







文章添加链接描述
1:
作者将卷积引入到VIT中,产生了相比于VIT更好的结果,通过一个包含卷积token编码的分层transformer,和一个使用卷积投射的transformer块。作者通过上述的操作是为了在transformer中引入卷积的一些内在特性,比如平移旋转不变形等来和transformer的动态注意力,全局上下文和更好的归一化强强联手。最后作者还得出一个结论:在他们的模型中,位置编码可以移除来简化设计。
作者发现在小数据集上,transformer的效果是不如CNN的,我也发现了,训练时候结果差0.05左右,验证时没啥差别。原因就是VIT缺少卷积缺少的内在特性,因此使得CNN更加适合这类任务。例如:图像作为一个2D结构,因此空间的邻域像素就有很强的相关性。而CNN捕捉这些局部特征就很好,通过局部感受野,共享权重,空间下采样。
在CVT中,作者首先将transformer划分为多个stage,形成分层transformer。在每个stage开头包含一个卷积token编码,通过重叠的卷积操作在图片上进行卷积,即将token序列变回原来的图片。这样可以捕捉局部信息,且减少序列的长度,同时增加token的维度。
(想一下:在原始的VIT中,通过卷积将token转换为序列,步长就等于patch的大小,那样卷积就是不重叠的了。即减少序列的长度,增加token的维度。)
将卷积投射替换掉之间的线性投射层,通过使用一个sxs大小的深度可分离卷积。这样可以减少注意力机制中的语义模糊。同样可以减少计算复杂度。
(想一下:深度可分离卷积的优势就是可以减少计算复杂度相比于普通的卷积,但是效果好不好就不一定了。)
2:
介绍在CNN中引入注意力,在transformer中引入卷积,相互借鉴,共同进步。
3:
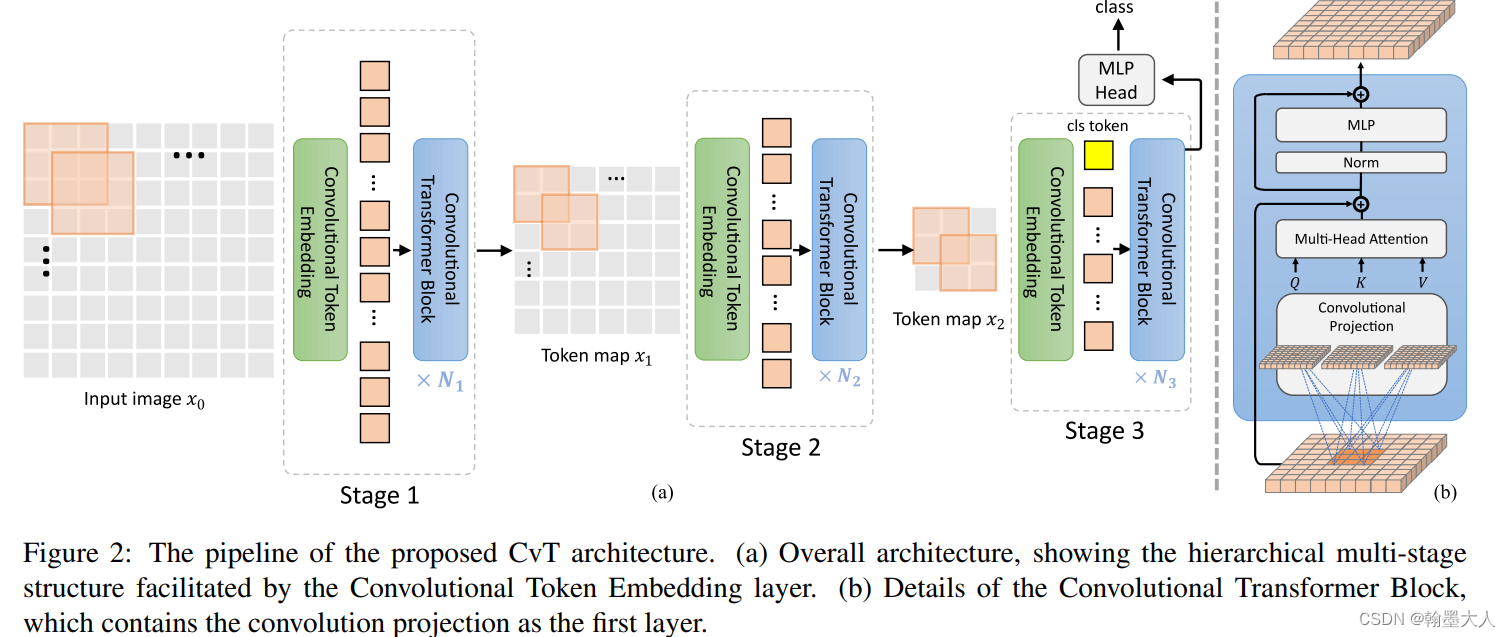
在(b)中,通过深度可分离卷积产生Q,K,V。在最后一个阶段加入classtoken预测最后的类别。
卷积token编码:

