







系列综述:
💞目的:本系列是个人整理为了学习训练框架优化的,整理期间苛求每个知识点,平衡理解简易度与深入程度。
🥰来源:材料主要源于【DualPipe官方介绍】进行的,每个知识点的修正和深入主要参考各平台大佬的文章,其中也可能含有少量的个人实验自证。
🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷!!!
请先收藏!!!,后续继续完善和扩充👍(●’◡’●)
分布式训练
概述
随着语言
模型参数量和训练数据量的急速增长,单个计算设备的资源已经不足以支撑大模型训练,所以需要通过分布式训练(Distributed Training)系统来解决海量的计算和内存资源要求。在分布式训练系统环境下需要将一个模型训练任务拆分成多个子任务,并将子任务分发给多个计算设备,从而解决资源瓶颈。但是如何才能利用包括数万计算加速芯片的集群,训练模型参数量千亿甚至是万亿的大规模语言模型?这其中涉及到集群架构、并行策略、模型架构、内存优化、计算优化等一系列的技术。
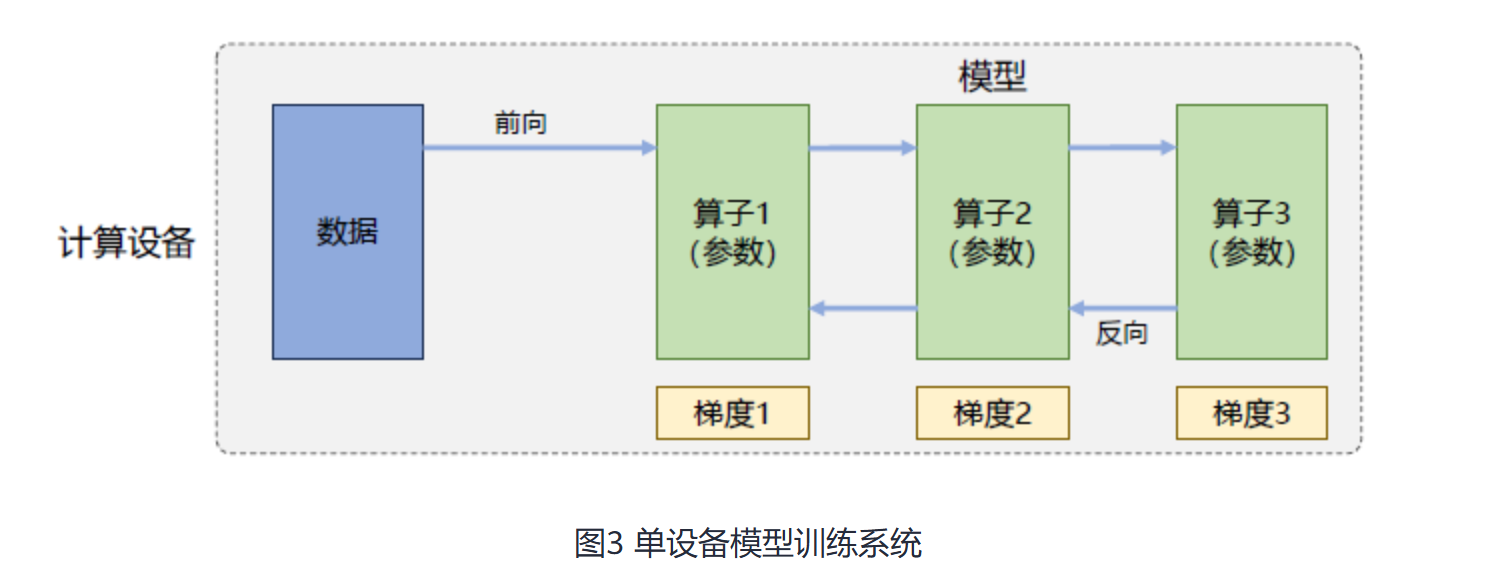
- 单设备模型训练
- 数据处理
- 数据小批次(Mini-batch):训练系统会利用每个数据小批次根据损失函数和优化算法生成梯度,从而对模型参数进行修正
- 算子(Operator):每个算子实现一个神经网络层(Neural Network Layer),而参数则代表了这个层在训练中所更新的权重
- 模型处理
- 前向计算:将数据读入第一个算子,计算出相应的输出结构,然后依此重复这个前向计算过程,直到最后一个算子结束
- 反向计算:根据优化函数和损失,每个算子依次计算出梯度,并利用梯度更新本地的参数
- 后续操作:在反向计算的这次数据小批次计算完成后,系统就会读取下一个数据小批次,继续下一轮的模型参数更新
- 数据处理
- 单设备训练的挑战
- 问题(由于单设备计算和存储能力有限,所以会产生计算墙和显存墙)
- 计算墙:单个计算设备所能提供的计算能力与大语言模型所需的总计算量之间存在巨大差异。例如2022 年3 年发布的NVIDIA H100 SXM 的单卡FP16 算力也只有2000 TFLOPs,而GPT-3则需要314 ZFLOPs 的总算力,两者相差了8 个数量级。
- 显存墙:单个计算设备无法完整存储一个大语言模型的参数。例如GPT-3若参数均采用FP16 格式存储,需要约700GB 的内存,而NVIDIA H100 GPU 只有80 GB 显存。
- 解决方式:采用
