







系列综述:
💞目的:本系列是个人整理为了Megatron-LM的,整理期间苛求每个知识点,平衡理解简易度与深入程度。
🥰来源:材料主要源于Megatron-LM相关材料进行的,每个知识点的修正和深入主要参考各平台大佬的文章,其中也可能含有少量的个人实验自证。
🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷!!!
请先收藏!!!,后续继续完善和扩充👍(●’◡’●)
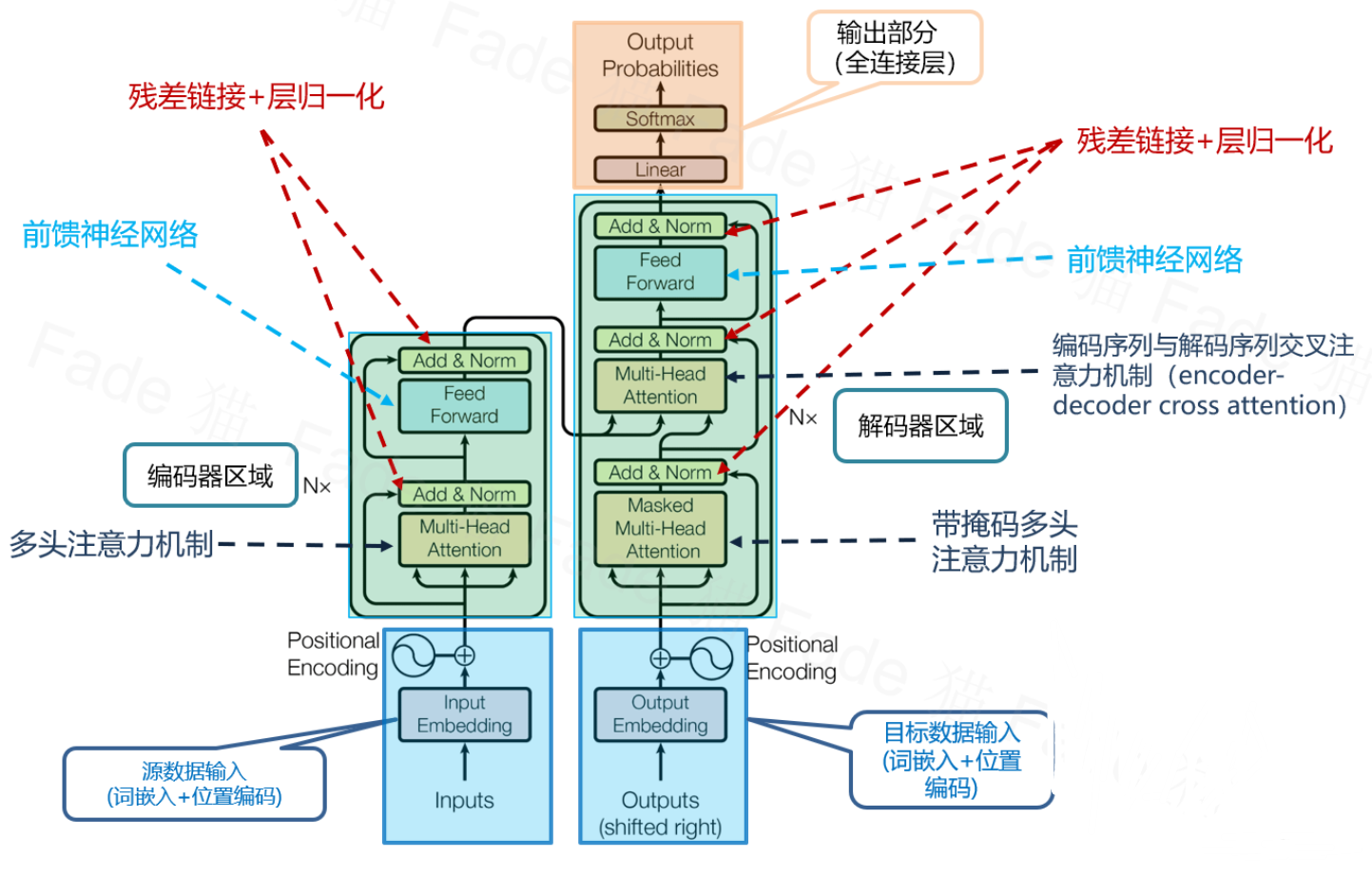
概述
介绍
- Megatron-LM简述
- 定义:基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型
- 核心技术:
- 3D 并行:数据并行、张量并行、流水线并行
- 混合精度训练
- 梯度检查点(激活重算)
- 设计目标:解决单卡显存不足问题,提升千卡级集群的扩展效率,支持万亿参数模型的训练
- 数据并行(Data Parallelism)
- 原理:
- 全量复制:每个Worker复制整个模型,即每个Worker都会有一个完整的模型副本
- 数据划分:将输入数据集被分成多个片段分配给多个Worker进行处理
- 梯度聚合:定期聚合所有Worker的梯度,以确保所有Worker看到的是一个一致的模型权重版本
- 作用:充分利用多设备的算力资源,提高训练速度
- 全局批量大小与设备数
- 问题:在数据并行中, 全局批量大小(Global Batch Size) 被分割为多个 局部批量(Local Batch Size) ,如果局部批量过小,可能导致通信占比过大,从而导致GPU计算资源的闲置
- 解决:通常要求每个GPU的局部批量≥8,以保证计算效率和收敛稳定性。若全局批量=1024,则最大可用GPU数为128(1024/8=128)。如果强行使用更多GPU,局部批量将低于8,导致上述效率问题。 最大设备数 = 全局批量大小 局部批量下限 最大设备数 = \frac{全局批量大小}{局部批量下限} 最大设备数=局部批量下限全局批量大小
- 问题:当单设备的显存容量无法满足模型体积时,数据并行将无法使用,需要将模型进行划分,从而实现模型并行
- 原理:
- 模型并行(Model Parallelism)
- 目标:将模型的内存和计算负载分布到多个工作节点上,解决大模型在单个设备上无法容纳的问题,并提高训练的效率。
- 拆分策略
- 流水线并行 :按照模型的
数据流经阶段进行拆分,从而在不同层间进行并行处理(组装 → 喷漆 → 包装”三个工序,分别由三个工人按序完成) - 张量并行 :将同一
层内参数或计算拆分到多个设备,各设备并行处理部分计算,最后合并结果。(切一个大萝卜,厨师1负责切前半段,厨师2负责切后半段,最后把两半的萝卜片合并成一盘菜)
- 流水线并行 :按照模型的
| 维度 | 流水线并行 | 张量并行 |
|---|---|---|
| 拆分方向 | 垂直(层间拆分) | 水平(层内拆分) |
| 通信对象 | 在相邻阶段通过跨界点通信Infiniband来传递激活值/梯度 | 同层设备间采用节点内NVLink结果 |
| 通信开销 | 采用P2P通信模式,数据量少且低频 | 采用all-reduce通信方式,数据量大且高频 |
| 适用场景 | 深模型:层数多、单层计算耗时的模型 | 宽模型:隐藏层维度较大、计算密集的模型 |
- 分布式训练优化原则(基于参数配置对吞吐量的影响)
- 通信量
- 张量并行:依赖
节点内高速互联(如NVLink),减少跨GPU通信开销,避免因频繁All-to-All通信导致的性能瓶颈。不适用于跨节点低带宽网络(如普通以太网) - 流水线并行:当模型深度过大(如百层以上Transformer),单节点无法容纳时,按层划分到多GPU或多节点。需合理设计微批次(microbatches)数量,使其为流水线阶段数的整数倍,以隐藏通信延迟,提升设备利用率
- 数据并行:每个批次结束后同步梯度,通信频率较低,但随
GPU数量增加,通信量可能成为瓶颈
- 张量并行:依赖
- 计算效率
- 张量并行:当模型单层参数过大(如Transformer的注意力矩阵),无法存入单个GPU显存时,将权重矩阵切分到多GPU并行计算。但是若将大矩阵
拆分过多的小矩阵,浪费GPU计算核心资源,可能导致严重GPU利用率下降 - 流水线并行:通过多阶段重叠计算,提高设备利用率,但需
平衡阶段数量与微批次大小以减少气泡 - 数据并行:适合
单GPU显存可容纳完整模型权重的情况,然后通过分割数据子集并行计算梯度,实现简单。 - 混合并行:如Megatron结合
张量并行(单机内)和流水线并行(跨节点),同时用数据并行扩展规模,最大化计算效率
- 张量并行:当模型单层参数过大(如Transformer的注意力矩阵),无法存入单个GPU显存时,将权重矩阵切分到多GPU并行计算。但是若将大矩阵
- 流水线气泡
- 气泡大小公式:流水线气泡占比为
(p-1)/m,其中,减小流水线阶段数p或增加微批次数量 m可减少气泡。 - Megatron的交错调度:通过
动态调整微批次执行顺序,使气泡占比降低,吞吐量提升10%,但需更多内存存储中间激活值
- 气泡大小公式:流水线气泡占比为
- 通信量
- Megatron-Deepspeed框架
- 主要技术
- Megatron-LM 是由 NVIDIA 的应用深度学习研究团队开发并开源的大型、强大的 transformer 模型框架。
- DeepSpeed 是由Microsoft开源的一个深度学习优化库,让分布式训练变得简单、高效且有效。
- 1
- 主要技术
并行策略
张量并行
1维(1D )张量并行(Megatron-LM)
- 背景
- 前提:随着大语言模型参数规模突破千亿级别(如GPT-3、Megatron-Turing NLG等),单个GPU的显存和算力已无法满足需求