生成新的长宽:
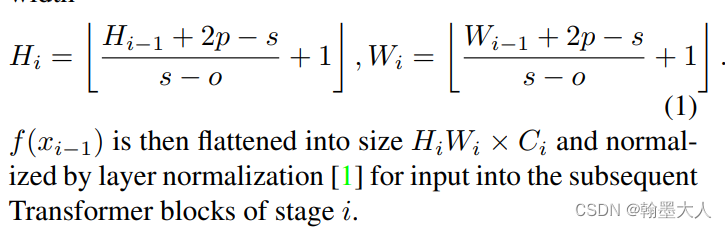
卷积transformer中的卷积投射:
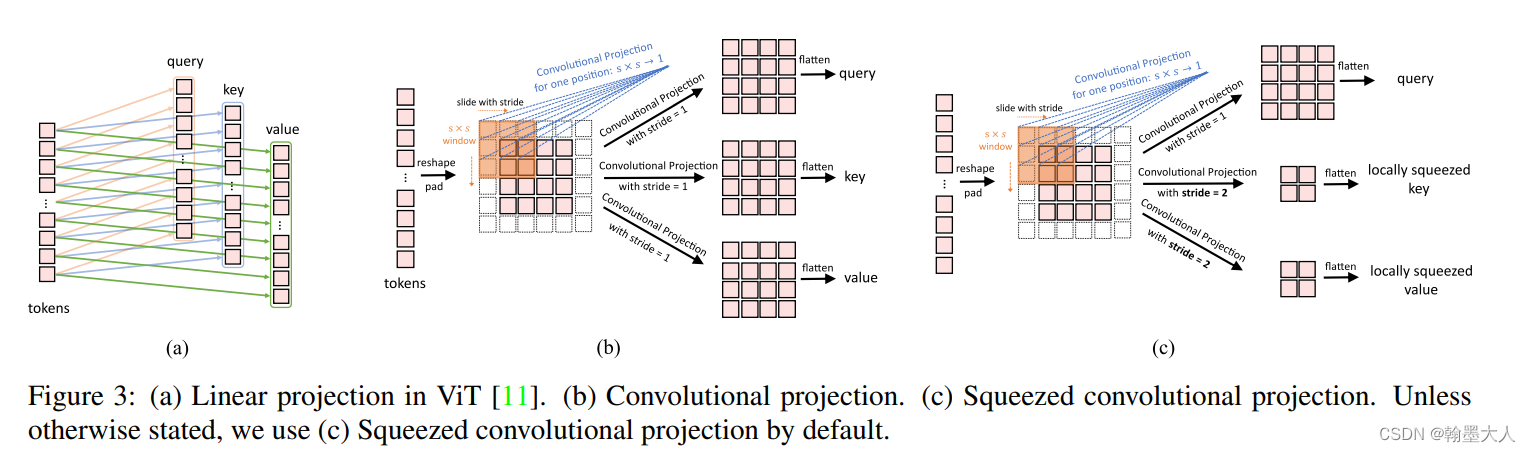
用公式表示:

有效性的考量:总结就是较少计算量,在©中,可以将k和v下采样到很小的尺寸来减少模型复杂度。
关于移除位置编码:在model中可以建模局部空间的关系,可以移除掉,看实验部分的证明。
4:
实验:4.1具体的配置:

