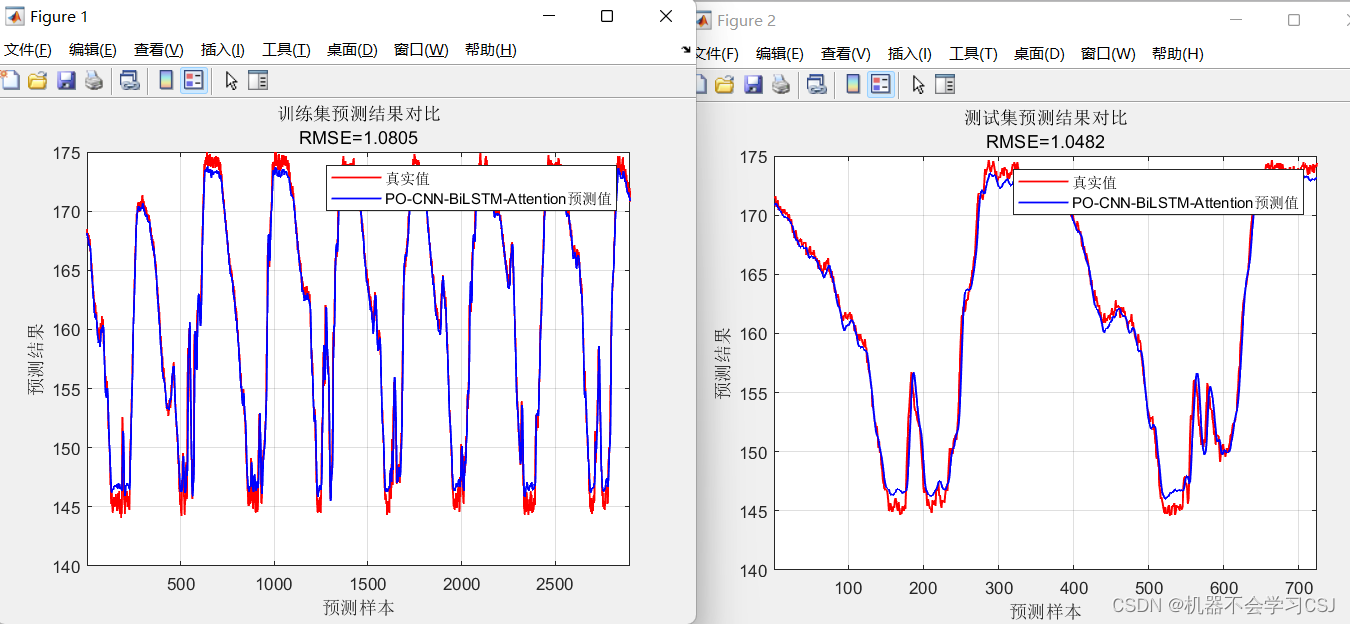
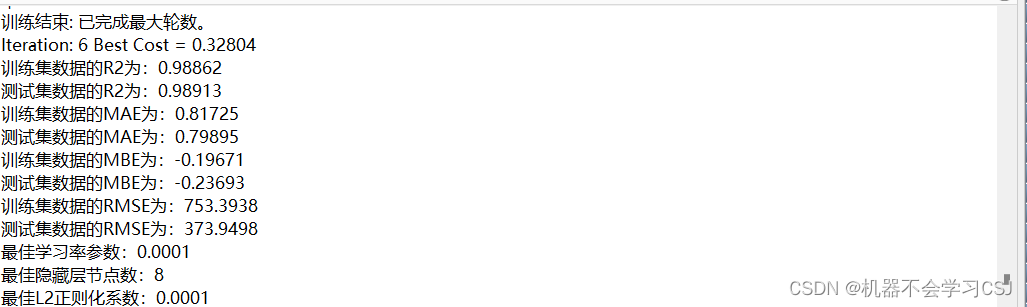
PO-CNN-BiLSTM-Attention预测结果(迭代6次之后的结果)
八、获取方式
| 名称 | 链接 |
|---|---|
| PO-CNN-BiLSTM-Attention网络时间序列预测(有BiLSTM对比) | https://mbd.pub/o/bread/ZZuVm59q |
| PO-BP神经网络数据回归预测 | https://mbd.pub/o/bread/mbd-ZZuVm5xq |
| PO-SVM支持向量机回归预测 | https://mbd.pub/o/bread/mbd-ZZuVm5xx |
| 蝴蝶BOA优化BP神经网络的数据回归预测 | https://mbd.pub/o/bread/mbd-ZZuVmZ5x |
点击跳转
机器不会学习主页
关注账号会不断更新!!!!!
关注后私信会免费赠送基础回归或时序算法全家桶!!!!!














 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









