







 超级会员免费看
超级会员免费看
专栏亮点
- 从最基础部分开始逐步讲解爬虫技术。包括但不限于:了解爬虫,解析网页,截取数据包;互斥锁、线程池、缓存技术助力异步并发爬虫;selenium自动化技术,不仅仅可用于爬虫领域;还有scrapy框架作为压轴。
- 教你熟练掌握Python爬虫全部流程。解决当面对一个陌生网页时,如何用更简单、更快更便捷的操作流程完成任务。
- 注重实战演练。系列中带有四次项目演练,覆盖重要知识点,做点对点训练,反复加深对爬虫技术的认知。
- 知识点讲解详细,图文并茂。
- 有专门答疑群。学习过程中遇到难点,可以直接在群里发问,实时解答。群号在文末给出。
为什么要学爬虫
其实学习爬虫的原因和对我们以后发展的帮助是显而易见的。
从实际应用的角度来看,我们目前的时代是大数据的时代,而大数据时代,不可避免的就要进行数据分析。而掌握爬虫技术,可以使得我们在数据采集的时候省下不少心力,获取更多的数据。
从就业的角度来说,爬虫工程师目前属于紧缺型人才,并且薪酬待遇普遍较高,所以,深层次的掌握这门技术,对于就业来说,也是非常有利的。
随着大数据时代的发展,爬虫技术的应用将越来越广泛,在未来会有更好的发展空间。
让我们一起做时代的弄潮儿吧!!
专栏思路与内容大纲
本专栏将以以下几个阶段展开:
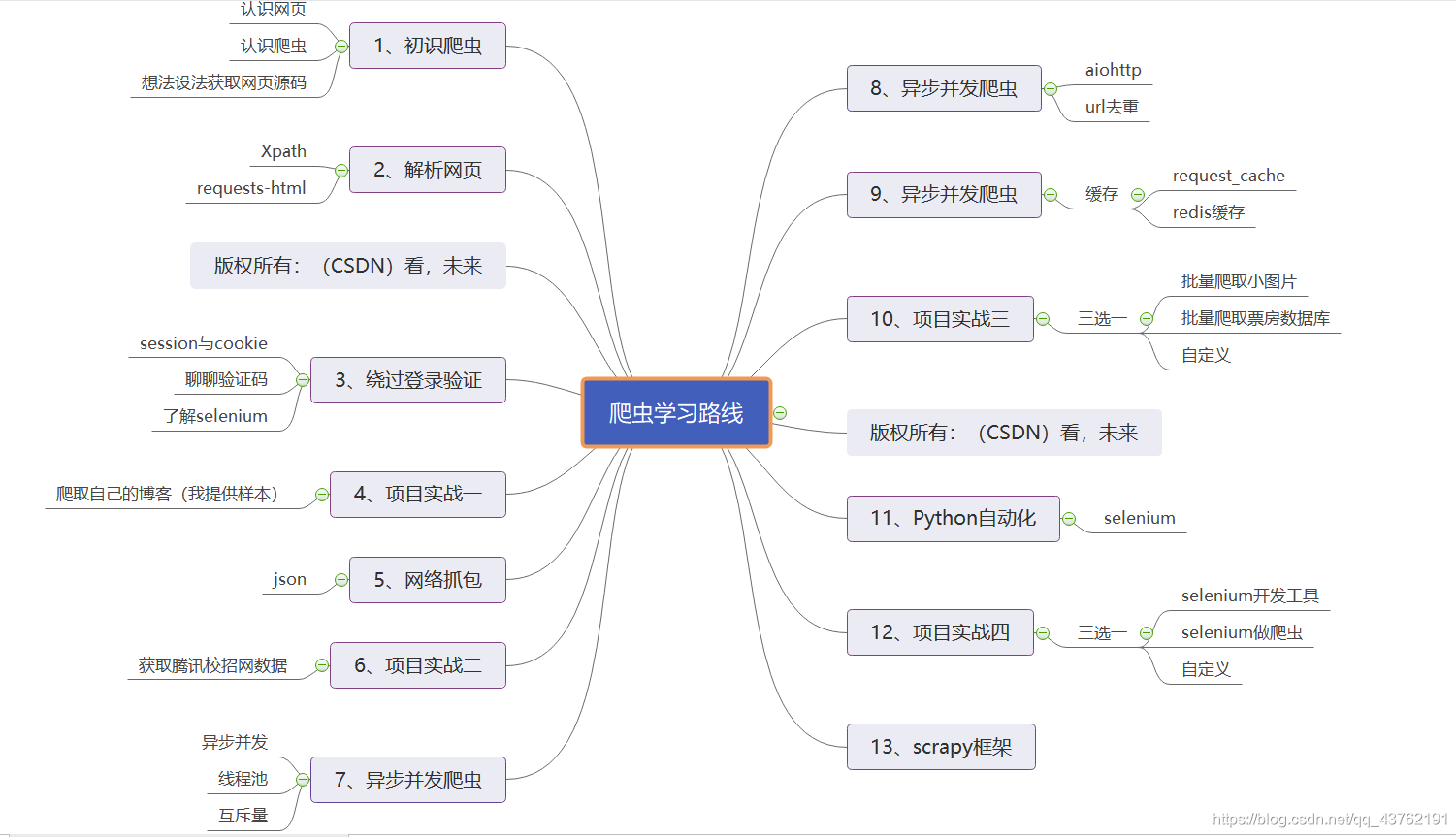
- 第一部分:初识爬虫
- 1、获取网页源码
- 2、Xpath解析网页
- 第二部分:爬虫入门
- 3、绕过登录验证
- 4、项目实战一:获取我的CSDN全部博客链接;获取电影票房数据库第三、第四也数据(需登录)
- 5、网络抓包
- 6、项目实战二:获取腾讯校招网数据;获取“掌上高考”全部高校主页网址
- 第三部分:爬虫进阶
- 7、异步并发爬虫(1):互斥量、线程池
- 8、异步并发爬虫(2):url去重
- 9、异步并发爬虫(3):缓存
- 10、项目实战三:(三选一)1、获取电影票房数据库中所有的电影票房数据;2、获取全部高校主页内容;3、批量爬取小图片
- 第四部分:Python自动化:selenium帮你解放双手
- 11、selenium自动化
- 12、项目实战四:(二选一)1、selenium做一个自动化工具;2、selenium做爬虫
- 第五部分:scrapy框架
- 13、scrapy框架
接下来,就是“爬虫百战穿山甲”的爬虫百例教程、
另外有一篇导读,和一篇总结。
(图中项目微调,微调也是为了涵盖更多的知识点、)
系列适用人群
有Python基本语法基础的人。
不喜欢枯燥乏味的填鸭式教育的朋友。
作者介绍
看,未来
CSDN博客专家,python领域优质创作者。
python专栏有:《我要偷偷的学Python,然后惊呆所有人》、《从零开始,学会Python爬虫不再难!!!》、《上手Pandas,玩转数据分析》等。
带过三个Python基础入门班,两个Python爬虫班,有一些自己的感悟和方法。
答疑群
一起偷偷学Python:1160678526(近两千人,活跃度高)
爬虫百战穿山甲:418042457(近四百人,我的爬虫团队在维护)
各位可根据自己的情况选择进入哦。
如果喜欢我的专栏风格,欢迎大家订阅呦。
















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











