







《动手深度学习》2.5反向传播自动求导
反向传播理论推导
-
从线性模型到多层神经网络,一点点理解反向传播机制

-
由于复杂网络涉及的权重过多,所以引入计算图和反向传播!

-
激活函数的引出:激活函数的存在是必要的!!!否则无论多少层的网络结构,一经化简合并就和单层网络效果是一样的!

-
forward和backward的一整套完整计算流程
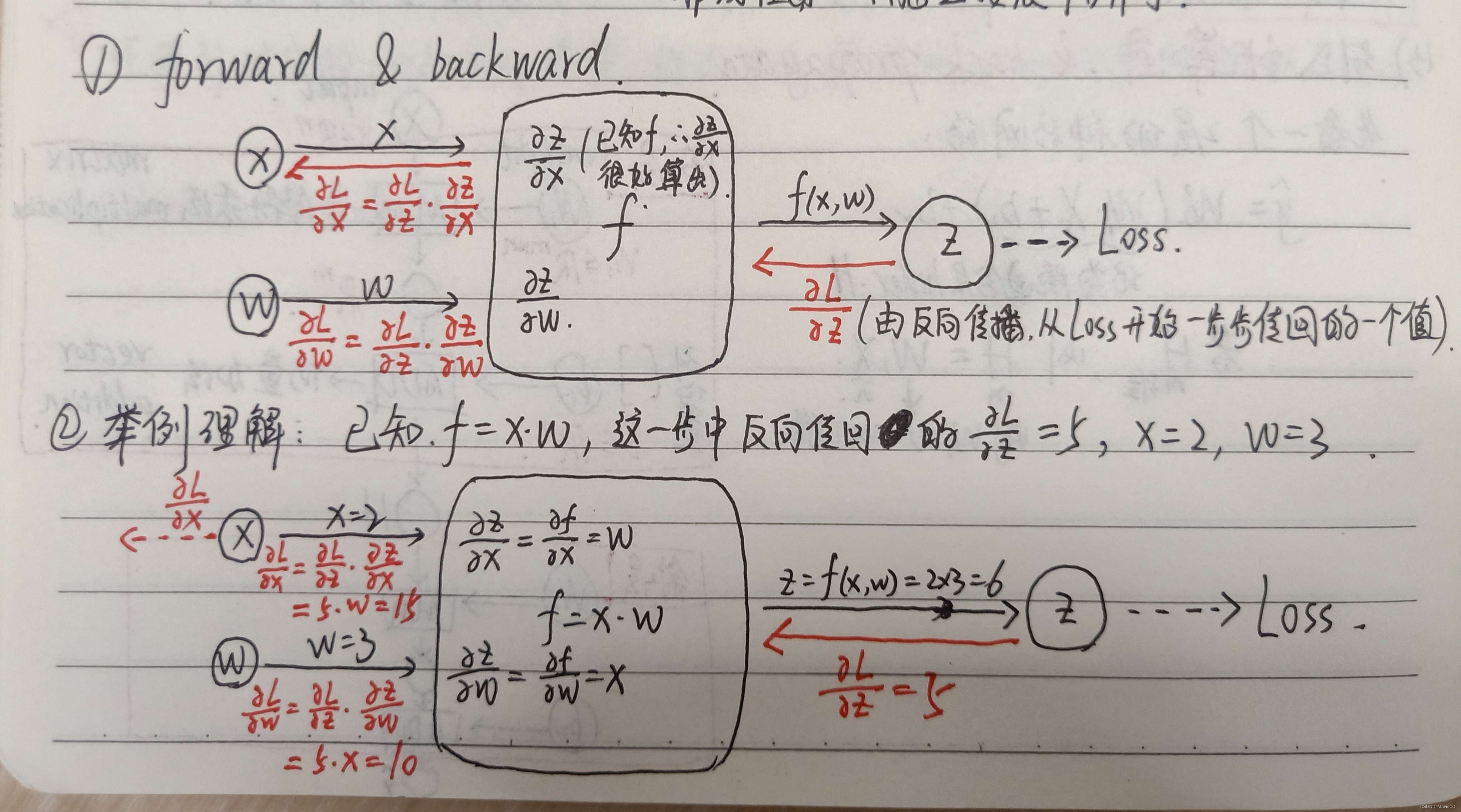

-
最后,对最简单的线性模型进行完整计算过程演示
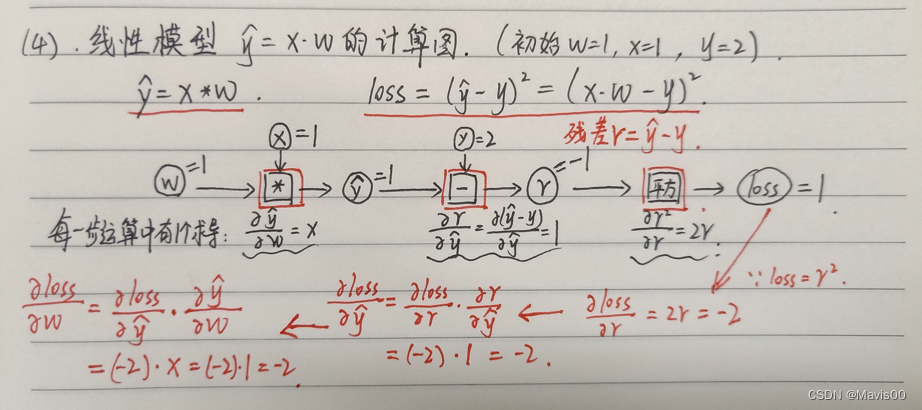
pytorch代码实战
- pytorch里的数据类型tensor包含重要的两部分:data和grad。data是w,权重值;grad是loss对w的偏导值,或者说是梯度。
初始定义基本量
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.tensor([1.0])
w.requires_grad = True #因为默认的tensor不需要计算和保存grad
- 这里的 x_data,y_data 对应着3个样本(1.0,2.0),(2.0,4.0),(3.0,6.0)
- x.requires_grad_(True) 声明x是需要梯度的!在pytorch中,如果输入需要梯度,那么中间涉及的每一步参数的梯度都会被保存下来
定义模型(构建计算图)
- 训练自己每看到一个模型定义都能够把计算图给画出来!!!
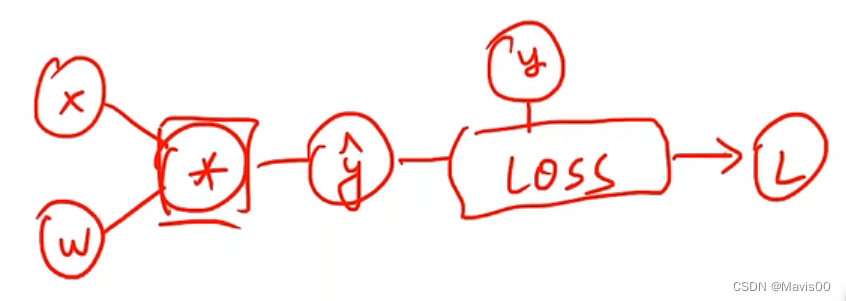
# 定义一个简单线性模型:y=x*w
def forward(x):
return x*w
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) ** 2
也就是构建了一个下图所示的计算图过程:
保留一下训练前的预测值