- 问题:传统的数据并行(Data Parallelism)仅能切分数据批次,无法解决显存不足问题,而纯模型并行(层间拆分)因计算依赖性强导致设备利用率低
- 解决:1D张量并行(Tensor Parallelism) 作为一种层内并行技术被提出,核心思想是将Transformer层的矩阵运算(如MLP、Self-Attention)拆分为多个子矩阵,分布到多GPU上并行计算
- 概述
- 定义:1D张量并行是一种按单一维度(行或列)拆分权重矩阵的并行策略
按单一维度(行或列)拆分权重矩阵的并行策略 - 作用
- 显存优化:单个GPU仅需存储部分权重和激活值,显著降低显存占用。例如,拆分到4块GPU时,每卡显存需求降至1/4
- 计算加速:并行执行子矩阵乘法(GEMM),充分利用多GPU算力。例如,MLP层的两个GEMM操作可分别按列和行拆分并行。
- 扩展性:支持与数据并行、流水线并行结合,形成混合并行策略(如Megatron的3D并行),适应超大规模模型训练
- 定义:1D张量并行是一种按单一维度(行或列)拆分权重矩阵的并行策略
- 基本原理
- 矩阵拆分:在神经网络层内部,将权重矩阵
按行或列进行切分,分布到不同GPU上。(主要是Self-Attention层和MLP层) - 局部计算:每个GPU仅存储所分配的参数量,执行局部的矩阵乘法运算
- 通信同步:
- 列并行:通过
All-Gather将不同GPU的输出部分进行拼接(如 [ X W 1 , X W 2 ] [XW_1, XW_2] [XW1,XW2]) - 行并行:通过
All-Reduce对部分结果求和(如 X 1 W 1 + X 2 W 2 X_1W_1 + X_2W_2 X1W1+X2W2)
- 列并行:通过
- 矩阵拆分:在神经网络层内部,将权重矩阵
- 矩阵乘法基本原理
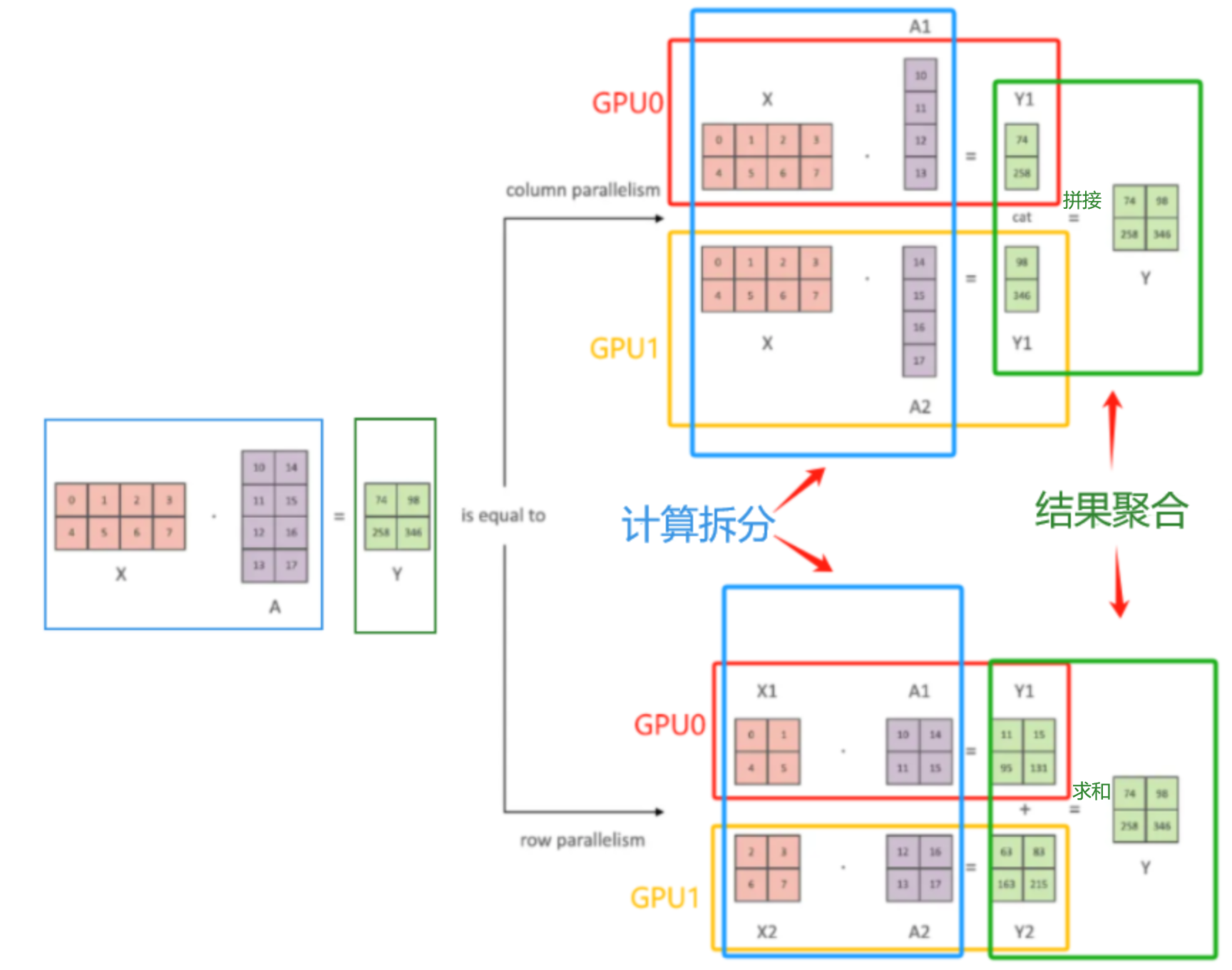
- 概述
- 模型矩阵乘法操作:
XA = Y,其中,X 是输入,A是权重,Y是输出 - 矩阵划分:矩阵X尺寸为
m
×
p
m \times p
m×p,矩阵A尺寸为
p
×
n
p \times n
p×n,则矩阵Y的尺寸为
m
×
n
m \times n
m×n(X的列数必须等于B的行数,即中间维度一致)
- 模型矩阵乘法操作:
- 划分方式
- 行并行(Row Parallelism):将权重A
按列拆分成 A 1 , A 2 , . . . , A i A_1,A_2,...,A_i A1,A2,...,Ai到 i i i个进程上,输入矩阵X按列拆分成对应的 X 1 , X 2 , X 3 , . . . , X i X_1,X_2,X_3,...,X_i X1,X2,X3,...,Xi,最后通过All-Gather进行拼接 - 列并行(Column Parallelism):将权重A
按行拆分A 1 , A 2 , . . . , A i A_1,A_2,...,A_i A1,A2,...,Ai到 i i i个进程上,输入矩阵X不拆分,通过All-Reduce对部分结果求和
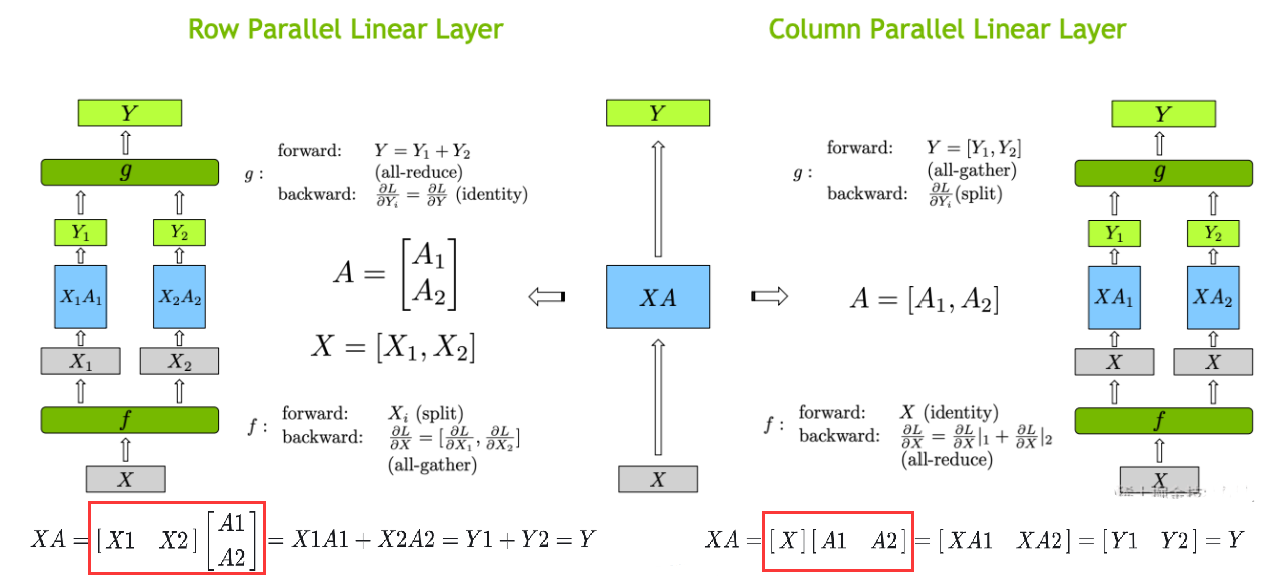
- 行并行(Row Parallelism):将权重A
- 概述
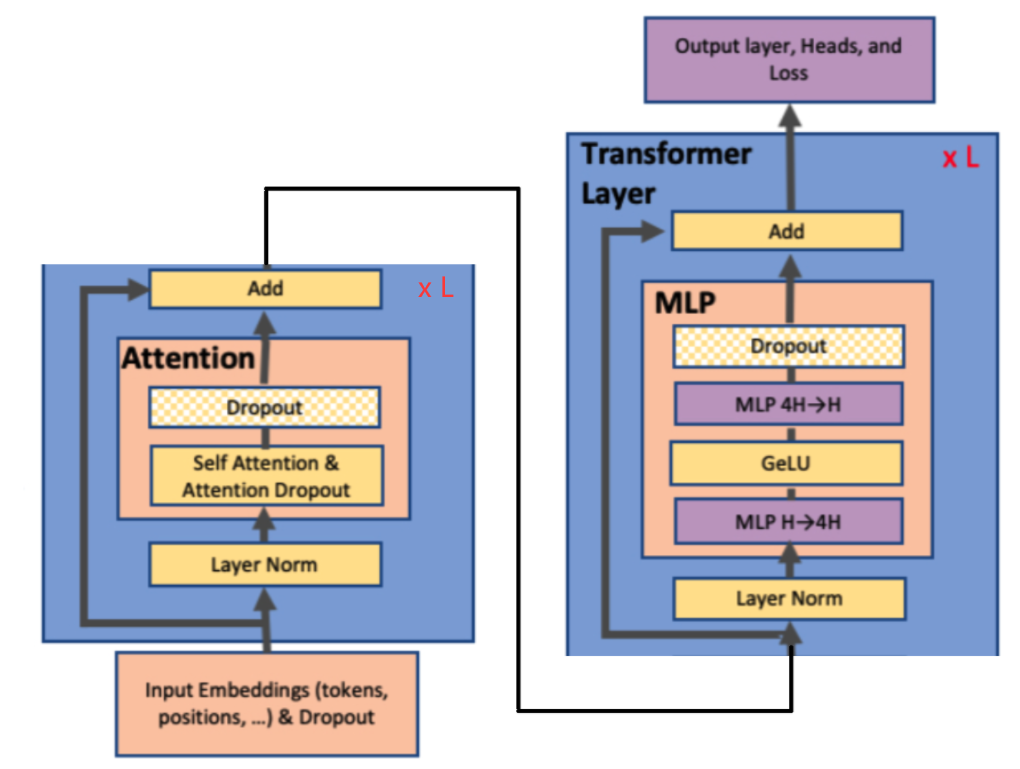
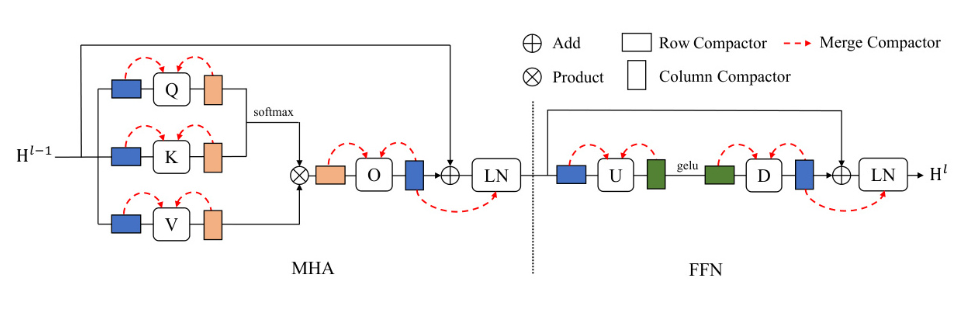
- Megatron的张量并行原理
- 核心原理:将Transformer模型中的主要计算组件进行矩阵切分,利用多GPU并行计算,最后通过同步通信操作整合结果
- Transformer的主要计算组件
- 自注意力层Self Attention:主要是MHA层的计算,
- 前馈神经网络FFN:主要是MLP层进行计算,由两个线性变换(GEMM)和非线性激活(如GeLU)组成
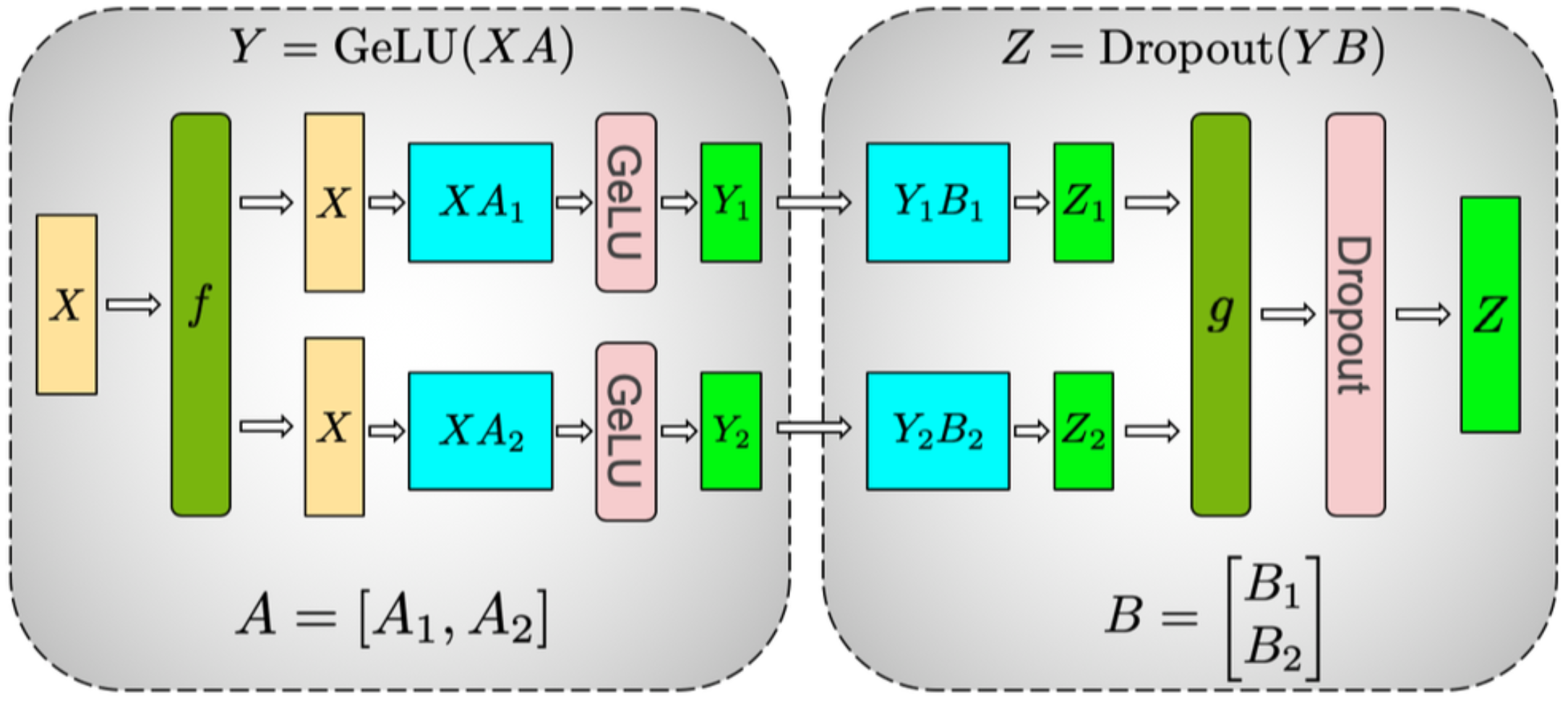
- MLP的并行计算流程
- 输入分发:输入矩阵
X通过 f算子(前向为复制操作)分发到所有GPU,每块GPU持有完整的X - 第一层列并行
- 执行:权重矩阵
A按列切分(Column Parallelism),即 A = [ A 1 , A 2 ] A = [A_1, A_2] A=[A1,A2],分配到不同GPU。输入 X X X 按行切分,每个GPU独立计算 Y i = GeLU ( X i A i ) Y_i = \text{GeLU}(X_i A_i) Yi=GeLU(XiAi) - 作用:将输入向量
x
x
x的维度
d
m
o
d
e
l
d_{model}
dmodel进行
升维(通常扩大4倍),以增强非线性拟合能力。
- 执行:权重矩阵
- 独立激活:在各GPU上独立应用非线性函数GeLU进行计算处理
- 第二层行并行
- 执行:权重矩阵
A按行切分(Row Parallelism),即 B = [ B 1 ; B 2 ] B = [B_1; B_2] B=[B1;B2],每个GPU独立计算 Z i = Y i B i Z_i = Y_i B_i Zi=YiBi - 作用:将特征
降维压缩回原始输入维度 d m o d e l d_{model} dmodel(通常缩小4倍),确保输出与输入维度一致,便于残差连接
- 执行:权重矩阵
- 输出聚合: All-Reduce聚合:通过 g算子(前向为All-Reduce)汇总结果
- Dropout:在聚合后的
Z上应用Dropout,得到最终输出。
FFN ( x ) = G e L U ( 0 , x W 1 + b 1 ) W 2 + b 2 ( W 1 ∈ R d model × d ff , W 2 ∈ R d ff × d model ) \text{FFN}(x) = GeLU(0, xW_1 + b_1)W_2 + b_2(W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}},W_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}}) FFN(x)=GeLU(0,xW1+b1)W2+b2(W1∈Rdmodel×dff,W2∈Rdff×dmodel)
