







前言
在我们日常开发中,对于 数据库 的操作我们叫做CRUD,而CRUD永远离不开两个字:读 、 写。
其中「读」是:查询,「写」是:增加、删除、修改。那么开发对数据库的代码操作需要注意的事项,始终离不开对「读」和「写」的注意事项。
数据库「读」的注意事项
在不考虑‘数据库’层面的因素下,我们只从‘代码’层面看「读」操作。有以下几点需要注意:
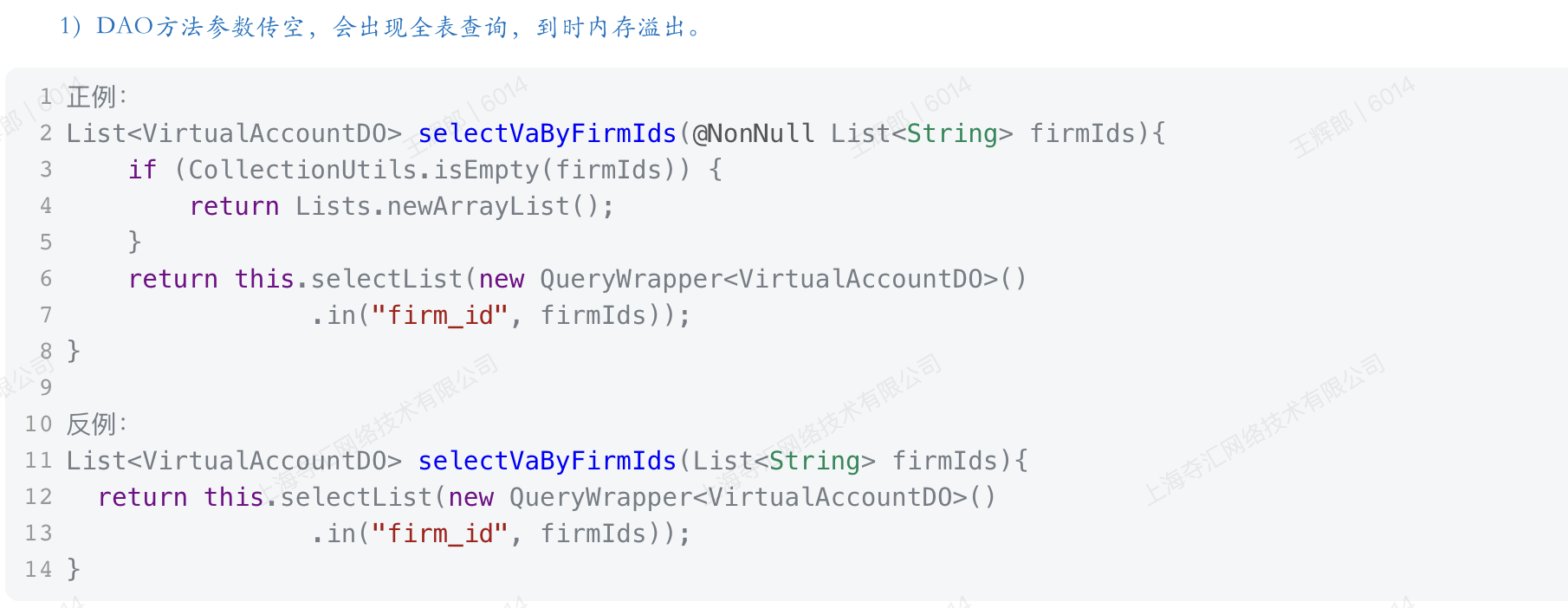
- 1、参数校验。where后面的条件参数是否有效(防止全表查询);
- 2、结果预算。查询的结果会占用多大的内存(防止OOM);
- 3、性能评估。即使SQL中的条件符合我们的预期,那这条SQL在表中执行的性能如何呢?【MySQL数据库】MySQL慢查询的危害
以这段代码为例:
List<VirturalAccountDO> selectVaByFirmIds(List<String> firmIds){
