







Xu N, Mao W, Chen G. A co-memory network for multimodal sentiment analysis[C]//The 41st international ACM SIGIR conference on research & development in information retrieval. 2018: 929-932.(CCF A类)
目录
(1)Text-guided Visual Memory Network(TgVMN)
(2)Image-guided Textual Memory Network(IgTMN)
一、本文贡献
- 提出一个新的co-memory network,该网络是第一次在多模态情感分析中对视觉信息和文本信息相互影响进行建模的模型。
- 设计一个co-memory注意力机制来捕获视觉内容和文本单词的交互,迭代式的进行如下过程:文本信息查找视觉关键内容,输入图像信息查找文本关键词。
- 实验结果证实了co-memory network的性能超越了当时的SOTA。
二、模型架构如下图所示:
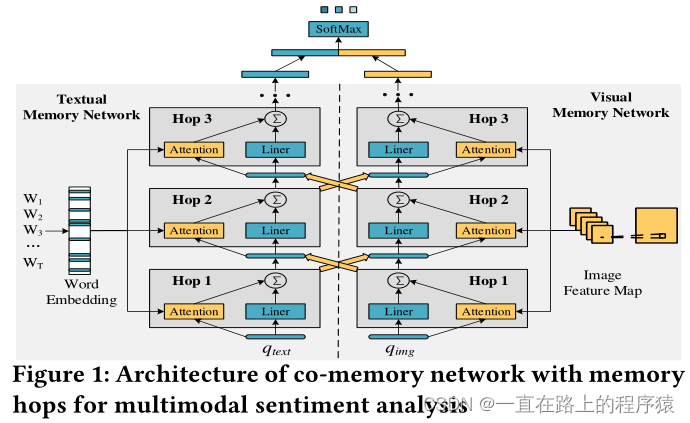
1.特征提取部分
(1)图像特征提取
使用预训练的CNN提取图像的视觉特征向量,本文将获得的特征向量称之为visual memory pieces,得到L个feature map,每一个是N*N的张量,将每一个特征图flatten,得到如下的向量矩阵M。
![]()
将M和visual query vector作为visual memory network的输入。将M中的每个mi送入单层感知机得到图像的隐藏表示hi。
![]()
使用hi和q-img之间的相似度来衡量对特征图感兴趣的程度,使用注意力机制来实现。
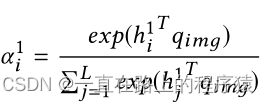
视觉查询向量q-img是随机初始化的,在模型训练期间可学习。
最后,对所有的mi进行加权求和,来选择性的关注图像的某些内容。
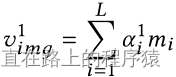
上标1意味着是hop1的视觉输出
(2)文本特征提取
对文本使用Glove方法进行编码,编码结果如下所示:
![]()
与图像部分的操作类似,矩阵X和textual query vector q-text作为textual memory network的输入,通过一个单层感知机得到文本的隐藏表示gt。
![]()
随后使用注意力机制,其中q-text作为query,gt中的向量作为key和value,计算注意力权重。
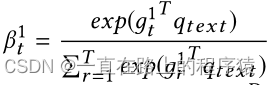
对xt进行加权求和获得文本表示,实现对文本中富含情感信息单词的关注。
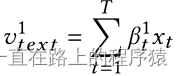
同样的,文本查询输入q-text也是随机初始化的,在模型训练期间可以进行学习。
2.co-memory network
(1)Text-guided Visual Memory Network(TgVMN)
该模块使用文本表示向量寻找关键的feature map。首先,将文本表示向量𝑣𝑡𝑒𝑥𝑡1和每一个特征图向量mi做concat操作。其次,将新的视觉记忆向量[mi,𝑣𝑡𝑒𝑥𝑡1]作为单层感知机的输入获得新的视觉隐藏表示h𝑖2。
![]()
通过h𝑖2输出新的视觉注意权重,随后使用加权求和的方法,得到第二个hop的视觉输出𝑣im𝑔2。
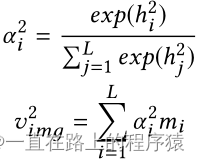
(2)Image-guided Textual Memory Network(IgTMN)
类似于(1)中的方法,最终得到第二个hop的文本输出𝑣tex𝑡2。![]()
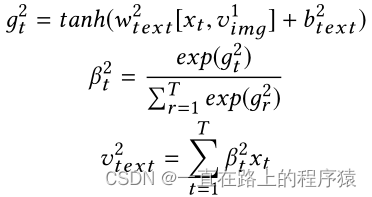
(3)Stacked Co-memory Network
采用堆叠多个Co-memory网络的方式,通过新更新的文本和图像表示,迭代地查询原始的图像记忆矩阵和文本记忆矩阵来探索文本和图像之间的微妙关系。
第k个memory hop的输出如下所示:
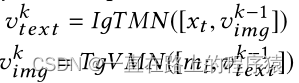
3.Sentiment Classification
在几个memory hop之后,联合最终的图像和文本的特征表示作为softmax层的输入进行情感分类。
![]()
三、注意力可视化
在一个消极的多模态tweet上,对最后一个co-memory注意力层的输出进行可视化,可视化结果如下所示:
















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