- 输入分发:输入矩阵
- MLP的通信优化
- 核心: 通过
先列后行的拆分计算策略,使得非线性激活函数(如GeLU)的计算能够独立进行,从而减少通信同步次数 - 先列后行
- 第一线性层:按列分割避免激活前同步通信开销
- 在MLP层中,假设第一层权重矩阵 A ∈ R d × h A \in \mathbb{R}^{d \times h} A∈Rd×h 按列切割为 A 1 , A 2 , … , A p A_1, A_2, \ldots, A_p A1,A2,…,Ap,每个GPU处理 h / p h/p h/p 列。此时,输入 X ∈ R b × d X \in \mathbb{R}^{b \times d} X∈Rb×d 被广播到所有GPU,各GPU独立计算 Y i = X ⋅ A i Y_i = X \cdot A_i Yi=X⋅Ai
- 非线性激活函数(如GeLU)的逐元素特性使得每个GPU可独立计算 GeLU ( Y i ) \text{GeLU}(Y_i) GeLU(Yi),无需与其他GPU同步中间结果(即无需All-Gather操作)。这是因为 GeLU ( ∑ Y i ) ≠ ∑ GeLU ( Y i ) \text{GeLU}(\sum Y_i) \neq \sum \text{GeLU}(Y_i) GeLU(∑Yi)=∑GeLU(Yi),若激活前同步将破坏计算正确性
- 第二线性层:按行分割有助于all-reduce的拼接操作
- 按列切割的第二层权重矩阵 B ∈ R h × d B \in \mathbb{R}^{h \times d} B∈Rh×d按行切割为 B 1 , B 2 , … , B p B_1, B_2, \ldots, B_p B1,B2,…,Bp。各GPU计算 Z i = GeLU ( Y i ) ⋅ B i Z_i = \text{GeLU}(Y_i) \cdot B_i Zi=GeLU(Yi)⋅Bi,最终通过一次All-Reduce汇总所有 Z i Z_i Zi得到完整输出 Z Z Z
- 按行切割的第二层输出在All-Reduce时天然满足维度对齐,可直接拼接为完整矩阵
- 第一线性层:按列分割避免激活前同步通信开销
- 核心: 通过
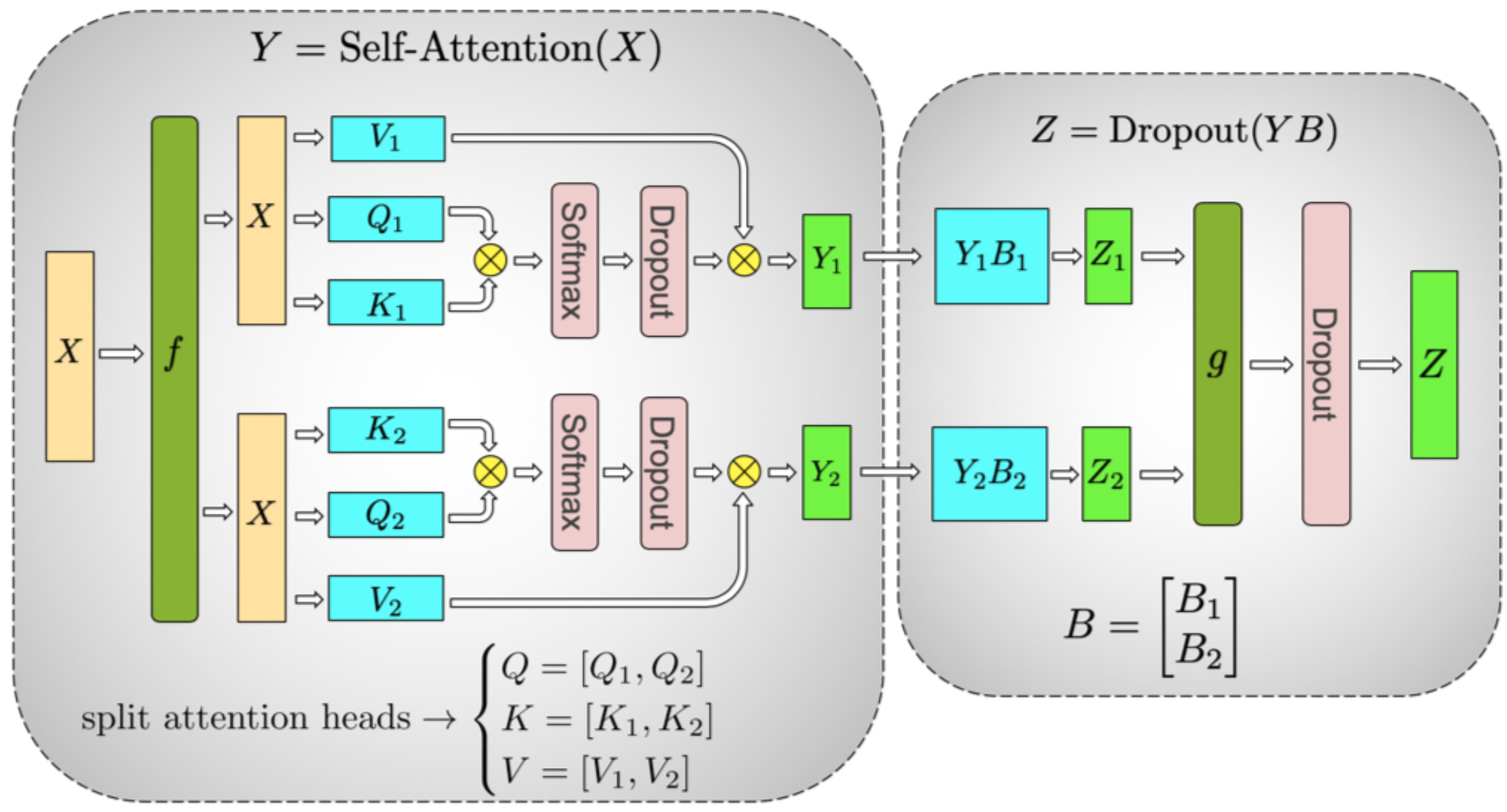
- MHA的并行计算流程
- 维度拆分:将输入特征维度 d d d 拆分为 H H H个注意力头的子维度 d k d_k dk,其中 H H H为注意力头数。每个头独立处理特征的不同子空间,增强模型表达能力 d k = d H d_k = \frac{d}{H} dk=Hd
- 输入广播:通过
f将完整的输入X通过广播Broadcast放置到每个GPU上,即每个GPU都存在完整的输入副本 - 权重分块:每个GPU存储N个注意力头的权重矩阵 { W Q ( h ) , W K ( h ) , W V ( h ) } \{ W_Q^{(h)},W_K^{(h)} ,W_V^{(h)}\} {WQ(h),WK(h),WV(h)}( h h h为该GPU分配的头索引)
- 线性投影:输入 X ∈ R N × d X \in \mathbb{R}^{N \times d} X∈RN×d广播到所有GPU,每个GPU计算其分配的注意力头的局部Q、K、V矩阵上 Q h = X W Q ( h ) , K h = X W K ( h ) , V h = X W V ( h ) Q_h = X W_Q^{(h)}, \quad K_h = X W_K^{(h)}, \quad V_h = X W_V^{(h)} Qh=XWQ(h),Kh=XWK(h),Vh=XWV(h)
- 注意力分数计算:计算每个头h的注意力分数矩阵,其中缩放因子 d k \sqrt{d_k} dk 用于防止点积结果过大导致Softmax梯度消失 Attention_Score h = Q h K h T d k \text{Attention\_Score}_h = \frac{Q_h K_h^T}{\sqrt{d_k}} Attention_Scoreh=dkQhKhT
- Dropout:以概率 p d r o p p_{drop} pdrop(例如0.1或0.2)随机将注意力分数矩阵中的部分元素置零,从而提升模型泛化能力,防止过拟合 A t t e n t i o n S c o r e d r o p h = D r o p o u t ( Attention_Score h ) Attention_Score_{drop}^{h} = Dropout \left( \text{Attention\_Score}_h \right) AttentionScoredroph=Dropout(Attention_Scoreh)
- Softmax归一化:对每个行的注意力分数应用Softmax,得到概率分布 A h A_h Ah A h = Softmax ( A t t e n t i o n S c o r e d r o p h ) A_h = \text{Softmax}(Attention_Score_{drop}^{h}) Ah=Softmax(AttentionScoredroph)
- 加权求和:将注意力权重 A h A_h Ah 与值矩阵 V h V_h Vh 相乘,生成 局部注意力头 h h h 的输出 Y h = A h V h \text{Y}_h = A_h V_h Yh=AhVh
- 线性计算:通过线性变换 Y h B h Y_h B_h YhBh,调整输出维度以便后续的融合处理 Z h = Y h B h \text{Z}_h =Y_h B_h Zh=YhBh