return this.selectList(new QueryWrapper<VirturalAccountDO>()
.in("firm_id", firmIds));
}首先来看‘参数’部分。firmIds作为入参,也是作为sql中where后面的条件,开发人员犯了一个致命的错误,就是没有对firmIds进行参数校验,那么当firmIds为空时,这条语句就会查询出该表所有的数据。
再来看看查询结果。由于where后面的条件失效,查询出该表的所有数据,结果集过大,那么就非常有可能造成OOM。即使where后面的条件生效,你也必须对查询出的结果内存大小做个预算,甚至备用方案,以防止结果集过大造成OOM。
正确的做法应该是这样:
数据库「写」的注意事项
在不考虑‘数据库’层面的因素下,我们只从‘代码’层面看「写」操作。有以下几点需要注意:
- 1、参数校验。where后面的条件参数是否有效(防止全表更新);
上面「读」代码的示例也同样适用于「写」,如果不对参数进行校验,那么可能造成全表更新。
经验教训
一、CRUD业务操作
1、增加
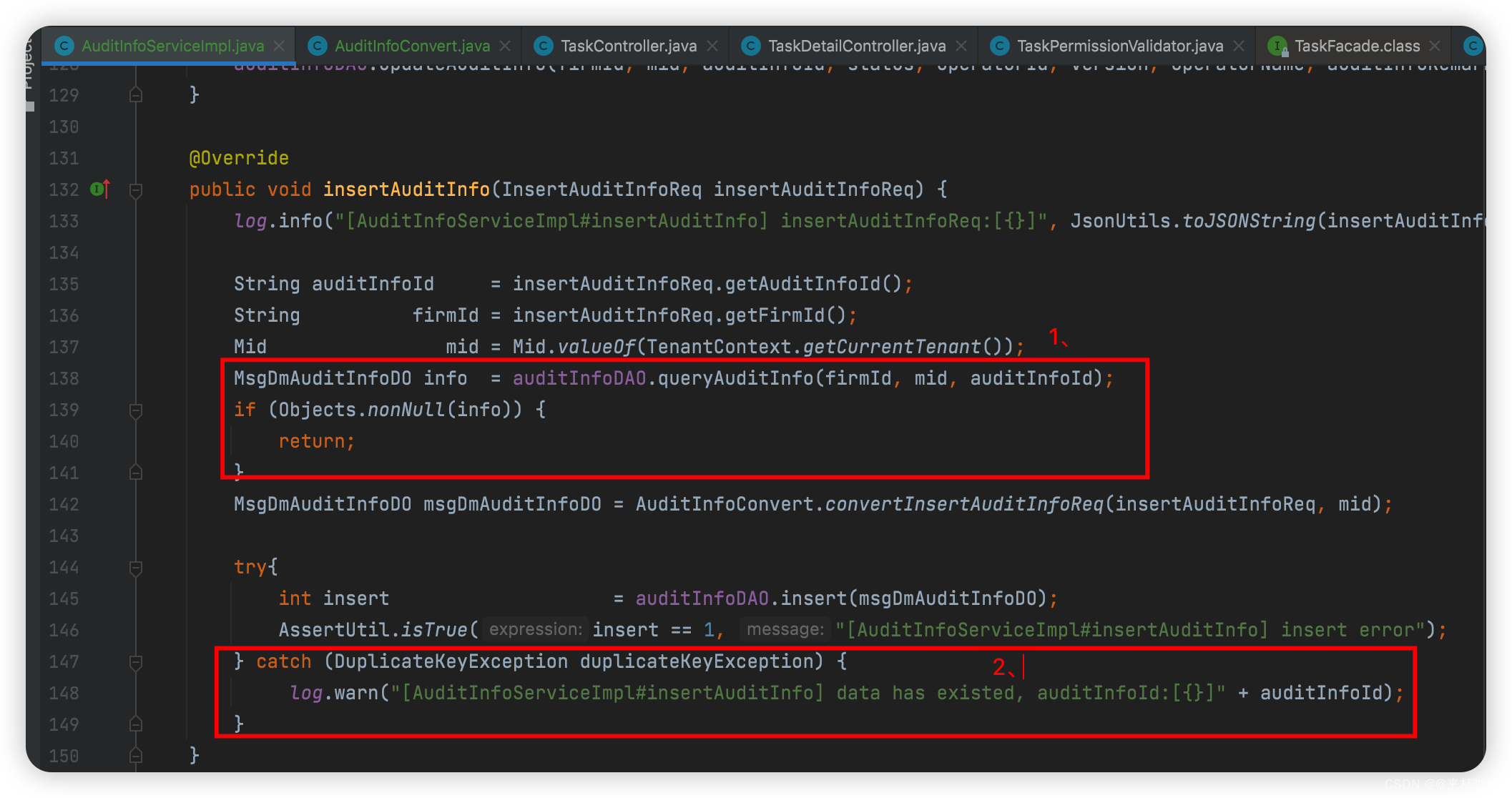
你需要【重点考虑】幂等。此处,我是借助数据库的唯一索引实现幂等操作(这种方式也可以用作MQ处理幂等)。
步骤:
1、先从数据库中查询,如果已经查到,说明该记录数据库已经存在,则return;
-- 这一步可以解决大部分的并发问题,但是有一种场景解决不了:数据库在「可重复读」隔离级别下,事务1已经插入数据库但是事务1还没有commit,此时事务2来读的时候是读取不到的,此时138行的info为null(实际事务1已经把数据插入到了数据库),那么事务2将再次执行一个插入操作。
2、为了解决上面的场景,我们给数据库中的auditInfoId(雪花算法计算出的唯一值)添加唯一索引(或者根据你的业务场景,以多个列作为唯一索引),那么当事务2执行插入操作,就会报DuplicateKeyException异常,我们catch住,做个日志输出即可。