分布式训练解决单设备训练的资源不足的问题,但是存在通信墙问题- 通信墙:由于通信的延迟和带宽限制,可能成为训练过程的瓶颈。例如GPT-3在分布式训练中存在128个模型副本,则在每次迭代过程中至少需要传输89.6TB 的梯度数据
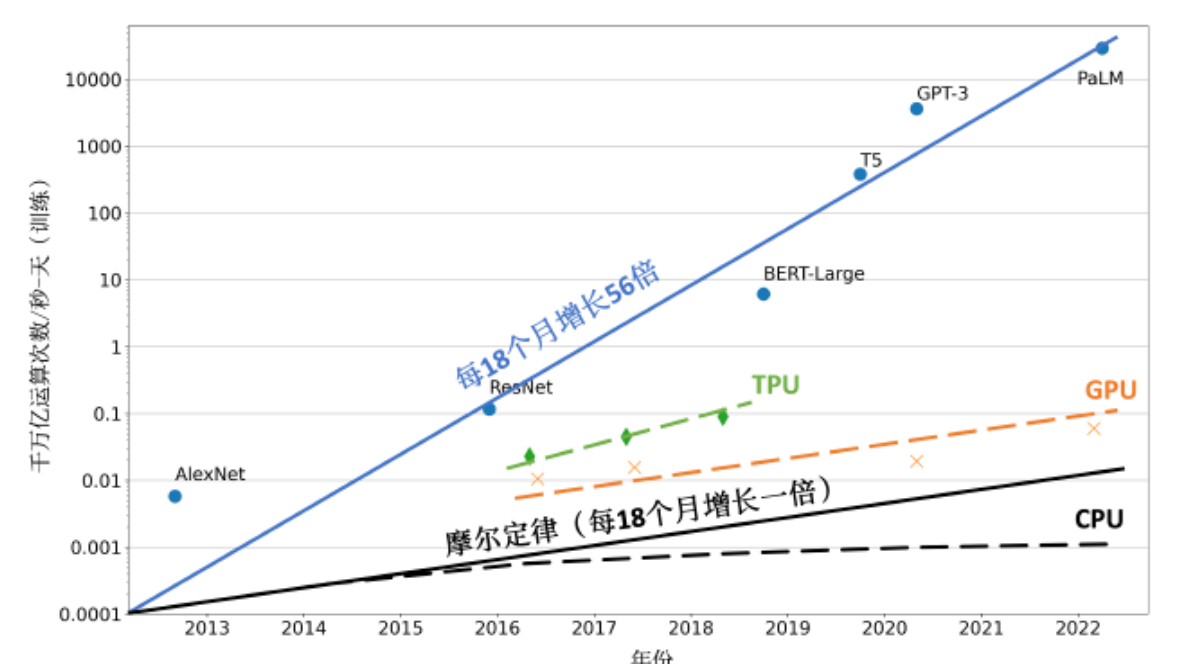
- 通信墙:由于通信的延迟和带宽限制,可能成为训练过程的瓶颈。例如GPT-3在分布式训练中存在128个模型副本,则在每次迭代过程中至少需要传输89.6TB 的梯度数据
- 问题(由于单设备计算和存储能力有限,所以会产生计算墙和显存墙)
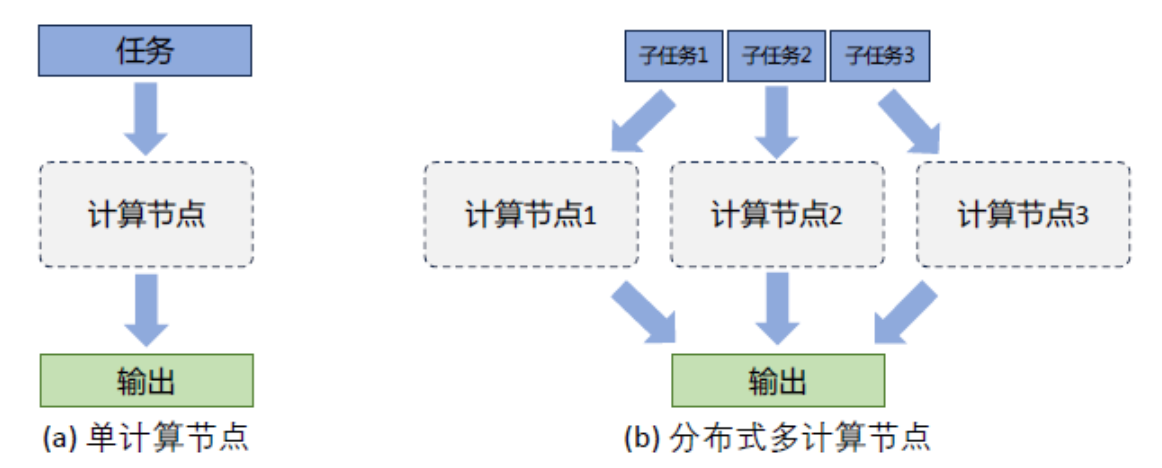
- 分布式训练(Distributed Training)
- 定义:将机器学习或深度学习模型训练任务分解成多个子任务,并在多个计算设备上并行地进行训练
- 目标:确保集群内的所有资源得到充分利用,从而减少训练所需总体时间
- 基本原理
- 拆分:将一个模型训练任务拆分成多个子任务
- 分发:根据策略将任务分发到不同的设备
- 并行计算:每个计算设备只需要负责子任务,并且多个计算设备可以并行执行
- 合并:接收其他设备的计算结果聚合生成与单设备计算等价的结果
- 分布式训练的总训练速度
- 单设备计算速度:主要由单块计算加速芯片的
运算速度和数据I/O 能力来决定,对单设备训练效率优化的主要手段有混合精度训练、算子融合、梯度累加等 - 计算设备总量:分布式训练系统中计算设备数量越多,其理论峰值计算速度就会越高,但是受到
通讯效率的影响,计算设备数量增大则会造成加速比急速降低 - 多设备加速比:主要由计算和通讯效率决定,需要结合算法和网络拓扑结构进行优化,
分布式训练并行策略主要目标就是提升分布式训练系统中的多设备加速比
总训练速度 ∝ 单设备计算速度 × 计算设备总量 × 多设备加速比 总训练速度∝ 单设备计算速度× 计算设备总量× 多设备加速比 总训练速度∝单设备计算速度×计算设备总量×多设备加速比
- 单设备计算速度:主要由单块计算加速芯片的
- 并行处理策略(提高多设备加速比)
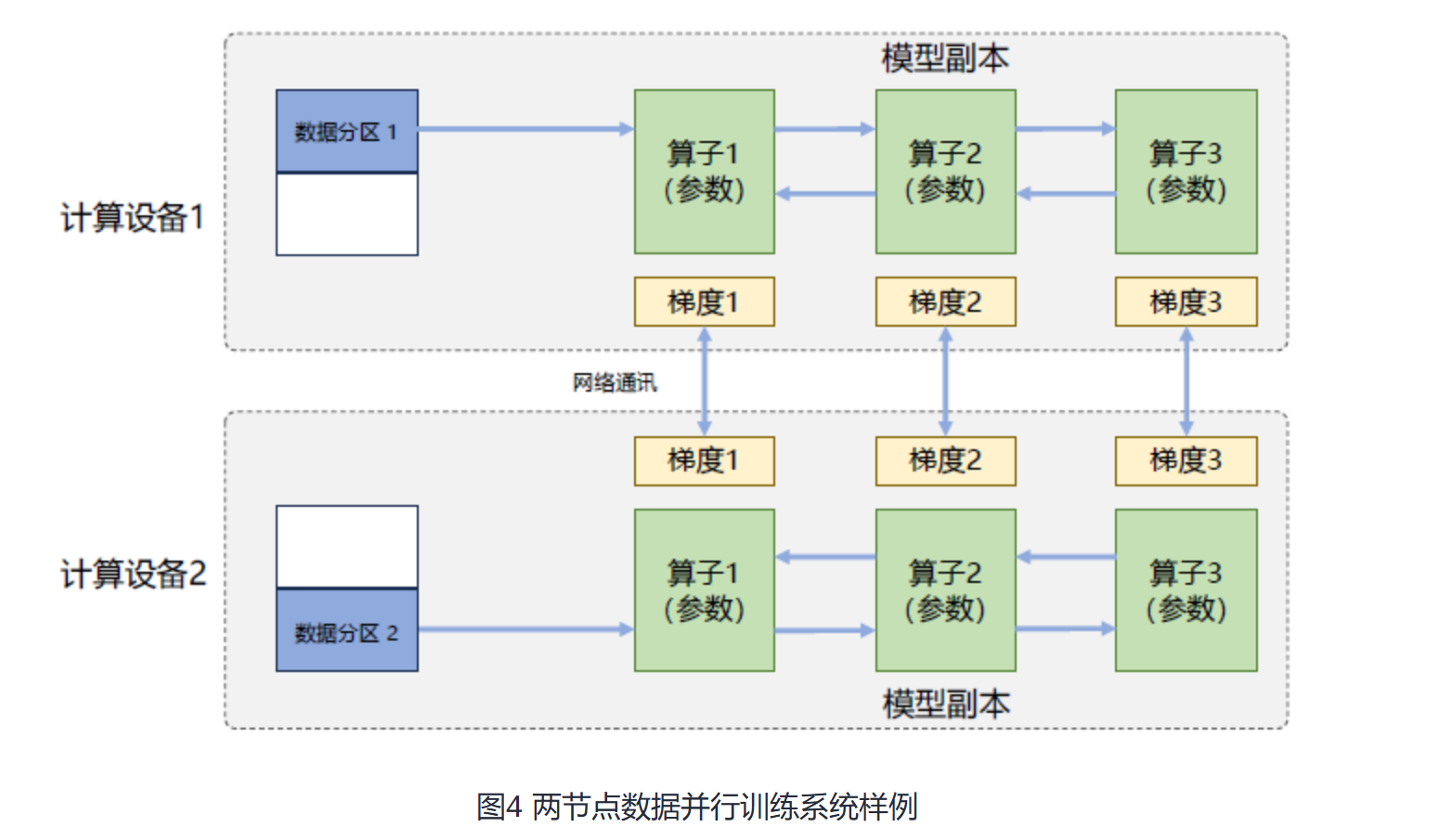
- 数据并行(Data Parallelism,DP):数据进行切分(Partition)多个微批次,分发到多个设备上相同的模型副本进行训练
- 模型并行(Model Parallelism,MP):对模型进行划分,将模型中的算子分发到多个设备分别完成
- 混合并行(Hybrid Parallelism,HP):当训练超大规模语言模型时,往往需要同时对数据和模型进行切分,从而实现更高程度的并行
- 数据并行概述
- 基本原理
- 数据均分:将训练数据按