- 统合拼接:所有GPU完成局部计算后,通过 All-Gather 操作将各GPU的
H
p
\frac{H}{p}
pH个头的输出拼接为完整结果:
Output = Concat ( Output 1 , Output 2 , … , Output H ) ∈ R N × d \text{Output} = \text{Concat}(\text{Output}_1, \text{Output}_2, \dots, \text{Output}_H) \quad \in \mathbb{R}^{N \times d} Output=Concat(Output1,Output2,…,OutputH)∈RN×d
- MHA并行化中的注意点
- 注意力头数与GPU数的整除关系
- 整除性要求:总头数为 H H H,并行GPU数为 p p p 时,每个GPU会处理 N = H / p N = H/p N=H/p 个头
- 特殊场景:GPU数大于头数时,部分头需在多个GPU间复制(partially replicated),此时需权衡计算冗余与通信成本
- 示例:模型设计时需选择头数为GPU数的整数倍。例如,BERT的64头适配8个GPU并行,GLAM的128头适配16个GPU并行
- 通信开销与同步机制
- All-Reduce操作: 每个Transformer层的正向和反向传播中,MHA部分涉及4次All-Reduce通信(用于拼接多头输出和梯度同步),需优化通信带宽和延迟 3 12。
- 分片与拼接效率: 输出矩阵 W O W_O WO 按行切割(形状为 [ m o d e l _ s i z e / p , m o d e l _ s i z e ] [model\_size/p, model\_size] [model_size/p,model_size]),拼接时需跨GPU聚合结果,可能成为性能瓶颈 2 PDF。
- 注意力头数与GPU数的整除关系
- MHA的设计优势
- 降低通信开销:通过列-行交替切分策略(Q/K/V列并行,输出行并行),将通信操作压缩到两次All-Reduce,显著提升多GPU扩展性
- 负载均衡:每个GPU处理等量的注意力头,确保计算与显存占用的均衡分布。
- 兼容残差连接:输出维度与输入一致,从而支持残差连接与层归一化的无缝集成
- 超过200亿参数量的模型需要在多个multi-GPU服务器上分割
- 需要频繁的All-Reduce通信来同步不同GPU上的计算结果,跨节点通信带宽远低于NVLink,成为训练速度的瓶颈
- 将大矩阵乘法拆分为多个子矩阵计算,每个GPU仅处理子矩阵。但当模型并行度过高时,子矩阵的规模会变得太小。会导致GPU的计算单元(CUDA Core)无法满载运行,硬件利用率大幅降低
多维张量并行(Colossal-AI)
- 背景
- 问题:
- 显存冗余:由于输入X未被切分,每个GPU仍需存储完整的输入副本和中间激活,显存占用高;
- 通信开销大:并行度增加时,通信成本呈线性或指数增长
- 扩展性限制:单一并行维度无法适配超大规模模型
- 解决方式
- 多维张量并行:将模型层内的权重和激活张量沿多个维度切分到不同设备上,通过分块矩阵乘法和通信协调实现并行计算。Colossal-AI支持2D、2.5D、3D等多种策略,兼容数据并行和流水并行,形成高效的混合并行方案
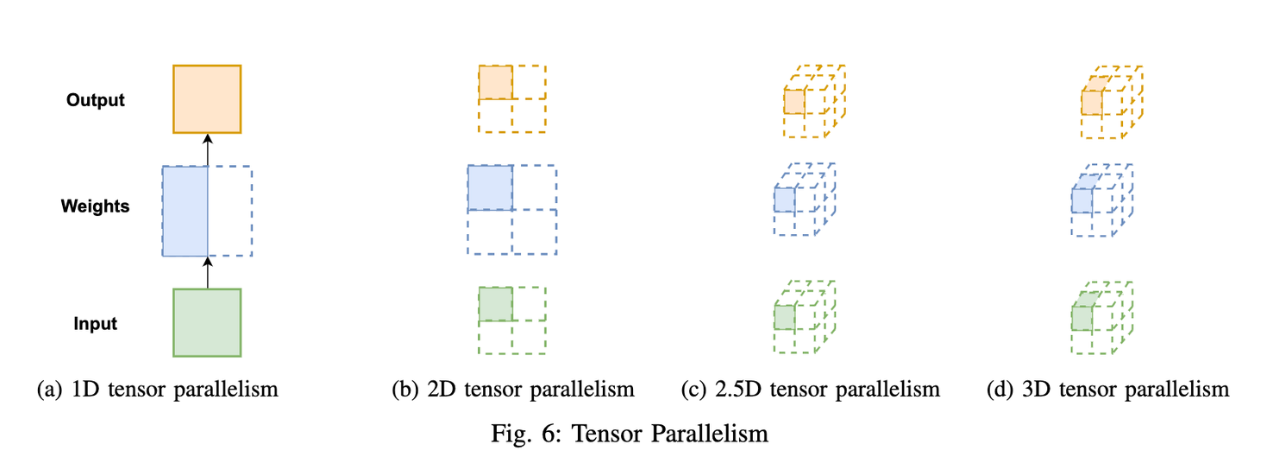
- 多维张量并行:将模型层内的权重和激活张量沿多个维度切分到不同设备上,通过分块矩阵乘法和通信协调实现并行计算。Colossal-AI支持2D、2.5D、3D等多种策略,兼容数据并行和流水并行,形成高效的混合并行方案
- 问题:
- 2D 张量并行
- 定义:2D张量并行将模型权重和输入张量沿两个维度(行和列)切分到二维设备网格(如q×q个GPU),利用分块矩阵乘法和分布式通信实现并行计算
- 核心目标:均衡计算负载,降低显存占用,并优化通信效率
- 基本原理:通过对
行列双维度切分输入和权重,同时降低参数和激活显存- 参数切分:权重矩阵沿行和列切分到二维设备网格,显存占用降至 O ( 1 / N 2 ) O(1/N^2) O(1/N2);
- 激活切分:输入数据沿两个维度切分,激活显存占用同步降至 O ( 1 / N 2 ) O(1/N^2) O(1/N2)
- 对比实验(在64个A100 GPU上训练ViT-Large模型,2D并行相比1D并行)
- 显存占用降低50%:激活显存从单卡完整存储变为分片存储
- 批处理量提升5.3倍:显存优化允许更大的批量
- 效率分析
| 指标 | 1D并行 | 2D并行 | 优势说明 |
|---|---|---|---|
| 计算成本 | O(1/q) | O(1/q²) | 计算量随设备数平方级降低 |
| 显存占用 | O(1/q)(参数+激活) | O(1/q²)(参数+激活) | 显存需求降为1D的1/q |
| 通信成本 | O(2(q-1)/q)(带宽) | O(6(q-1)/q)(带宽) | 单次通信量更低,总延迟更优 |
- 原理
- 基于SUMMA算法:采用分步矩阵乘法(如SUMMA算法),将全局矩阵乘法分解为多个局部计算阶段。每个阶段中,输入子矩阵在行或列方向广播,与权重子矩阵进行局部乘加操作,最后通过跨设备通信聚合结
- 设备网格划分:将 N N N 个设备组织成 q × q q \times q q×q 的二维网格(如4卡时为 2 × 2 2 \times 2 2×2 网格),每个设备坐标为 ( i , j ) (i, j) (i,j)
- 张量分块
- 输入矩阵 X X X 按行切分为 X 0 , X 1 , … , X q − 1 X_0, X_1, \ldots, X_{q-1} X0,X1,…,Xq−1,权重矩阵 A A A 按列切分为 A 0 , A 1 , … , A q − 1 A_0, A_1, \ldots, A_{q-1} A0,A1,…,Aq−1