2、查询
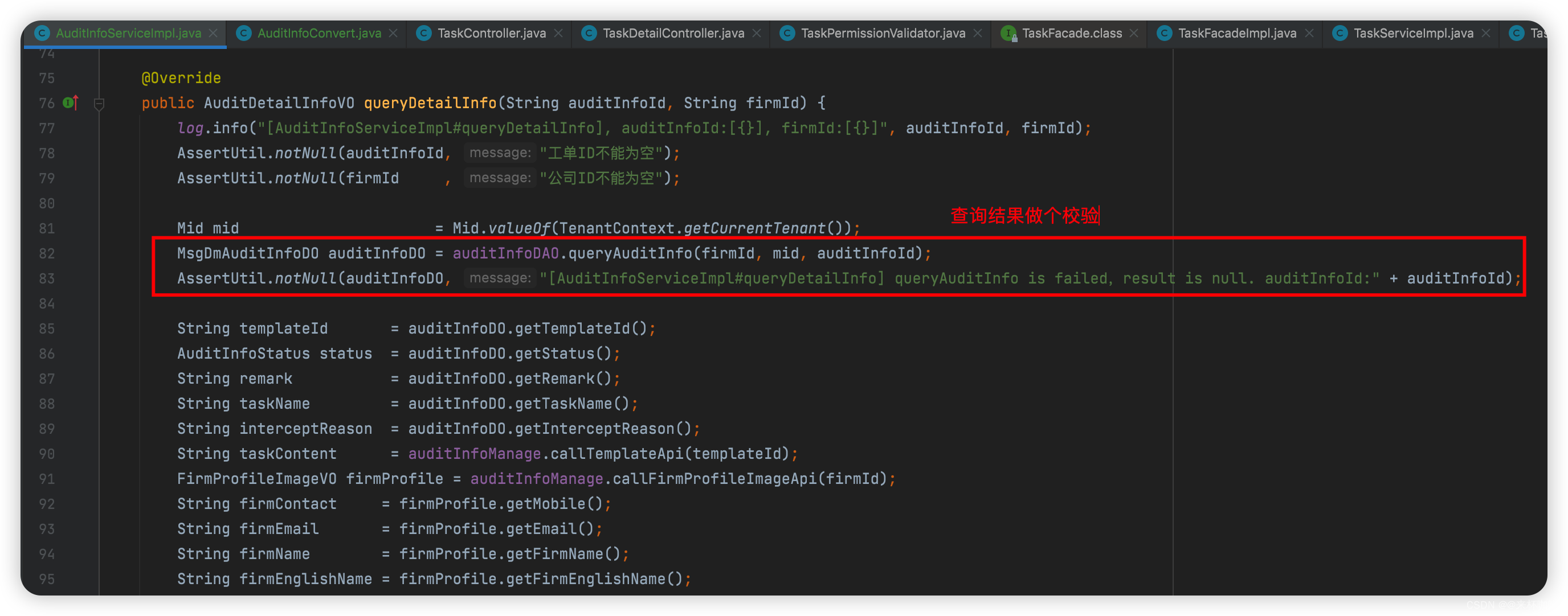
1、留意输出一下日志;
3、修改、删除
我们一般用的都是「逻辑删除」,此处把删除和修改归为一类。
1.幂等问题
(1)场景分析
update幂等问题,主要是从下面两种场景考虑的:
- 场景1: 业务幂等。 从a状态修改为b状态,每修改完一次就往mq发送消息。数据库初始状态必须是a状态,明明已经修改过了,然后此次再发请求(数据库里面已经是b状态了),那就重复往mq发送消息了。
- 场景2:操作幂等。 update是计数类的,每次的update请求都是将数据库里面的value进行加法,必须要考虑幂等问题。
(2)示例演示
下面我们以【非计数类】修改为例,进行演示。
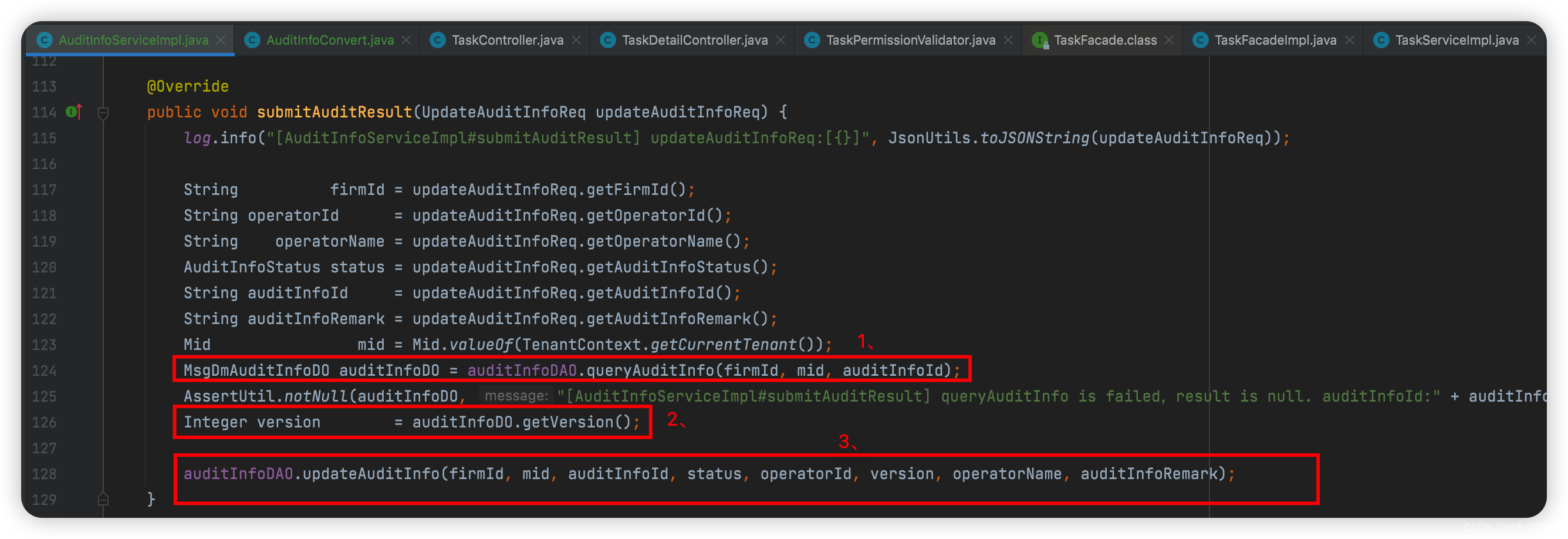
步骤:
1、修改之前,我们需要确保数据库中该数据是否真实存在?