批次(batch)进行均匀切分为多个数据子批次,并分发给不同的计算节点 - 模型复制:每个计算节点持有
相同的模型副本和初始状态,独立进行前向传播和反向传播。 - 梯度同步:通过集合通信(如AllReduce)或参数服务器(Parameter Server)架构,
聚合所有节点的梯度,计算全局平均梯度 - 参数更新:使用全局梯度更新
所有节点的模型参数,确保各副本的模型状态一致
- 数据均分:将训练数据按
- 核心问题:每个 GPU 持有整个模型权重的副本冗余
- 和单计算设备训练相比的主要区别:反向计算中的梯度需要在所有计算设备中进行同步,以保证每个计算设备上最终得到的是所有进程上梯度的平均值。
- 基本原理
- 模型并行概述
- 目标:通过分布式计算解决
单设备内存资源不足的问题,并提升大规模模型的训练效率 - 拆分策略
- 流水线并行 :在模型的
垂直方向上,数据基于模型分层,在层间进行并行处理(组装 → 喷漆 → 包装”三个工序,分别由三个工人按序完成) - 张量并行 :在模型的
水平方向上,对单层内的参数进行划分,每个设备上并行计算部分参数(切一个大萝卜,厨师1负责切前半段,厨师2负责切后半段,最后把两半的萝卜片合并成一盘菜)
- 流水线并行 :在模型的
- 目标:通过分布式计算解决
流水线并行
- 流水线并行(Pipeline Parallelism,PP)
- 定义:是一种并行计算策略,将模型的各个层划分为多个阶段(Stage),每个阶段分配到不同的计算设备上处理,不同设备依次处理数据的不同阶段,从而实现数据的处理。
- 两种策略
- F-then-B策略:每个批次的数据先整体完成前向计算,再进行对应的后向计算。但由于缓存了多个 micro-batch 的中间变量和梯度,显存占用较高
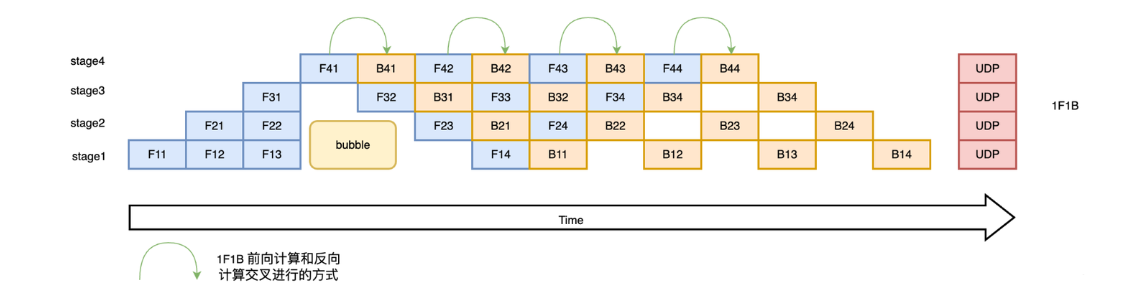
- 1F1B策略:前向计算和反向计算交替进行,从而及时释放不必要的中间变量
- 四种流水线
- 朴素流水线:将模型按层顺序切割为多个阶段(Stage),每个阶段分配到不同设备上执行。
- GPipe微批次流水线:将输入的小批次(Mini-batch)切分为多个微批次(Micro-batch),填充到流水线中以减少Bubble时间
- PipeDream流水线:交替执行前向和反向传播,降低中间缓存导致的显存占用问题
- Dualpipe流水线:从流水线两端同时输入Micro-batch(正向与逆向),并将Micro-batch进一步拆分和优化计算和通信进行精细调度,优化GPU利用率
- 朴素流水线
- 原理:将模型按层顺序切割为多个阶段(Stage),每个阶段分配到不同设备上执行。每个设备处理完当前阶段后,将中间结果传递给下一阶段的设备严格串行计算。
