










 本文概述了监督学习中的判别式模型(如线性回归、SVM和NN)与生成式模型(朴素贝叶斯和HMM),介绍了无监督学习中的生成式模型如何用于生成样本,并以山羊与绵羊案例解释概念。此外,探讨了GAN和VAE在无监督学习中的应用,以及它们在构建数据分布模型上的作用。
本文概述了监督学习中的判别式模型(如线性回归、SVM和NN)与生成式模型(朴素贝叶斯和HMM),介绍了无监督学习中的生成式模型如何用于生成样本,并以山羊与绵羊案例解释概念。此外,探讨了GAN和VAE在无监督学习中的应用,以及它们在构建数据分布模型上的作用。
文章目录
一、监督学习中的判别式模型和生成式模型
有监督学习可以分为两类:判别模型和生成模型,我们所熟悉的神经网络,支持向量机和logistic regression,决策树等都是判别模型。而朴素贝叶斯和隐马尔可夫模型则属于生成式模型
1.1 判别式模型(线性回归、SVM、NN)
判别式模型由数据直接学习 P ( y ∣ x ) P(y|x) P(y∣x)来预测 y y y
1.2 生成式模型(朴素贝叶斯、HMM)
生成式模型先对联合概率 P ( x , y ) P(x,y) P(x,y)建模(由数据学习联合概率分布 P ( x , y ) P(x,y) P(x,y)),由此求得 P ( y ∣ x ) P(y|x) P(y∣x)
以分类问题为例,我们会对每个类别建一个模型,有多少个类别,就建立多少个模型。
- 比如类别有猫、狗、猪,那我们会学出模型P(X, Y = 猫), P(X, Y = 狗), P(X, Y = 猪),即得到联合概率P(X,Y),对于一个新的样本X=忠诚,我们看一下三个模型哪个概率最高,例如P(X=忠诚, Y=狗)概率最大,我们就认为该样本属于狗这个类别。
生成式模型: P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)=\frac{P(X,Y)}{P(X)} P(Y∣X)=P(X)P(X,Y) (贝叶斯公式)
典型的生成式模型有,朴素贝叶斯模型、隐马尔可夫模型(HMM)
为什么朴素贝叶斯是生成式模型?
我的笔记:朴素贝叶斯原理
因为朴素贝叶斯是这样计算的, P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)=\frac{P(X,Y)}{P(X)} P(Y∣X)=P(X)P(X,Y),它仍然是想办法算 P ( x , y ) P(x,y) P(x,y),只不过这个联合分布没法直接算,因为 x i x_i xi与 y y y不独立,所以 P ( x 1 , x 2 , . . x n , y ) ≠ P ( x 1 ) P ( x 2 ) ⋯ P ( y ) P(x_1,x_2,..x_n,y)\neq P(x_1)P(x_2)\cdots P(y) P(x1,x2,..xn,y)=P(x1)P(x2)⋯P(y)。
为了解决联合分布没法算的问题,朴素贝叶斯先是利用贝叶斯定理对公式进行了转换
P
(
Y
∣
X
)
=
P
(
X
,
Y
)
P
(
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
P
(
X
)
P(Y|X)=\frac{P(X,Y)}{P(X)}=\frac{P(X|Y)P(Y)}{P(X)}
P(Y∣X)=P(X)P(X,Y)=P(X)P(X∣Y)P(Y),然后假设不同
x
i
x_i
xi关于
y
y
y条件独立,因此
P
(
Y
∣
X
)
=
P
(
X
,
Y
)
P
(
