







1.定义属性层次的变换
分类:标称(=,≠),序数(>,<)
数值:区间(+,-),比率(*,/)
非对称的二元属性:只有非零属性值重要的二元属性
2.数据质量
测量误差和数据收集错误
噪声noise和伪像artifact(数据的确定性失真)
精度precision、偏置bias、准确率accuracy
离群点outlier
遗漏值omission
不一致的值
数据重复deduplication -> 数据清洗
3.数据预处理
1.聚集:数据归约导致的较小数据集需要较少的内存和处理时间,因此可以使用开销更大的数据挖掘算法;聚集起到了范围或标度转换的作用;对象或属性群的行为通常比单个对象或属性的行为更加稳定。
2.抽样:无放回抽样、有放回抽样、分层抽样、渐近抽样
3.维灾难与维归约
维灾难:维数过高,造成巨额计算量,同时由于数据在所占据的空间中稀疏,导致分类和聚类容易过拟合
维归约:PCA主成分分析、SVD奇异值分解
4.特征子集选择:嵌入、过滤、包装
5.特征创建:特征提取 + 映射数据到新空间 + 特征构造
6.离散化和二元化
二元化的目的:使数据呈现对称结构,避免了非对称结构带来的属性不确定依赖关系
离散化的分类:非监督离散化(等宽、等频率、等深)监督离散化(熵判据)
7.变量变换:规范化、标准化:x’=(xi-mean(sum(xi)))/var(xi)
4.相似性和相异性的度量

1)距离
等距特征映射Isometric mapping
对于类似流形数据manifold data,谈及距离的时候通常指的不是欧氏距离,我们需要通过其他距离度量方式测定其geodesic distance:

Minkowski Distance:
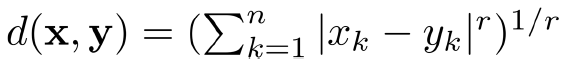
r=1:Hamming Distance
r=2:Euclidean Distance
r=∞:Chebyshev Distance max(|x2-x1|,|y2-y1|)
Mahalanobis Distance
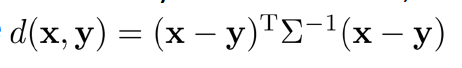
性质:非负性、对称性、三角不等式d(x,z)<=d(x,y)+d(y,z)
2)相似性度量
二元数据:
Simple Matching Coefficients
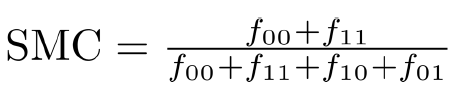
Jaccard Coefficients(考虑了非对称属性)
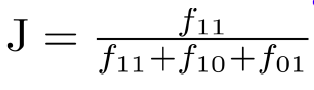
余弦相似度:二进制Jaccard Coefficients的推广
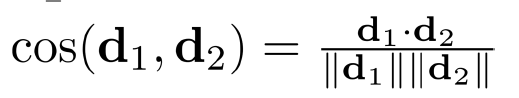
广义Jaccard系数EJ
相关性:

3)Bergman散度
D(x,y)=f(x)-f(y)-<df(y),(x-y)>
4)邻近度计算问题
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