- 作用:将单个计算设备进行显存扩容为
N倍(N为计算设备数量) - 缺点:
- 高Bubble率:计算与通信无法重叠,设备空闲时间占比极高(同一时间只有一个设备在运行)
- 显存占用高:每个阶段需要缓存所有中间激活值(用于反向传播),显存需求随流水线阶段数增加而线性增长。
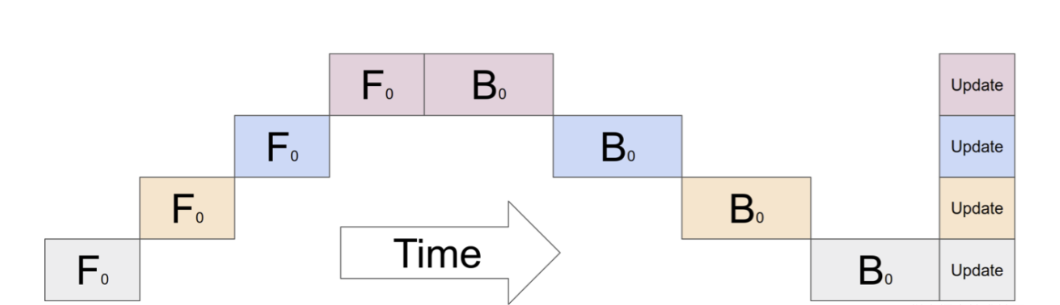
- GPipe微批次流水线(由谷歌提出的一种流水线并行方案)
- 原理
微批次切分:将每个输入的小批次(Mini-batch)进一步切分为多个微批次(Micro-batch)连续处理:每个设备完成当前微批次阶段的计算后,会将结果发送给下一阶段的计算设备,同时开始处理后一个微批次数据(此时,微批次数据第n阶段与下一个微批次数据n-1阶段的计算同时进行)
- 作用:
- 提高并行度:Gpipe 在朴素流水线并行的基础上,利用数据并行的思想,将 mini-batch 细分为多个更小的 micro-batch,送入GPU进行训练,来提高并行程度
- 降低单设备显存峰值:通过 重计算(现用现计算) 在前向时丢弃中间激活值,反向时重新计算以降低显存峰值
- 问题
- 显存爆炸:由于F-then-B 模式需要等待所有微批次完成前向传播后才能启动反向传播,所以每个 micro-batch 前向计算的中间激活值需要等到对应的反向计算完成后才能释放中间缓存,从而导致大量的显存浪费
- 基本并行举例
- 假设模型被划分为两个阶段(Stage 1 和 Stage 2),分配到设备1和设备2上:
- 第1个微批次(Micro-Batch 1):
- 设备1处理 Micro-Batch 1 的 Stage 1 → 完成后将结果发送给设备2。
- 设备2接收数据后,处理 Micro-Batch 1 的 Stage 2。
- 第2个微批次(Micro-Batch 2):
- 设备1在完成 Micro-Batch 1 的 Stage 1 后,立即开始处理 Micro-Batch 2 的 Stage 1
- 此时设备2仍在处理 Micro-Batch 1 的 Stage 2,而设备1已经开始处理新任务。
通过这种方式,设备1和设备2在时间上并行工作,形成流水线式的计算流
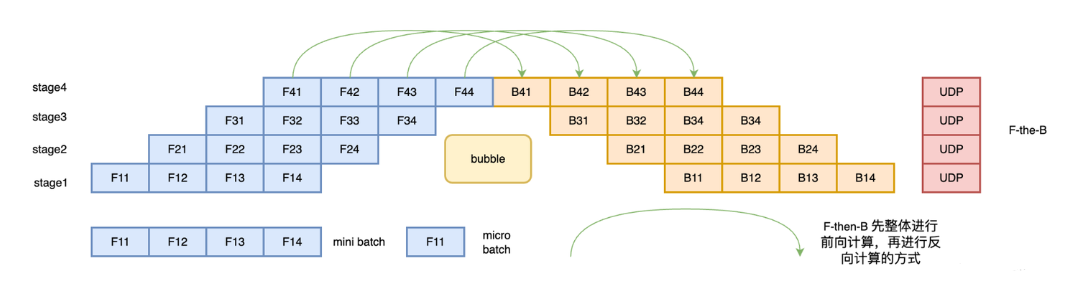
- 原理
- PipeDream(交替执行流水线)
- 原理
异步1F1B:交替执行前向和反向传播,即每个设备处理完一个前向任务后立即处理对应的反向任务(1F1B调度)从而通过即时释放中间结果显存,减少缓存占用权重版本管理:保存多个权重版本,确保前向与反向使用同一参数版本,避免梯度过期问题
- 调度类型
