







原博文:https://blog.csdn.net/u013384984/article/details/90718287#commentBox
作者:土豆钊
因为博文里面的理论知识看着太头疼了,就直接看故事了hh,下面有些术语不懂的原博文里面有解释
匈牙利算法的时间复杂度为O(VE),其中V为二分图左边的顶点数,E为二分图中边的数目。
二. 匈牙利算法
下面我们讨论下匈牙利算法的内容:
1. 给定一个图:
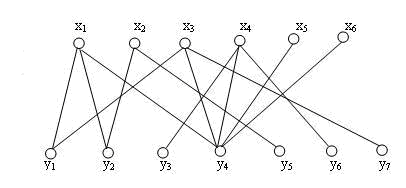
前面已经说了,我们讨论的基础是二部图,而上图就是一个二部图,我们从上图的左边开始讨论,我们的目标是尽可能给x中最多的点找到配对。
注意,最大匹配是互相的,如果我们给X找到了最多的Y中的对应点,同样,Y中也不可能有更多的点得到匹配了。
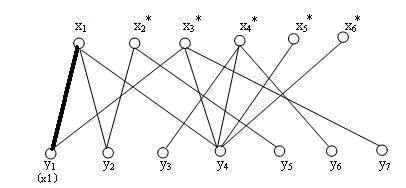
刚开始,一个匹配都没有,我们随意选取一条边,(x1, y1)这条边,构建最初的匹配出来,结果如下,已经配对的边用粗线标出:
2. 我们给x2添加一个匹配,如下图的(x2, y2)边。
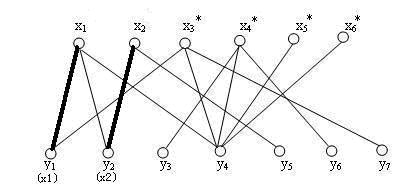
目前来看,一切都很顺利,到这里,我们形成了匹配M,其有(x1, y1), (x2, y2 ) 两条边。
3. 我们现在想给x3匹配一条边,发现它的另一端y1已经被x1占用了,那x3就不高兴了,它就去找y1游说,让y1离开x1。
即将被迫分手的x1很委屈,好在它还有其他的选择,于是 x1 妥协了,准备去找自己看中的y2。
但很快,x1发现 y2 被x2 看中了,它就想啊,y1 抛弃了我,那我就让 y2 主动离开 x2 (很明显,这是个递归的过程)。
x2 该怎么办呢?好在天无绝人之路,它去找了y5。
谢天谢地,y5 还没有名花有主,终于皆大欢喜。
匹配如下:
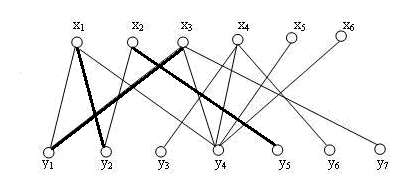
上面这个争论与妥协的过程中,我们把牵涉到的节点都拿出来:(x3, y1, x1, y2, x2, y5),很明显,这是一条路径P。
而在第二步中,我们已经形成了匹配M,而P呢?还记得增广路径么,我们发现,P原来是M的一条增广路径!
上文已经说过,发现一条增广路径,就意味着一个更大匹配的出现,于是,我们将M中的配对点拆分开,重新组合,得到了一个更大匹配,M1, 其拥有(x3, y1),(x1, y2), (x2, y5)三条边。
而这,就是匈牙利算法的精髓。
同样,x4 , x5 按顺序加入进来,最终会得到本图的最大匹配。
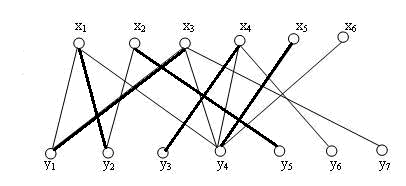
得到这个结果后,我们发现,其实也可以把y4 让给 x6 , 这样x5 就会空置,但并不影响最大匹配的大小。
总结:
1. 匈牙利算法寻找最大匹配,就是通过不断寻找原有匹配M的增广路径,因为找到一条M匹配的增广路径,就意味着一个更大的匹配M' , 其恰好比M 多一条边。
2. 对于图来说,最大匹配不是唯一的,但是最大匹配的大小是唯一的。
代码实现:
定义两部分元素X,Y,现在我们给X中的元素找匹配对象
//vector存边
//line[i]中存的是可以和i匹配的元素
vector<int>line[1000];
int ffind(int x)//试图寻找一条增广路径,让x有一个匹配对象
{
for(int i=0; i<(int)line[x].size(); i++)
{
int y=line[x][i];
if(!used[y])
{
used[y]=1;//标记y已经被访问过
if(gril[y]==-1||ffind(gril[y]))//如果y未匹配并且或gril[y]找到了新的匹配情况
/*这是一个递归,如果存在增广路径,就会返回1,并且在返回的过程中更新匹配情况*/
//比如说上文中从匹配情况(x1,y1)(x2,y2)更新到===>(x3,y1)(x1,y2)(x2,y5)三条边。
//还有一点就是当它找到增广路径时才会去跟新匹配情况
{
gril[y]=x;
return 1;
}
}
}
return 0;
}
对used数组的理解: (这个之前理解了很久,还理解错了)used数组就是针对每次寻找增广路径,设的一个数组(因为,,,每次找之前都初始化了),已经访问过的点就不再访问了,不然它可能从这个点找出去,然后又找了回来,就陷入了死循环
附一张之前的的疑问截图,感觉下面的小伙伴解释得很到位哈哈

int ans=0;//记录匹配数
for(int i=1; i<=m; i++)
{
memset(used,0,sizeof(used));
if(ffind(i))
ans++;
}
例题:过山车
#include <iostream>
#include <iostream>
#include <string.h>
#include<stdio.h>
#include<math.h>
#include<algorithm>
#include<vector>
#include<queue>
typedef long long LL;
using namespace std;
const int manx=2e5+10;
const int INF=0x3f3f3f3f;
int n,m,k,gril[manx],used[1000];
vector<int>line[1000];
int ffind(int x)
{
for(int i=0; i<(int)line[x].size(); i++)
{
int y=line[x][i];
if(!used[y])
{
used[y]=1;
if(gril[y]==-1||ffind(gril[y]))
{
gril[y]=x;
return 1;
}
}
}
return 0;
}
int main()
{
int x,y;
while(scanf("%d",&k),k)
{
for(int i=1;i<=500;i++)
line[i].clear();
memset(gril,-1,sizeof(gril));
scanf("%d%d",&m,&n);
for(int i=1; i<=k; i++)
{
scanf("%d%d",&x,&y);
line[x].push_back(y);
}
int ans=0;
for(int i=1; i<=m; i++)
{
memset(used,0,sizeof(used));
int flag=ffind(i);
if(flag)
ans++;
}
printf("%d\n",ans);
}
}















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









