







1、Yolov5的网络结构
- Yolov5中使用的Coco数据集输入图片的尺寸为640*640,但是训练过程的输入尺寸并不唯一,Yolov5可以采用Mosaic增强技术把4张图片的部分组成了一张尺寸一定的输入图片。如果需要使用预训练权重,最好将输入图片尺寸调整到与作者相同的尺寸,输入图片尺寸必须是32的倍数,这与anchor检测的阶段有关。
Yolov5s网络结构示意图: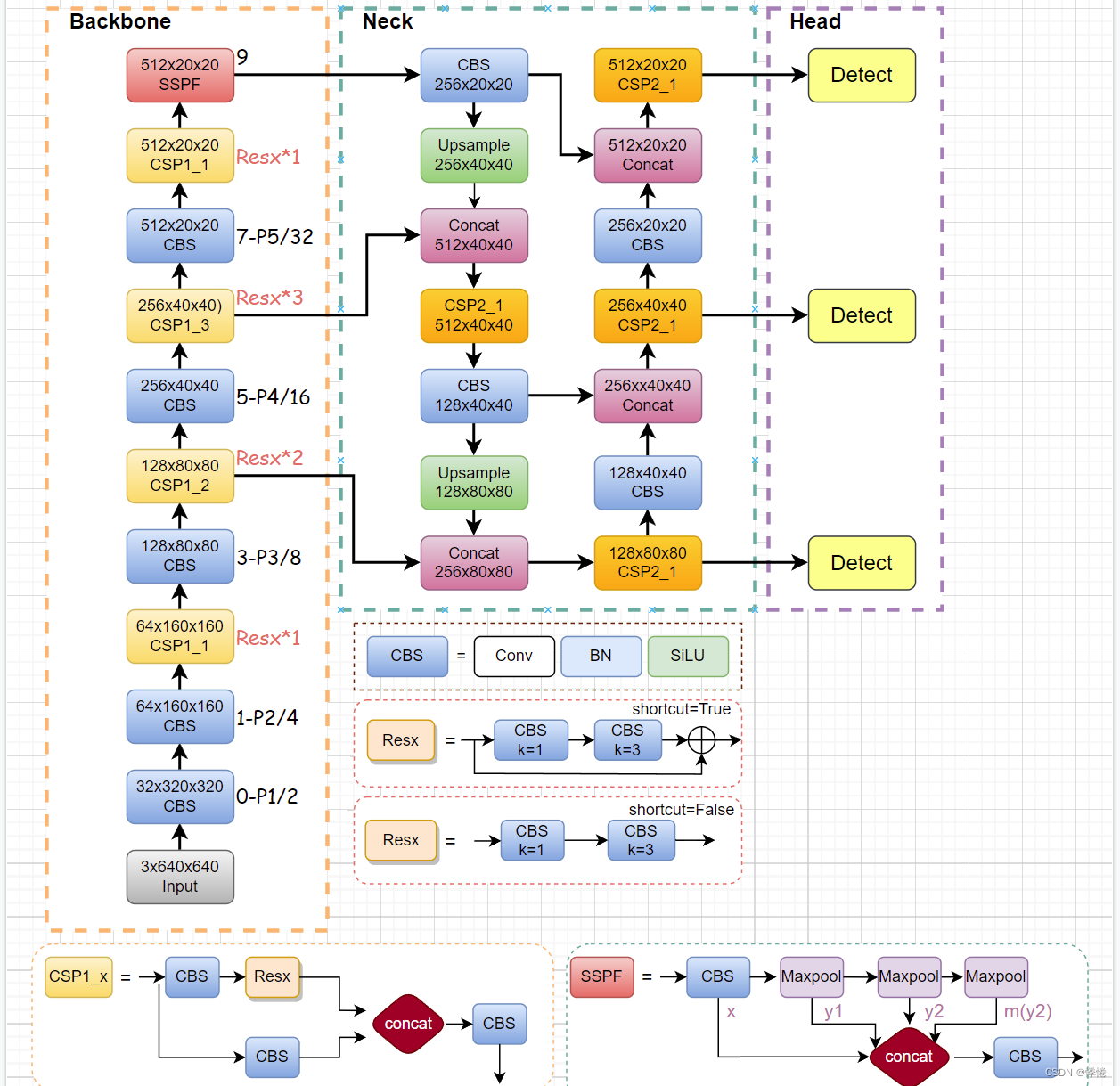
- 当输入尺寸为640*640时,会得到3个不同尺度的输出:80x80(640/8)、40x40(640/16)、20x20(640/32)。
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32- anchors参数共有三行,每行6个数值,代表应用不同的特征图:
- 第一行是在最大的特征图上的锚框,80x80代表浅层的特征图(P3),包含较多的低层级信息,适合用于检测小目标,所以这一特征图所用的anchor尺度较小;
- 第二行是在中间的特征图上的锚框,40x40代表中间的特征图(P4),介于浅层和深层这两个尺度之间的anchor用来检测中等大小的目标;
- 第三行是在最小的特征图上的锚框,20x20代表深层的特征图(P5),包含更多高层级的信息,如轮廓、结构等信息,适合用于大目标的检测,所以这一特征图所用的anchor尺度较大。
待验证注释:
查阅其他博主博客发现,Yolov5也可以不预设anchor,直接写个3,此时yolov5就会自动按照训练集聚类anchor:
# Parameters nc: 4 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: 3
在目标检测任务中,一般希望在大的特征图上去检测小目标,因为大特征图含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,而小特征图上数值设置为大数值检测大的目标,yolov5之所以能高效快速地检测跨尺度目标,这种对不同特征图使用不同尺度的anchor的思想功不可没。
2、自适应锚框计算
- Yolov5 中并不是只使用默认锚定框,在开始训练之前会对数据集中标注信息进行核查,计算此数据集标注信息针对默认锚定框的最佳召回率。当最佳召回率大于或等于0.98,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。
- 核查锚定框是否适合要求的函数在 ./utils/autoanchor.py 文件中:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
"""AutoAnchor utils."""
import random
import numpy as np
import torch
import yaml
from tqdm import tqdm
from utils import TryExcept
from utils.general import LOGGER, TQDM_BAR_FORMAT, colorstr
PREFIX = colorstr("AutoAnchor: ")
def check_anchor_order(m):
"""Checks and corrects anchor order against stride in YOLOv5 Detect() module if necessary."""
a = m.anchors.prod(-1).mean(-1).view(-1) # mean anchor area per output layer
da = a[-1] - a[0] # delta a
ds = m.stride[-1] - m.stride[0] # delta s
if da and (da.sign() != ds.sign()): # same order
LOGGER.info(f"{PREFIX}Reversing anchor order")
m.anchors[:] = m.anchors.flip(0)
@TryExcept(f"{PREFIX}ERROR")
def check_anchors(dataset, model, thr=4.0, imgsz=640):
"""Evaluates anchor fit to dataset and adjusts if necessary, supporting customizable threshold and image size."""