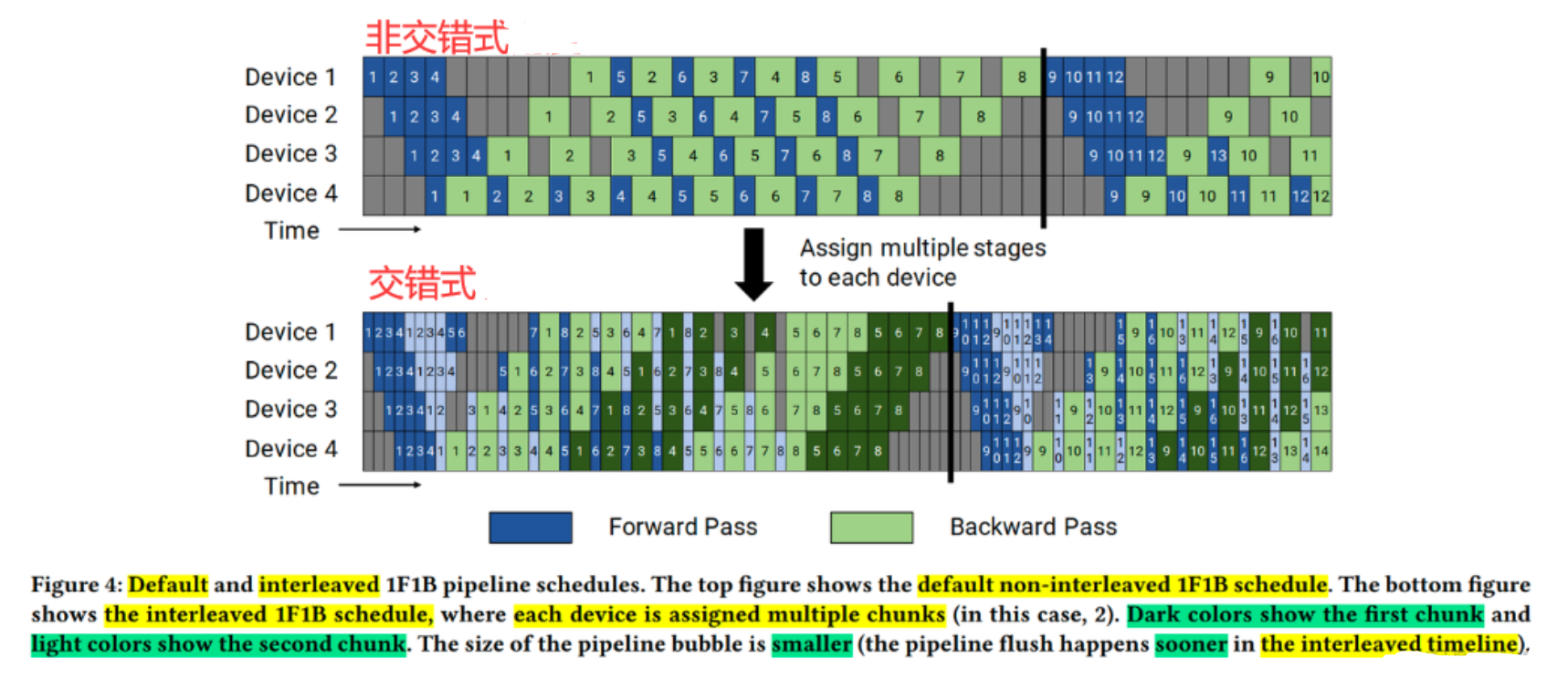
- 非交错式(Non-interleaved) :分为三个阶段:预热(Warmup,仅前向)、稳定(Steady,交替执行前向与反向)、收尾(Cooldown,仅反向)
- 交错式(Interleaved) :要求微批次数量是流水线阶段数的整数倍,通过交替执行不同微批次(Microbatch)的前向与反向传播,将空闲时段填充为有效计算
- 作用
- 虚拟流水线(Virtual Pipeline) :在设备数量不变时增加流水线阶段数(如将模型分成更多“块”),以更多通信量换取更小的流水线气泡(Bubble)
- 显存占用降低:通过及时释放中间结果,峰值显存较F-then-B策略减少约37.5%,显著支持更大模型训练。
- 设备利用率提升:下游设备在等待上游计算时可执行其他并行任务,减少空闲时间
- 缺点:
- 调度复杂性:需严格同步前向和反向任务的执行顺序,避免计算依赖冲突。
- 版本不一致(Weight Staleness):若同一设备同时处理不同批次的前向和反向任务,可能导致参数版本不一致。
- 解决方式:
- 1F1B-RR策略:采用轮询(round-robin)的调度模式将任务分配在同一个 stage 的各个设备上,保证微批次数据的前向传播计算和后向传播计算发生在同一台机器上
- 双权重缓冲策略:采用2BW(double-buffered weights)每处理完m个微批次(m≥d)后生成一个新的权重版本,新版本需暂时缓冲,直到所有依赖旧版本的计算完成,旧版本在后续输入不再使用时被丢弃,从而保证内存中最多同时存在两个版本权重的缓冲和旧权重依赖问题
- 原理
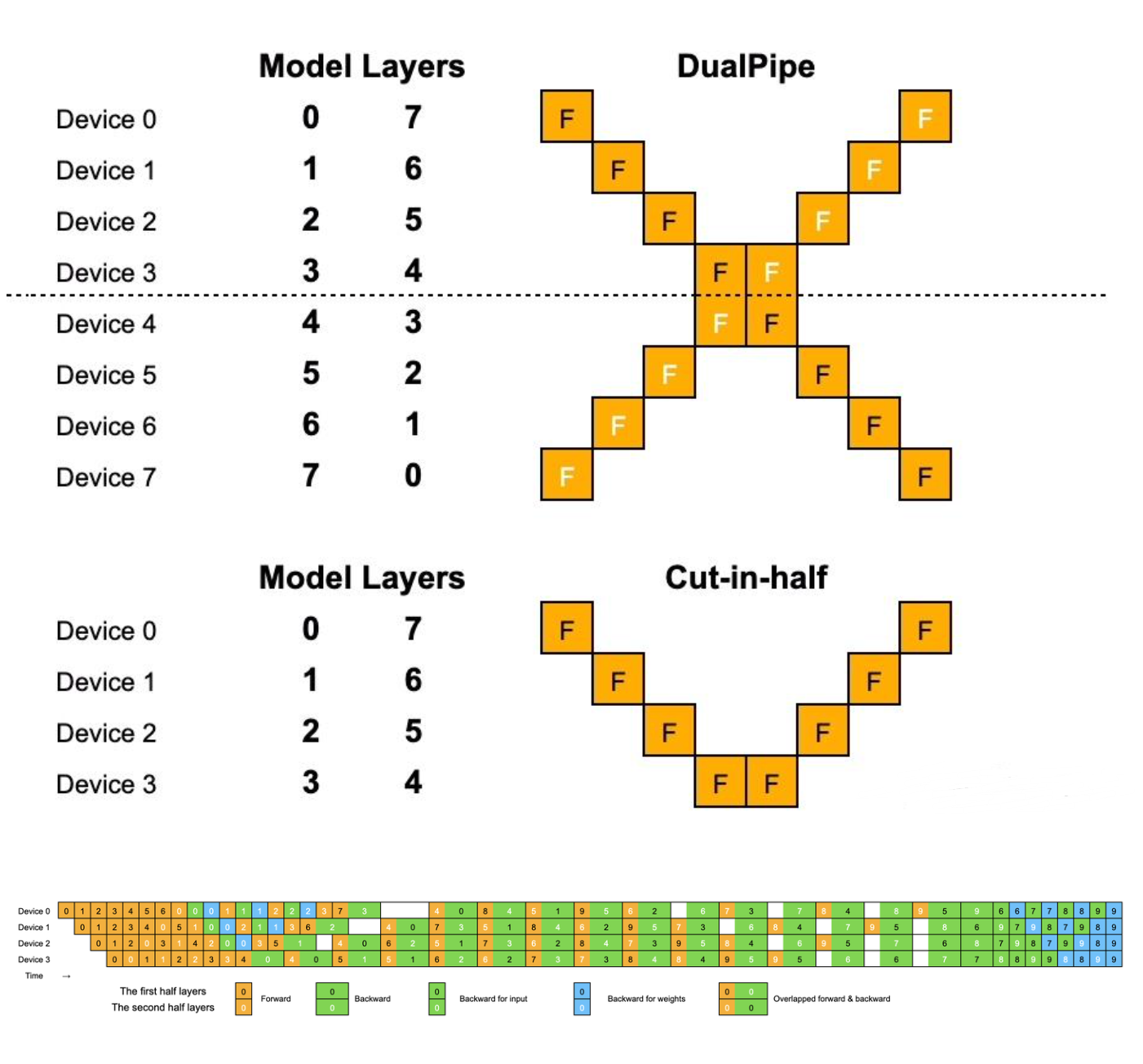
- DualPipe(双向流水线)
- 原理:
- 分块调度:将Micro-batch进一步拆分为Chunk,通过精细调度优化计算和通信的重叠,最大化GPU利用率。
- 双向流水线:从流水线两端同时输入微批次(正向与逆向),从而通过双向计算减少Bubble时间(空闲时间降低40%-60%)
- 问题
- 双向依赖冲突:正向和逆向流水线可能竞争同一设备资源,导致调度死锁
- 通信开销增加:双向流水线需要更复杂的跨设备通信协调
- 原理:
- DualPipe分块调度
- 核心思想:将一个微批次的
前向计算块和反向更新块进行拆分,并重新优化排布,从而实现计算和通信的重叠 - 基本原理:
- 细粒度化:将每个计算块分为四个组件:
注意力计算(attention)、全对全分发(all-to-all dispatch)、多层感知机拆除(MLP)和全对全合并(all-to-all combine),此外,还有一个流水线并行(PP)通信组件 - 重排:对于一对前向和反向计算块,重新排列这些组件,并通过手动调整GPU计算单元(SM)的分配比例,确保计算和通信的合适比例,从而使得通信过程可隐藏在计算过程中

- 细粒度化:将每个计算块分为四个组件:
- 核心思想:将一个微批次的
- DualPipeV型流水线
- 背景:冗余参数本质上是系统设计者为保障效率而付出的"容错成本",但是Sea AI Lab团队发现Dualpipe的参数冗余并非绝对必要,并通过数学证明和工程手段实现"减半不减效"
- 原理:
- V划分:将模型参数矩阵按V型对角线切割为上下两个半区,分别对应前向计算和反向更新
- 动态调度:将每个微批次(Micro-batch)进一步拆分为子任务块,根据设备负载动态分配任务块到不同设备。
- 计算-通信重叠
- 正向计算:执行第N层前向计算时,同步预加载第N+1层所需参数半区。
- 反向更新:更新第N层梯度时,提前释放第N-1层已用参数区域。
- 通过PTX指令级优化,实现GPU显存访问与NVLink传输的原子级交错
- 总结对比
| 技术 | 核心优化 | Bubble率 | 显存占用 | 适用场景 |
|---|---|---|---|---|
| 朴素流水线 | 按层切分 | 极高((O(K - 1/K))) | 低 | 小模型或验证性实验 |
| GPipe | 微批次填充 + 重计算 | 中(依赖M/K比) | 中高(需存激活值) | 中等规模同步训练 |
| PipeDream | 异步1F1B + 权重版本管理 | 低 | 高(多版本权重) | 超大规模异步训练 |
| DualPipe | 双向流水线 + Chunk调度 | 极低 | 中(动态分块) | 长序列、多模态混合训练 |
- 计算设备
- 中央处理器(Central Processing Unit,CPU)
- 图形处理器(Graphics Processing Unit,GPU)
- 张量处理器(Tensor Processing Unit,TPU)
- 神经网络处理器(Neural network Processing Unit,NPU)
- 训练流程
- 前向传播:把数据输入模型,得到预测结果
- 反向传播:根据预测结果和真实结果的差异,计算出要怎么调整模型参数
算法部分
- DualPipe项目的github链接地址
- 项目结构
- dualpipe文件夹
- dualpipe.py:核心实现文件,作为调度器调用其他文件
- DualPipe类实现双向流水线并行机制
- 处理分布式训练中的前向/反向传播调度
- 管理不同rank之间的通信协调