训练:batchsize=2048,300个epoch。图像大小224x224。
和一些sota的方法对比,包含卷积和transformer:
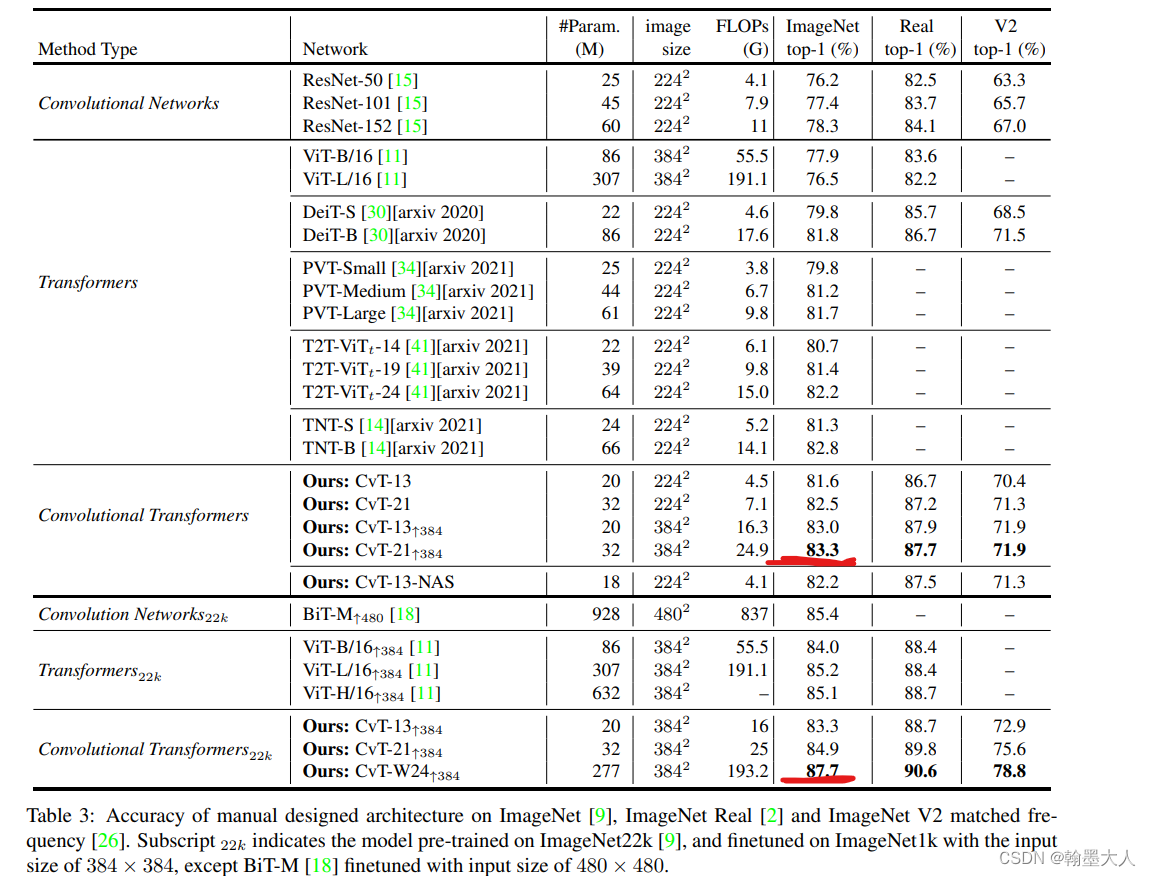
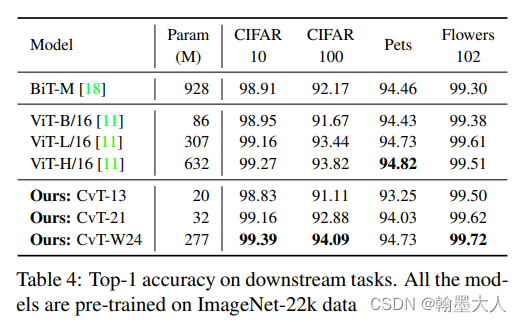
在下游任务表现得也很好:
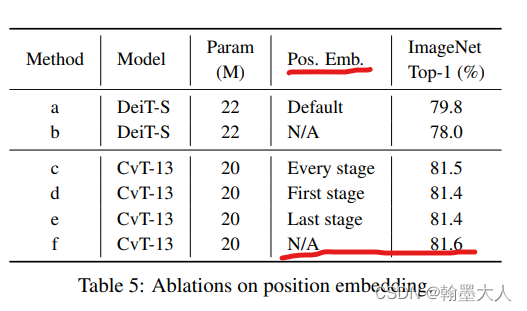
消融实验:
1:验证在CVT中可以移除掉位置编码:不需要位置编码效果也很好,原因是引入了重叠的卷积计算。
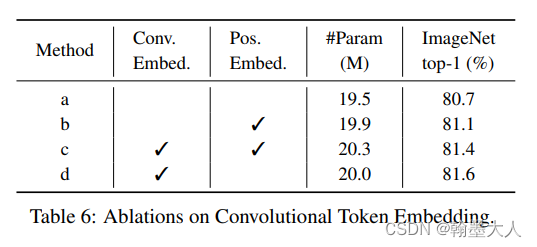
2:验证卷积位置编码和普通的位置编码:
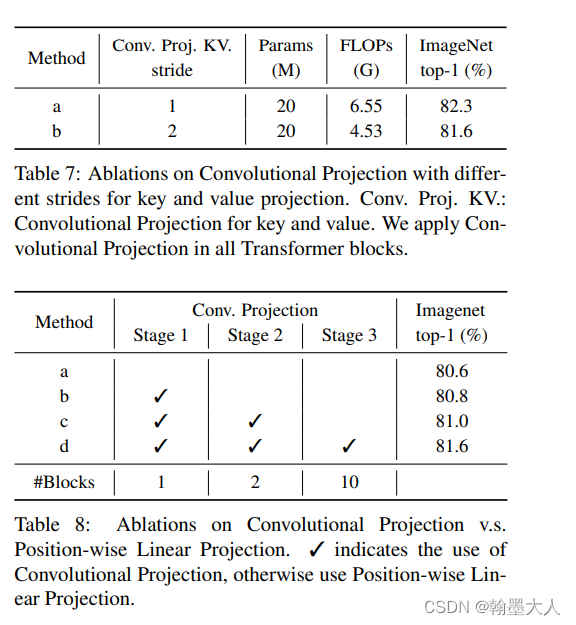
3:验证卷积投射以及在不同位置进行卷积投射:

















06-04
 7701
7701
7701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