- 每个设备 ( i , j ) (i, j) (i,j) 存储 X i X_i Xi 和 A j A_j Aj 的子块。
- 分阶段计算
- 阶段1(广播与局部计算): X i X_i Xi 在行方向广播至同一行所有设备, A j A_j Aj 在列方向广播至同一列所有设备。设备 ( i , j ) (i, j) (i,j) 计算局部乘积 X i ⋅ A j X_i \cdot A_j Xi⋅Aj。
- 阶段2(结果聚合):通过跨设备通信(如AllReduce)将各设备的部分和相加,得到最终输出
Y
=
∑
k
=
0
q
−
1
X
k
⋅
A
k
Y = \sum_{k=0}^{q-1} X_k \cdot A_k
Y=∑k=0q−1Xk⋅Ak。
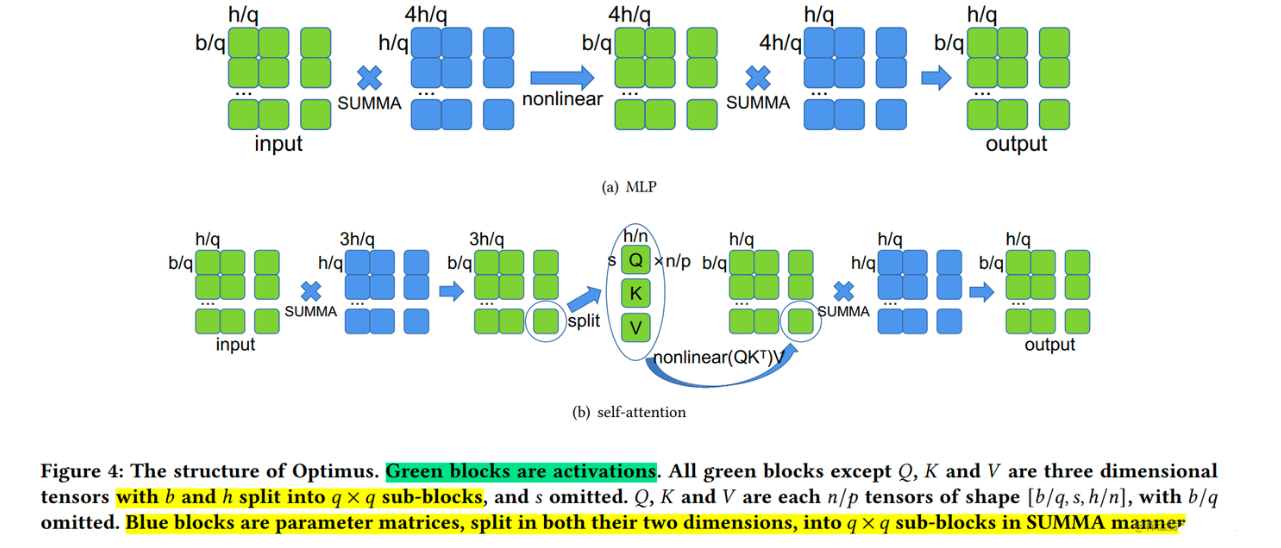
- 执行流程示例
- 以矩阵乘法
Y
=
X
A
Y = XA
Y=XA为例,给定的
q
×
q
q \times q
q×q 个处理器,假设
q
=
2
q = 2
q=2,则将X和A均划分
2
×
2
2 \times 2
2×2的块
Y = X A = [ X 00 X 01 X 10 X 11 ] [ A 00 A 01 A 10 A 11 ] = [ X 00 A 00 + X 01 A 10 X 00 A 01 + X 01 A 11 X 10 A 00 + X 11 A 10 X 10 A 01 + X 11 A 11 ] Y = XA = \begin{bmatrix}X_{00} & X_{01} \\X_{10} & X_{11}\end{bmatrix}\begin{bmatrix}A_{00} & A_{01} \\A_{10} & A_{11}\end{bmatrix}= \begin{bmatrix}X_{00}A_{00} + X_{01}A_{10} & X_{00}A_{01} + X_{01}A_{11} \\X_{10}A_{00} + X_{11}A_{10} & X_{10}A_{01} + X_{11}A_{11}\end{bmatrix} Y=XA=[X00X10X01X11][A00A10A01A11]=[X00A00+X01A10X10A00+X11A10X00A01+X01A11X10A01+X11A11] = [ X 00 A 00 X 00 A 01 X 10 A 00 X 10 A 01 ] + [ X 01 A 10 X 01 A 11 X 11 A 10 X 11 A 11 ] = \begin{bmatrix}X_{00}A_{00} & X_{00}A_{01} \\X_{10}A_{00} &X_{10}A_{01}\end{bmatrix}+\begin{bmatrix}X_{01}A_{10} & X_{01}A_{11} \\X_{11}A_{10} & X_{11}A_{11}\end{bmatrix} =[X00A00X10A00X00A01X10A01]+[X01A10X11A10X01A11X11A11] - 基于上面的矩阵乘法的变化,发现
Y
=
X
A
Y = XA
Y=XA 可以分解为两个矩阵相加,其中
- 两个矩阵的结果仍需串行的计算
- 单个矩阵中的4个子矩阵可以使用 2 × 2 2 \times 2 2×2 的处理器来并行计算
- 当 t = 1 t = 1 t=1,也就是第一步。对 [ X 00 X 10 ] 和 [ A 00 A 01 ] \begin{bmatrix}X_{00} \\X_{10}\end{bmatrix}\text{和}\begin{bmatrix}A_{00} & A_{01}\end{bmatrix} [X00X10]和[A00A01]进行广播,所有 2 × 2 2 \times 2 2×2 的处理器均拥有这4个子矩阵。然后分别执行 X 00 A 00 X_{00}A_{00} X00A00、 X 10 A 00 X_{10}A_{00} X10A00、 X 00 A 01 X_{00}A_{01} X00A01、 X 10 A 01 X_{10}A_{01} X10A01,从而得到第一个矩阵的结果
- 当 t = 2 t = 2 t=2。对 [ X 01 X 11 ] 和 [ A 10 A 11 ] \begin{bmatrix}X_{01} \\X_{11}\end{bmatrix}\text{和}\begin{bmatrix}A_{10} & A_{11}\end{bmatrix} [X01X11]和[A10A11]进行广播,各个处理器在分别计算,最终得到第二个矩阵的结果。
- 结果聚合:将两个矩阵的结果相加得到最终输出
- 以矩阵乘法
Y
=
X
A
Y = XA
Y=XA为例,给定的
q
×
q
q \times q
q×q 个处理器,假设
q
=
2
q = 2
q=2,则将X和A均划分
2
×
2
2 \times 2
2×2的块
- 2.5D张量并行原理
- 对于矩阵乘法 Y = X A Y = XA Y=XA,并假设有 p × p × d p \times p \times d p×p×d个处理器,将 X X X划分为 d × q d \times q d×q行和 q q q列
- 假设
p
=
d
=
2
p = d = 2
p=d=2,将
X
X
X和
A
A
A分别划分为
[ X 00 X 01 X 10 X 11 X 20 X 21 X 30 X 31 ] 和 [ A 00 A 01 A 10 A 11 ] \begin{bmatrix}X_{00} & X_{01} \\X_{10} & X_{11} \\X_{20} & X_{21} \\X_{30} & X_{31}\end{bmatrix}\text{ 和 }\begin{bmatrix}A_{00} & A_{01} \\A_{10} & A_{11}\end{bmatrix} X00X10X20X30X01X11X21X31 和 [A00A10A01A11]那么有