- 实现zero bubble流水线调度算法
- 处理micro-batch划分与梯度累积
- comm.py:通信管理模块,处理分布式通信相关的操作
- 定义P2P通信的tensor元信息管理(形状/数据类型)
- 提供通信操作封装:
- append_irecv:异步接收操作
- append_isend:异步发送操作
- 创建通信所需的占位tensor
- 封装底层distributed通信原语
- utils.py:工具函数模块,主要是进行梯度管理和张量操作相关的函数
WeightGradStore类:梯度存储队列管理- 张量处理工具:
chunk_tensor:张量分块cat_tensor:张量拼接scatter:数据分发gather:数据收集
- 反向传播引擎封装:
run_backward:自定义反向传播执行
- init.py:包定义文件,提供对外的统一接口
- 定义模块版本号
__version__ - 暴露公共API:
__all__ = [DualPipe, WeightGradStore, set_p2p_tensor_shapes, set_p2p_tensor_dtype] - 提供模块导入的快捷方式
- 定义模块版本号
- dualpipev.py: 代码基本和dualpipe.py文件相同,但是比其
先进一点- 随着DualPipe被开源,这里冗余的两份模型参数也被Sea AI Lab的专家们证明其实也不是必要的,提出了一个Cut-in-half的排布方法,可以把另一半做一个剪裁
- 受此启发,DeepSeek也增加了一个V型DualPipe的实现,即DualPipeV
- dualpipe.py:核心实现文件,作为调度器调用其他文件
- examples文件夹
- example_dualpipe.py
- example_dualpipe.py
- dualpipe文件夹
dualpipe.py文件
- 代码
- 初始化 :在
__init__方法中,初始化了模块、进程组、排名映射等信息。 - 重置状态 :在 _reset_states 方法中,重置了所有的状态变量,包括输入块、输出块、梯度块、损失块等。
- 前向传播计算 :在 _forward_compute_chunk 方法中,执行前向传播计算,并根据是否为最后一个阶段和是否需要返回输出,保存输出和损失。
- 反向传播计算 :在 _backward_compute_chunk 方法中,执行反向传播计算,并根据是否启用零气泡优化,处理权重梯度存储。
- 重叠的前向和反向传播计算 :在 _forward_backward_compute_chunk 方法中,如果支持重叠的前向和反向传播,则同时执行前向和反向传播计算。