2、查询出结果之后,将该数据的version记录下来,使用乐观锁的方式进行修改;这样即使后端接收到前端两次请求
3、最后,再执行我们的修改操作。
思考:
以上代码的业务背景是:管理员来对工单进行审核(修改),并发量很低。并且,你可以理解为是「非计数性的修改」(非++、--操作)。
扩展点来想:如果是几千个用户,对一类商品进行下单,此处代码是来处理库存,那么就是「计数性的修改」(可以理解是++、--操作),那么上面的代码肯定不符合要求。根据业务场景分析:如果业务场景是钱相关的计数性的变化,肯定需要一个‘记录表’,让两个表放到同一个事务里面(不要用redis,因为数据一致性无法控制,万一redis错或者MySQL错没法玩了);如果业务场景不是很重要且并发不是很高(千分之一概率),那么是可以忍受最终结果有误差的。
我们必须搞明白:并发是针对临界资源的,也可以理解是共享资源。根据用户行为来分析:如果几千甚至上万个用户只是来修改各自的用户名、性别,那么这些数据对整个系统而言都是用户私有的,用户数量多造成QPS高但是并发不是很高(因为修改自己的用户名等不涉及共享资源);如果是几千甚至上万个用户来抢10个手机,那么10就是共享资源,这时候的修改操作可不再是上图简单的实现了。
2.批量更新问题
问题描述:
如果你只是打算更新一条记录或者某几条记录,但是结果却【全表更新】记录。大概率是你【错误】的进行批量更新了。而这个原因可能是你的【参数值】有问题。
比如:
default void updateRecordByType(String taskId,
String recordValue {
MsgDmTaskOptRecordDO msgDmTaskOptRecordDO = new MsgDmTaskOptRecordDO();
msgDmTaskOptRecordDO.setRecordValue(recordValue);
int update = update(msgDmTaskOptRecordDO, new UpdateWrapper<MsgDmTaskOptRecordDO>()
.eq(TASK_ID, taskId)
);如果taskId为null,那么mybatisplus底层会把where后面taskid的条件过滤掉,结果sql就是:update table set record_value = xxx;批量更新。
虽然下面有解决方案,但是我不建议用。为什么呢?