Y = X A = [ X 00 X 01 X 10 X 11 X 20 X 21 X 30 X 31 ] [ A 00 A 01 A 10 A 11 ] = [ X 00 A 00 + X 01 A 10 X 00 A 01 + X 01 A 11 X 10 A 00 + X 11 A 10 X 10 A 01 + X 11 A 11 X 20 A 00 + X 21 A 10 X 20 A 01 + X 21 A 11 X 30 A 00 + X 31 A 10 X 30 A 01 + X 31 A 11 ] = concat ( [ X 00 A 00 + X 01 A 10 X 00 A 01 + X 01 A 11 X 10 A 00 + X 11 A 10 X 10 A 01 + X 11 A 11 ] [ X 20 A 00 + X 21 A 10 X 20 A 01 + X 21 A 11 X 30 A 00 + X 31 A 10 X 30 A 01 + X 31 A 11 ] ) = concat ( [ X 00 X 01 X 10 X 11 ] [ A 00 A 01 A 10 A 11 ] [ X 20 X 21 X 30 X 31 ] [ A 00 A 01 A 10 A 11 ] ) \begin{align}Y = XA &= \begin{bmatrix}X_{00} & X_{01} \\X_{10} & X_{11} \\X_{20} & X_{21} \\X_{30} & X_{31}\end{bmatrix}\begin{bmatrix}A_{00} & A_{01} \\A_{10} & A_{11}\end{bmatrix} \\&= \begin{bmatrix}X_{00}A_{00} + X_{01}A_{10} & X_{00}A_{01} + X_{01}A_{11} \\X_{10}A_{00} + X_{11}A_{10} & X_{10}A_{01} + X_{11}A_{11} \\X_{20}A_{00} + X_{21}A_{10} & X_{20}A_{01} + X_{21}A_{11} \\X_{30}A_{00} + X_{31}A_{10} & X_{30}A_{01} + X_{31}A_{11}\end{bmatrix} \\&= \text{concat} \left(\frac{\begin{bmatrix}X_{00}A_{00} + X_{01}A_{10} & X_{00}A_{01} + X_{01}A_{11} \\X_{10}A_{00} + X_{11}A_{10} & X_{10}A_{01} + X_{11}A_{11}\end{bmatrix} }{\begin{bmatrix}X_{20}A_{00} + X_{21}A_{10} & X_{20}A_{01} + X_{21}A_{11} \\X_{30}A_{00} + X_{31}A_{10} & X_{30}A_{01} + X_{31}A_{11}\end{bmatrix}}\right) \\&= \text{concat} \left(\frac{\begin{bmatrix}X_{00} & X_{01} \\X_{10} & X_{11}\end{bmatrix}\begin{bmatrix}A_{00} & A_{01} \\A_{10} & A_{11}\end{bmatrix} }{\begin{bmatrix}X_{20} & X_{21} \\X_{30} & X_{31}\end{bmatrix}\begin{bmatrix}A_{00} & A_{01} \\A_{10} & A_{11}\end{bmatrix}}\right)\end{align} Y=XA= X00X10X20X30X01X11X21X31 [A00A10A01A11]= X00A00+X01A10X10A00+X11A10X20A00+X21A10X30A00+X31A10X00A01+X01A11X10A01+X11A11X20A01+X21A11X30A01+X31A11 =concat [X20A00+X21A10X30A00+X31A10X20A01+X21A11X30A01+X31A11][X00A00+X01A10X10A00+X11A10X00A01+X01A11X10A01+X11A11] =concat [X20X30X21X31][A00A10A01A11][X00X10X01X11][A00A10A01A11] 其中,concat表示两个矩阵的垂直拼接操作。 - 基于上面的推导,可以发现被拼接的两个矩阵天然可以并行计算。即 [ X 00 X 01 X 10 X 11 ] 和 [ X 20 X 21 X 30 X 31 ] \begin{bmatrix}X_{00} & X_{01} \\X_{10} & X_{11}\end{bmatrix}\text{ 和 }\begin{bmatrix}X_{20} & X_{21} \\X_{30} & X_{31}\end{bmatrix} [X00X10X01X11] 和 [X20X30X21X31]可以并行计算,即这两个矩阵乘法就是上面的2D张量并行适用的形式
- 2.5D 张量并行与 2D 张量并行的区别
- 处理器数量:2.5D 张量并行使用 p × p × d p \times p \times d p×p×d 个处理器,而 2D 张量并行通常使用 p × p p \times p p×p 个处理器。
- 计算粒度:2.5D 张量并行将矩阵进一步划分为更小的子矩阵,可以在更多的处理器上并行计算,从而提高计算效率。