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
P
(
X
)
=
P
(
x
1
∣
Y
)
P
(
x
2
∣
Y
)
⋯
P
(
x
n
∣
Y
)
P
(
Y
)
P
(
X
)
P(Y|X)=\frac{P(X,Y)}{P(X)}=\frac{P(X|Y)P(Y)}{P(X)}=\frac{P(x1|Y)P(x2|Y)\cdots P(x_n|Y)P(Y)}{P(X)}
P(Y∣X)=P(X)P(X,Y)=P(X)P(X∣Y)P(Y)=P(X)P(x1∣Y)P(x2∣Y)⋯P(xn∣Y)P(Y)
此时所有的概率都是可以算的(用对应的频率替代)
1.3 两种模型的小结
本小节内容摘自知乎 Microstrong 的文章
不管是生成式模型还是判别式模型,它们最终的判断依据都是条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X),但是生成式模型先计算了联合概率 P ( X , Y ) P(X,Y) P(X,Y),再由贝叶斯公式计算得到条件概率。因此,生成式模型可以体现更多数据本身的分布信息,其普适性更广。
🕵️用山羊绵羊的例子说明概念
- 判别式模型:要确定一个羊是山羊还是绵羊,用判别式模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊🤩 是山羊的概率,是绵羊的概率。
- 生成式模型:是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征😁,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。
二、无监督学习中的生成式模型(生成样本)
无监督学习中的生成式模型跟前面提到的监督学习中的生成式模型是不一样的。
无监督学习的生成式模型的目标:希望构建一个从隐向量z生成目标数据x的模型(Generator),这样我们只要不断从隐向量z的分布中采样z,就能生成很多与真实图像极为相似的图片。
通常假设隐向量
z服从某个常见的分布(比如正态分布或均匀分布),然后希望x=g(z)模型(generator)能够把z的分布映射到接近于训练集数据的分布。
Generator可以看作是进行了数据分布之间的变换
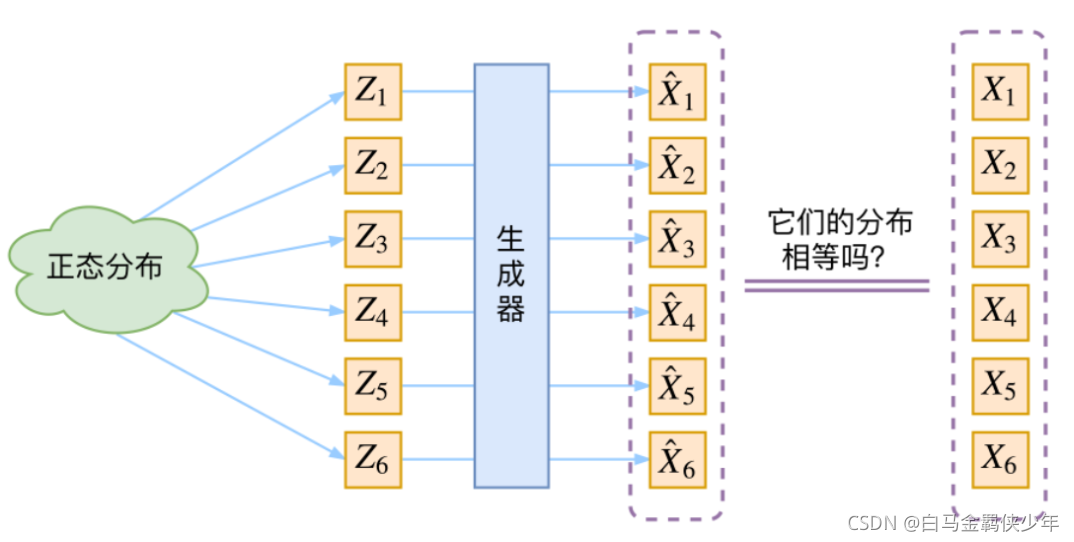
GAN和VAE都是无监督学习中常见的生成模型。
这种特殊的模型,其参数估计的目的不是通过提取特征来建立输入输出之间的映射,而是学习训练数据的分布,从而模型在应用阶段能够生成与训练数据相似的图像,通常这些图像与真实图像极为相似,我愿称之为“以假乱真”的哲学,这类模型就是无监督学习中的生成式模型。
GAN模型以及VAE模型在应用阶段生成与训练数据相似的图像?
假设我们已经训练好了Generator(GAN和VAE具体训练Generator的方式是不同的)
例如,我们用CelebA数据集训练好Vanilla VAE模型(训练阶段 z ∼ N ( u ( x ) , σ ( x ) ) ) z\sim N(u(x),\sigma(x))) z∼N(u(x),σ(x)))
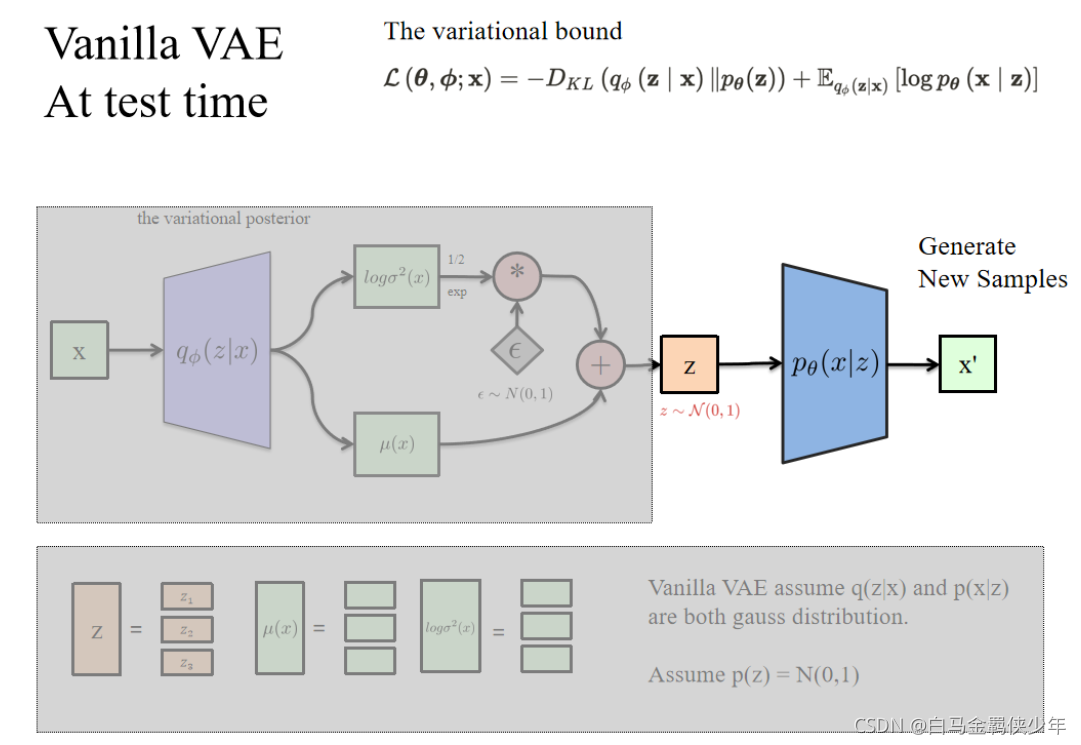
在应用阶段我们从 z ∼ N ( 0 , 1 ) z\sim N(0,1) z∼N(0,1)中采样出36个隐向量z,然后利用Generator生成的36张图片如下:



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











