







RTDETR更换Lion优化器
论文:https://arxiv.org/abs/2302.06675
代码:https://github.com/google/automl/blob/master/lion/lion_pytorch.py

简介:
Lion优化器是一种基于梯度的优化算法,旨在提高梯度下降法在深度学习中的优化效果。Lion优化器具有以下几个特点:
-
自适应学习率:Lion优化器能够自动调整学习率,根据每个参数的梯度情况来自适应地更新学习率。这使得模型能够更快地收敛,并且不易陷入局部最优点。
-
动量加速:Lion优化器引入了动量概念,通过积累历史梯度的一部分来加速梯度更新。这样可以增加参数更新的稳定性,避免陷入震荡或振荡状态。
-
参数分布均衡:Lion优化器通过分析模型参数的梯度分布情况,对梯度进行动态调整,以实现参数分布的均衡。这有助于避免某些参数过于稀疏或过于密集的问题,提高模型的泛化能力。
与AdamW 和各种自适应优化器需要同时保存一阶和二阶矩相比,Lion 只需要动量,将额外的内存占用减半;
由于 Lion 的简单性,Lion 在我们的实验中具有更快的运行时间(step/s),通常比 AdamW 和 Adafactor 提速 2-15%;
优化器代码:
# Copyright 2023 Google Research. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""PyTorch implementation of the Lion optimizer."""
import torch
from torch.optim.optimizer import Optimizer
class Lion(Optimizer):
r"""Implements Lion algorithm."""
def __init__(self, params, lr=1e-4, betas=(0.9, 0.99), weight_decay=0.0):
"""Initialize the hyperparameters.
Args:
params (iterable): iterable of parameters to optimize or dicts defining
parameter groups
lr (float, optional): learning rate (default: 1e-4)
betas (Tuple[float, float], optional): coefficients used for computing
running averages of gradient and its square (default: (0.9, 0.99))
weight_decay (float, optional): weight decay coefficient (default: 0)
"""
if not 0.0 <= lr:
raise ValueError('Invalid learning rate: {}'.format(lr))
if not 0.0 <= betas[0] < 1.0:
raise ValueError('Invalid beta parameter at index 0: {}'.format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError('Invalid beta parameter at index 1: {}'.format(betas[1]))
defaults = dict(lr=lr, betas=betas, weight_decay=weight_decay)
super().__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
"""Performs a single optimization step.
Args:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
Returns:
the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
# Perform stepweight decay
p.data.mul_(1 - group['lr'] * group['weight_decay'])
grad = p.grad
state = self.state[p]
# State initialization
if len(state) == 0:
# Exponential moving average of gradient values
state['exp_avg'] = torch.zeros_like(p)
exp_avg = state['exp_avg']
beta1, beta2 = group['betas']
# Weight update
update = exp_avg * beta1 + grad * (1 - beta1)
p.add_(update.sign_(), alpha=-group['lr'])
# Decay the momentum running average coefficient
exp_avg.mul_(beta2).add_(grad, alpha=1 - beta2)
return loss
将上述代码复制粘贴在ultralytics/engine下创建lion_pytorch.py文件。

在ultralytics/engine/trainer.py中导入Lion
from ultralytics.engine.lion_pytorch import Lion
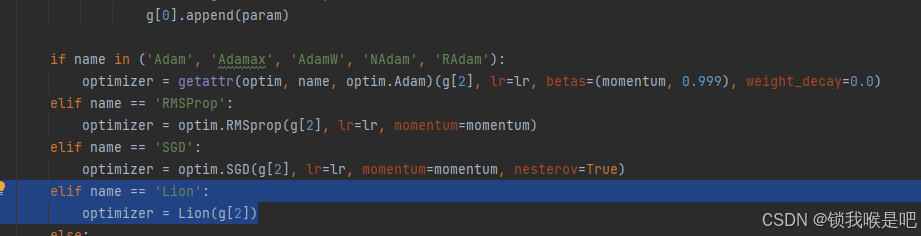
然后在def build_optimizer(self)函数中加入下列代码
elif name == 'Lion':
optimizer = Lion(g[2])
之后就可以在训练时使用Lion优化器了
results = model.train(data="ultralytics/cfg/datasets/coco.yaml", epochs=500, batch=16, workers=8,
resume=False,
close_mosaic=10, name='cfg', patience=500, pretrained=False, cos_lr=True,optimizer ='Lion',
device=1) # 训练模型















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









