







os.path.join(‘…’,‘data’)
os.path.join() 用于拼接文件路径:
- 如果不存在以‘’/’开始的参数,则函数会自动加上
- 如果存在以‘’/’’开始的参数,从最后一个以”/”开头的参数开始拼接,之前的参数全部丢弃。
>>> import os
>>> print(os.path.join('path','abc','yyy'))
path\abc\yyy
>>> print('1',os.path.join('aaa','/bbb','ccc.txt'))
1 /bbb\ccc.txt
>>> print('1',os.path.join('/aaa','/bbb','ccc.txt'))
1 /bbb\ccc.txt
>>> print('1',os.path.join('/aaa','bbb','ccc.txt'))
1 /aaa\bbb\ccc.txt
- 同时存在以‘’./’与‘’/’’开始的参数,先看“/”,没有"/“时,则以”./"的上一个参数为开始位置。
>>> print('2',os.path.join('/aaa','./bbb','ccc.txt'))
2 /aaa\./bbb\ccc.txt
>>> print('2',os.path.join('aaa','./bbb','/ccc.txt'))
2 /ccc.txt
>>> print('2',os.path.join('aaa','./bbb','ccc.txt'))
2 aaa\./bbb\ccc.txt
- 所以,一定要注意/的使用!!不该用时候别乱加!!比如下面例子:
path='C:/yyy/yyy_data/'
>>> print(os.path.join(path,'/abc'))
C:/abc
>>> print(os.path.join(path,'abc'))
C:/yyy/yyy_data/abc
- 继续课程中:
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
- os.path.join(‘…’,‘data’)把data文件夹建在了系统的user目录下:
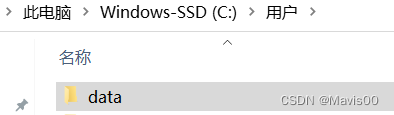
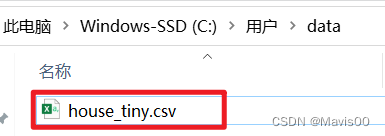
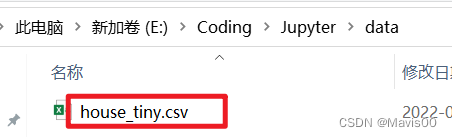
- 若想更改文件位置则需手动输入文件路径:
path = 'E:/Coding/Jupyter/'
os.makedirs(os.path.join(path, 'data'), exist_ok=True)
data_file = os.path.join(path, 'data', 'house_tiny.csv')
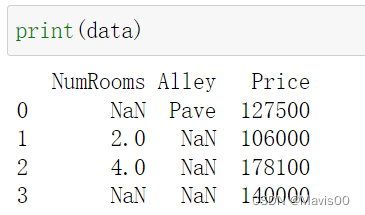
加载数据集:pandas库 read_csv()
import pandas as pd
data = pd.read_csv(data_file)
print(data)
处理缺失数据
- 常见方法——插值法、删除法: 通过位置索引iloc(就是index_location),将data分成inputs和outputs; inputs为data的前两列;
- outputs为data的最 后一列。inputs中缺少的数值用同一列的均值替换
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
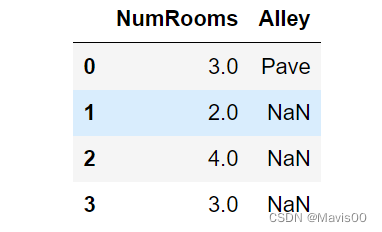
- 对于非数值列Alley:由于“Alley”列只有两种类型 “Pave”和“NaN”,pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。原来为“Pave”的行会将“Alley_Pave”和“Alley_nan”的值设置为1和0。相应地,原来为“NaN”即缺省的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
- 即:对于inputs中的类别值或离散值,将“NaN”视为一个类别
- get_dummies 是利用pandas实现one hot encode的方式,即将类别转化为0,1表示
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
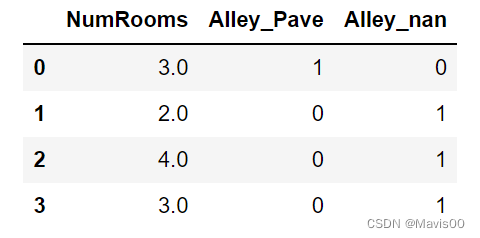
- 把各列的数值类型转化成tensor张量
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
















 1836
1836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