流水线并行
混合并行
- 概述
- 定义:Megatron-LM中的PTD-P(Pipeline, Tensor, Data Parallelism)是一种结合流水线并行、张量并行和数据并行的混合并行策略,旨在高效训练万亿参数级别的大型语言模型
- PTD-P通过以下三种并行模式的组合实现
- 流水线并行(Pipeline Parallelism) :跨多GPU服务器划分模型层,每个设备负责不同阶段的模型计算(如将Transformer层分配到不同节点)
- 张量并行(Tensor Parallelism) :在单个多GPU服务器内部,将矩阵运算(如Transformer的MLP和自注意力层的矩阵乘法)按列或行拆分到不同GPU上并行计算。
- 数据并行(Data Parallelism) :在不同设备组之间复制完整的模型副本,每个组处理不同的数据子集
- 作用
- 解决大模型单设备
显存限制:通过分层并行策略,允许万亿参数模型分布在数千个GPU上训练 - 提升
计算效率:在1000个GPU规模下实现高达52%的设备峰值吞吐量,显著降低训练时间。 - 优化
通信开销:张量并行仅需节点内高带宽通信,而流水线与数据并行跨节点通信,通过分层设计减少全局通信压力。 - 减少计算
气泡(Bubble Overhead) :采用交错式流水线调度,允许设备同时处理多个微批次(microbatches),降低空闲等待时间
- 解决大模型单设备
- 局限性:需要高性能GPU集群和高带宽网络(如InfiniBand),基础设施成本较高;非连续层分配可能增加通信复杂度
- 原理
- 分层通信优化:
- 节点内:张量并行利用同一服务器内GPU间高带宽(如NVLink),快速完成矩阵分块计算与同步。
- 节点间:流水线并行通过高带宽网络(如InfiniBand)传输中间激活和梯度,数据并行则同步不同设备组的参数。
- 非连续层分配:将多个非连续的模型子层(如层1、2、9、10)分配给同一设备,减少流水线并行的气泡时间,但需权衡通信开销。
- 动态负载均衡:通过调整流水线阶段数、微批次大小等参数,平衡计算与通信负载,最大化GPU利用率
- 分层通信优化:
- 计算绑定与内存绑定的本质区别
- 内存绑定:计算速度受限于内存带宽(如频繁读写中间结果),此时GPU显存带宽成为瓶颈。例如,传统框架中逐元素操作(如GeLU激活)需多次读写中间张量,导致内存访问开销过大。
- 计算绑定:计算速度受限于GPU的浮点运算能力(FLOPS),此时计算单元的利用率达到峰值。例如,通过融合多个操作(如bias + GeLU + dropout),减少中间结果存储,使计算密集度超过内存带宽限制。
- 内核融合(Kernel Fusion)
- 原理:将多个连续的计算操作(如矩阵乘法、激活函数、归一化等)合并为一个 单一的内核函数(kernel) ,减少以下开销:
- 内存访问开销:避免多次读写中间结果到全局内存(Global Memory)。
- 内核启动开销:减少从主机(CPU)到设备(GPU)的多次内核调度(kernel launch)。
- 显存占用:降低对显存带宽的依赖,提升计算密度(Compute Intensity)。
- 适用场景
- 连续性:操作在计算图中连续执行,无分支或数据依赖冲突。
- 数据局部性:中间结果无需保留(如仅用于后续一步计算)
- 作用
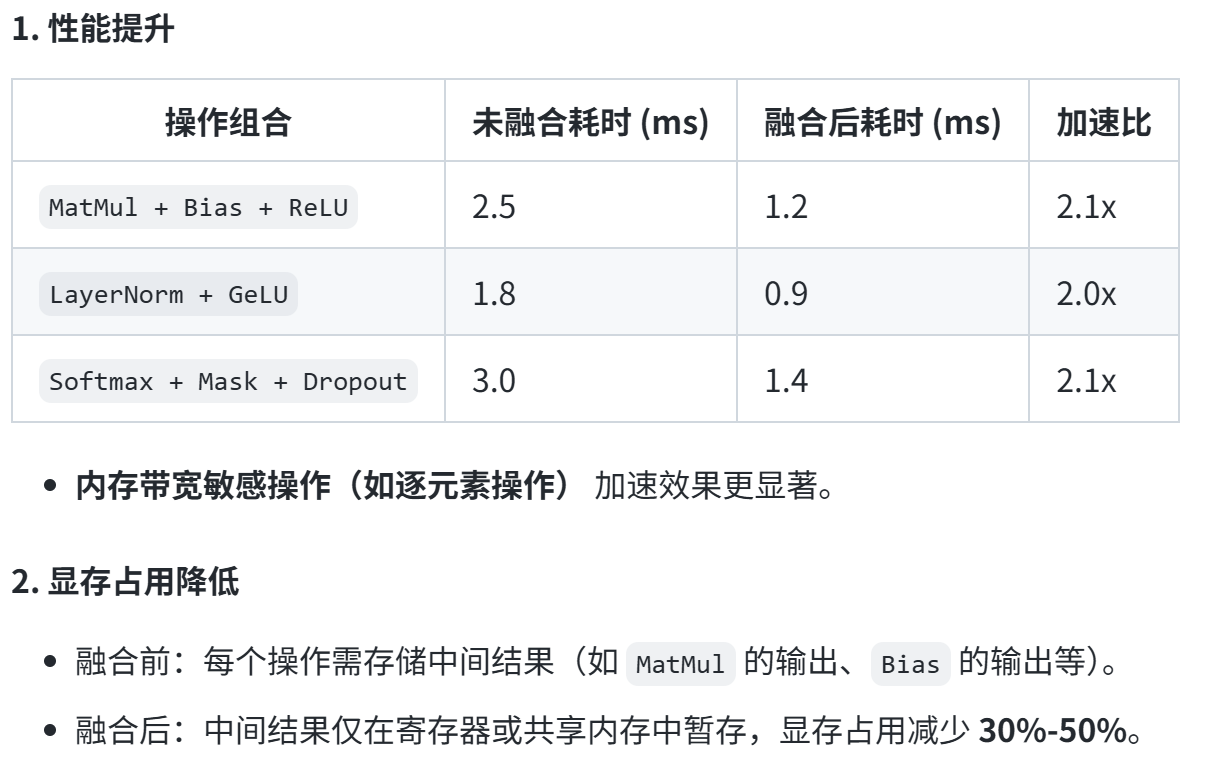
- 原理:将多个连续的计算操作(如矩阵乘法、激活函数、归一化等)合并为一个 单一的内核函数(kernel) ,减少以下开销:
- Megatron-LM实现内核融合方式
- 逐元素操作融合:将多个连续操作合并为单一内核。例如,将Transformer层的bias + GeLU和bias + dropout + add操作融合,减少内存访问次数
- 自定义Softmax内核:针对注意力机制中的缩放-掩码-softmax操作,设计融合内核。例如,支持因果掩码的自定义内核避免了中间张量的转置和存储,减少显存占用并提升10%-15%的计算效率
- GEMM(矩阵乘法)优化:重构数据布局(如将[batch, seq, head, hidden]调整为[seq, batch, head, hidden]),避免频繁转置操作,并启用跨步批处理GEMM内核,使矩阵乘法效率提升20%以上
显存优化
激活重计算
- 概述
- 定义:激活重计算(Activation Recomputation),也称梯度检查点/Gradient Checkpointing是一种
以计算量换取显存优化的技术,核心在于动态管理激活值的生命周期,通过“丢弃-重计算”机制对显存占用进行优化 - 原理:
- 前向丢弃:在前向传播过程中根据策略丢弃中间激活值(如Softmax输出、Dropout掩码等)
- 反向重计算:反向传播需要时重新计算丢弃的中间激活值,而非全部存储在显存中
- 算子级选择策略
- 保留计算量大或显存占用低的中间结果(如矩阵乘法输出)
- 重计算计算量小或高显存占用的算子(如Softmax、Dropout掩码)
- 定义:激活重计算(Activation Recomputation),也称梯度检查点/Gradient Checkpointing是一种
- 类型
- 完全重计算(Full Recomputation)
- 实现方式:在Megatron 2.0中首次引入,对
所有中间激活值进行重计算,即在前向传播时仅保留输入激活,反向传播时重新计算所有中间激活 - 特点:显存占用最低,但计算开销最大,相比不重计算方案额外增加约100%的计算量
- 实现方式:在Megatron 2.0中首次引入,对
- 选择性重计算(Selective Recomputation)
- 核心思想:仅对
显存占用高且计算量低的中间激活值进行重计算,在显存与计算效率间取得平衡 - 特点:针对特定算子(如Attention中的Softmax、Dropout等)进行重计算。这些算子显存占用大但计算量小,重计算后显存可减少至原占用的1/5,计算开销仅增加约2%-5%