因为,本身是由于你’参数未校验‘这个 错误的操作 导致 全表更新,我没有必要 一定为 你这个 错误的操作 而大量的进行 补偿措施,因为这些补偿措施会让我的代码显得特别臃肿。 这种 过度的 设计,是不太建议的。
解决方案:
(第一步)dao层必要的校验,必须加上
default void updateRecordByType(@NonNull String taskId,
@NonNull String recordValue {
AssertUtil.notNull(mid, "mid is null.");
AssertUtil.notNull(taskId, "taskId is null.");
AssertUtil.notNull(optType, "optType is null.");
MsgDmTaskOptRecordDO msgDmTaskOptRecordDO = new MsgDmTaskOptRecordDO();
msgDmTaskOptRecordDO.setRecordValue(recordValue);
int update = update(msgDmTaskOptRecordDO, new UpdateWrapper<MsgDmTaskOptRecordDO>()
.eq(TASK_ID, taskId)
.eq(DELETED, false)
);
if (updateCount != 1) {
throw new TaskTransactionException(UPDATE, "update record value error, taskId:" + taskId + ", optType:" + optType);
}
}(第二步)service调用层对这个update方法进行【事务监听】,如果发生异常则进行回滚或者其他操作。正如我们的业务场景:更新一条记录,结果updateCount!=1说明更新了多条,dao层抛出了TaskTransactionException(自定义的)异常,那我们需要对这个TaskTransactionException异常进行处理。
扩展:
如果本身就是更新多条,那我应该怎么确保我不会进行【全表批量更新】呢??
-- (1)在dao层入口处,进行条件参数校验,如果in后的条件为空则return;
(2)如果只打算更新10条,那么dao层updateCount应该 <= 10,如果大于10则抛异常,然后再service层捕获这个异常进行事务回滚。 但是如果可能存在updateCount大于10的情况,你就无法通过updateCount来进行校验了。
二、CRUD规范
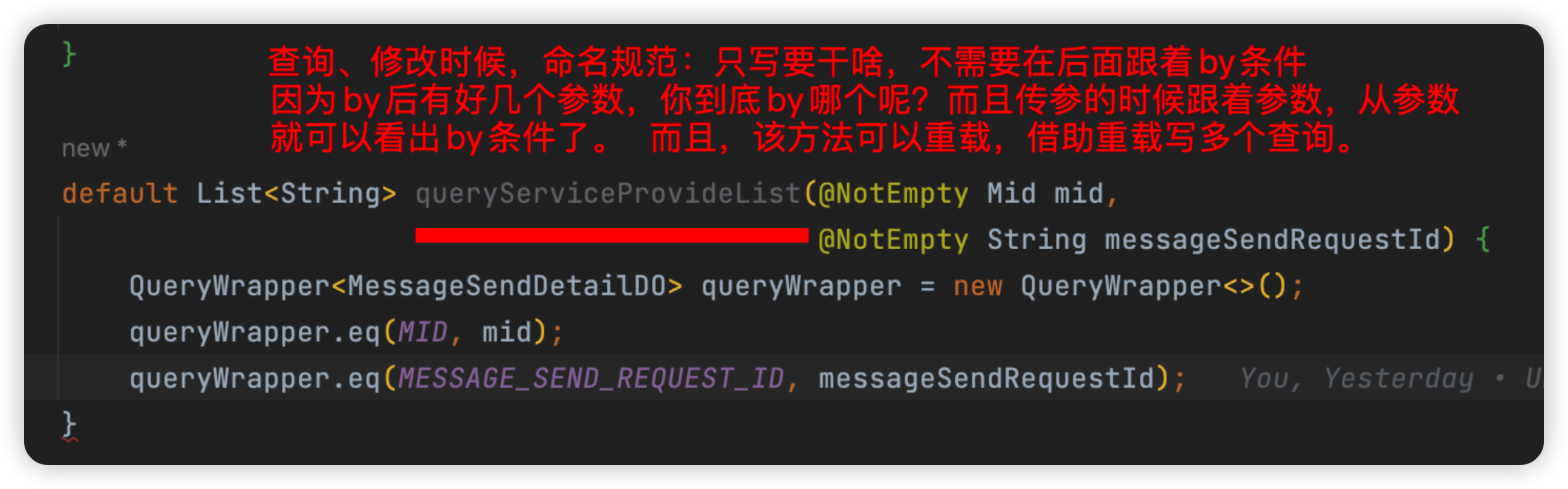
命名规范
增删改查的SQL,多用【重载】。
















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