print("predict (before training)", 4, forward(4).item())

训练!!!
w = torch.tensor([1.0])
w.requires_grad = True #因为默认的tensor不需要计算和保存grad
for epoch in range(100):
for x, y in zip(x_data, y_data):
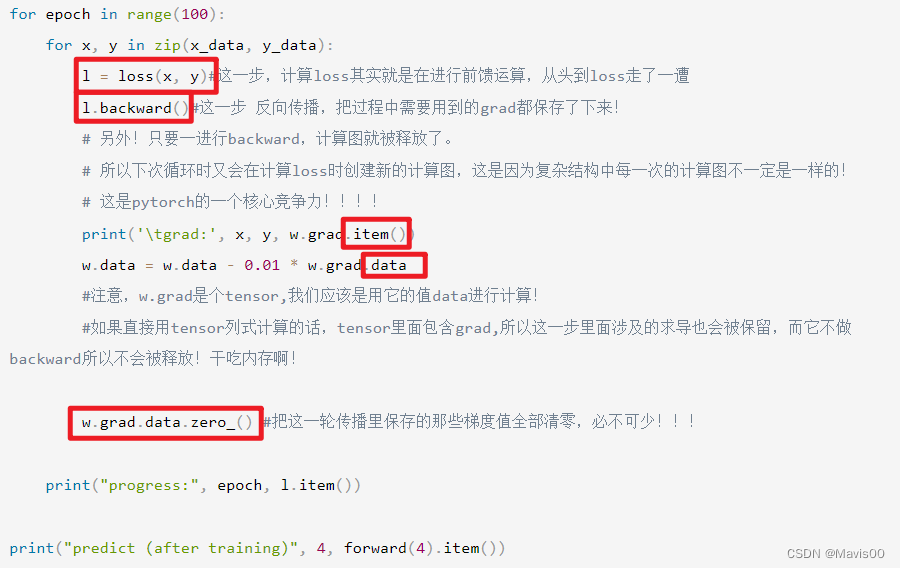
l = loss(x, y)#这一步,计算loss其实就是在进行前馈运算,从头到loss走了一遭
l.backward()#这一步 反向传播,把过程中需要用到的grad都保存了下来!
# 另外!只要一进行backward,计算图就被释放了。
# 所以下次循环时又会在计算loss时创建新的计算图,这是因为复杂结构中每一次的计算图不一定是一样的!
# 这是pytorch的一个核心竞争力!!!!
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
#注意,w.grad是个tensor,我们应该是用它的值data进行计算!
#如果直接用tensor列式计算的话,tensor里面包含grad,所以这一步里面涉及的求导也会被保留,而它不做backward所以不会被释放!干吃内存啊!
w.grad.data.zero_() ## 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值!必不可少!!!
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item())
下图是把代码里的重要步骤圈了出来:
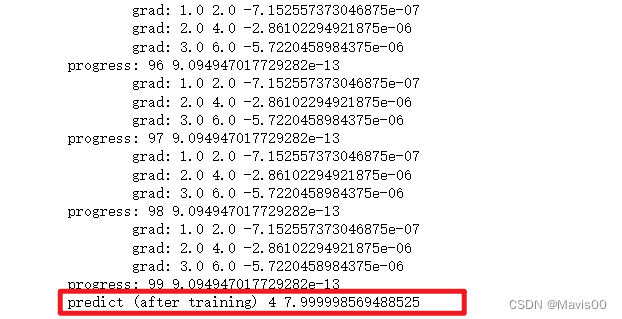
训练结果:

最终预测结果:















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