m = model.module.model[-1] if hasattr(model, "module") else model.model[-1] # Detect()
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
def metric(k): # compute metric
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
best = x.max(1)[0] # best_x
aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1 / thr).float().mean() # best possible recall
return bpr, aat
stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
anchors = m.anchors.clone() * stride # current anchors
bpr, aat = metric(anchors.cpu().view(-1, 2))
s = f"\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). "
if bpr > 0.98: # threshold to recompute
LOGGER.info(f"{s}Current anchors are a good fit to dataset ✅")
else:
LOGGER.info(f"{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...")
na = m.anchors.numel() // 2 # number of anchors
anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
new_bpr = metric(anchors)[0]
if new_bpr > bpr: # replace anchors
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
m.anchors[:] = anchors.clone().view_as(m.anchors)
check_anchor_order(m) # must be in pixel-space (not grid-space)
m.anchors /= stride
s = f"{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)"
else:
s = f"{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)"
LOGGER.info(s)
def kmean_anchors(dataset="./data/coco128.yaml", n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
"""
Creates kmeans-evolved anchors from training dataset.
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
npr = np.random
thr = 1 / thr
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k, verbose=True):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
s = (
f"{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n"
f"{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, "
f"past_thr={x[x > thr].mean():.3f}-mean: "
)
for x in k:
s += "%i,%i, " % (round(x[0]), round(x[1]))
if ver 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9141
9141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