- 核心思想:仅对
- 完全重计算(Full Recomputation)
- 流水线Block模式
- 原理:属于完全重计算的一种,将前N个Transformer层划分为“块”,对这些层的所有激活值进行重计算,剩余层则正常保存激活
- 特点:专为流水线并行设计,尤其适合显存极端受限的场景
- 序列并行+重计算
- 背景:传统解决方案采用 完全激活重计算(Full Activation Recomputation) ,即在反向传播时重新计算所有激活值,但会导致额外30%-40%的计算开销,显著降低训练效率
- 执行流程
- 前向传播阶段:
- 序列切分:输入序列被分割为多个子序列,分配到不同设备。
- 部分激活保存:仅保留高计算成本的激活(如注意力头输出),其余激活(如softmax中间结果)被丢弃
- 跨设备通信:通过all-reduce或all-gather操作同步各设备的中间结果
- 反向传播阶段:
- 选择性重计算:按需重新计算丢弃的激活值(如QK^T矩阵),同时复用保存的激活值
- 梯度聚合:各设备计算局部梯度后,通过通信操作(如reduce-scatter)聚合全局梯度
- 前向传播阶段:
- 技术演进对比
| 策略类型 | 执行流程差异 | 显存节省 | 计算开销 | 适用场景 |
|---|---|---|---|---|
| 完全重计算 | 仅保存层输入,反向时全层重算 | 最高 (80%) | 最高 (+100%) | 显存极度受限(如万亿模型) |
| 选择性重计算 | 按算子或层分组重算(如Softmax) | 中高 (60%) | 低 (+2%-5%) | 大规模模型(如GPT-3) |
| 流水线Block模式 | 仅重算流水线阶段的前N层,后M层保留 | 中 (40%) | 中 (+10%) | 流水线并行长阶段场景 |
| 序列并行+重计算 | 拆分序列至多GPU,结合选择性重算 | 极高 (90%) | 极低 (+1%) | 长序列训练(如s=32k) |
- 其他激活值存储优化
- 分布式存储:在张量并行(TP)场景下,将保存的激活值拆分至多GPU存储
- CPU卸载:将部分激活值移至CPU内存,进一步释放GPU显存,但是需权衡通信延迟
- 即时释放:对于无需保留的中间结果(如Dropout后的输出),在计算完成后立即释放显存
分布式梯度优化器
- 背景
- 单机显存瓶颈及问题:随着深度学习模型参数量的激增(如万亿参数的GPT-4),单设备显存无法容纳模型参数及中间激活值,并且传统单机优化器(如SGD、Adam)无法直接处理跨设备或跨节点的梯度同步问题,导致训练效率低下。
- 大规模训练:大规模数据集(如ImageNet、万亿token文本)需在多设备上并行处理。传统数据并行(Data Parallelism)仅通过AllReduce同步梯度,但无法高效处理异构硬件或超大规模模型
- 分布式训练:在分布式训练中,计算和通信的梯度同步开销可能成为瓶颈
- 概述
- 定义:分布式梯度优化器是一类在多设备节点环境中协调梯度计算与参数更新的算法组件
- 核心特征
- 并行化架构:支持数据并行、模型并行(如张量切分)、流水线并行等混合并行模式
- 梯度聚合机制:通过AllReduce、参数服务器或点对点通信同步梯度,确保全局一致性
- 优化器状态管理:对优化器状态(如动量、二阶矩)进行分片或复制,减少单节点内存压力
- 框架适配性:作为原生优化器的封装层(Wrapper),兼容主流框架(如TensorFlow、PyTorch)的API
- 作用
- 显存优化
- 参数分片:将模型参数与优化器状态分散到多设备,降低单节点显存占用(如ZeRO-3将显存需求降至1/设备数)
- 梯度聚合策略:通过梯度切分与分阶段通信(如Ring-AllReduce),减少峰值显存需求
- 计算效率提升
- 通信-计算重叠:在反向传播中提前启动梯度通信(如PyTorch的DistributedDataParallel),隐藏通信延迟
- 本地梯度累积:多步本地更新后再同步全局梯度,减少通信频率
- 扩展性与容错性
- 弹性训练:支持动态节点加入/退出(如PyTorch的ElasticAverageOptimizer)。
- 异构硬件适配:通过梯度量化(8-bit/4-bit)兼容不同带宽设备
- 显存优化
- 具体原理
- 数据并行下的梯度同步
- AllReduce机制:
- Ring-AllReduce:设备环形连接,分两阶段(Scatter-Reduce与AllGather)完成梯度聚合,带宽利用率最优
- 参数服务器:中心节点汇总梯度并广播更新,适合稀疏模型但存在单点瓶颈
- 梯度压缩:
- 量化(Quantization) :将32位浮点梯度压缩为8位整数,减少通信量(如Google的QSGD)
- 稀疏化(Sparsification) :仅传输绝对值较大的梯度(如Top-k选择)
- AllReduce机制:
- 模型并行下的优化器适配
- 参数分片(Sharding):
- 水平分片:按层划分参数,每设备存储部分层的状态(如Megatron-LM)。
- 垂直分片:将张量切分到多设备,需同步局部梯度(如Tensor Parallelism)
- 流水线并行优化:
- 将模型按层分段,每设备处理不同阶段的微批次(Micro-batch),优化器需管理阶段间梯度依赖
- 混合并行与动态策略
- 自适应通信频率:根据网络条件动态调整同步间隔(如Local SGD的K步更新)
- 混合精度训练:使用FP16/FP8存储梯度,结合Loss Scaling防止下溢出,需在分布式优化器中维护精度转换逻辑
- 参数分片(Sharding):
- 数据并行下的梯度同步




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