- 数据接收和发送 :在 _recv_forward 、 _send_forward 、 _recv_backward 和 _send_backward 方法中,分别处理前向传播和反向传播的数据接收和发送。
- 通信操作 :在 _commit_and_wait_comm 方法中,提交并等待所有的通信操作完成。
- 权重更新 :在 _weight_chunk 方法中,执行权重更新操作。
- 释放张量 :在 _free_tensors 方法中,释放不再使用的张量。
- 执行步骤 :在 step 方法中,根据输入的参数,执行一系列的前向传播、反向传播和权重更新操作,最终返回损失和输出。
- 初始化 :在
# 导入必要的类型提示,用于函数参数和返回值的类型注解
# 导入必要的类型注解
from typing import Tuple, List, Union, Callable, Optional
import torch # 导入 PyTorch 库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
import torch.distributed as dist # 导入 PyTorch 的分布式训练模块
import dualpipe.comm as comm # 导入自定义的通信模块
# 导入自定义的工具模块
from dualpipe.utils import WeightGradStore, run_backward, scatter, gather
# 定义 DualPipe 类,继承自 nn.Module
class DualPipe(nn.Module):
def __init__(
self,
modules: Tuple[nn.Module, nn.Module],
batch_dim: int = 0,
process_group: Optional[dist.ProcessGroup] = None,
rank_mapping: Optional[List[int]] = None,
) -> None:
"""
作用:初始化 DualPipe 类,包括模块、进程组、排名映射等信息
参数:
- modules:接受包含两个nn.Module的元组,modules[0]处理正向阶段数据,modules[1]处理反向阶段数据
- batch_dim:适合数据划分的微批次切分维度(通常文本为0,图像为1,语音为2)
- process_group:控制分布式训练通信组的通信策略,
- rank_mapping:定义分布式训练中每个rank(进程的唯一标识)在pipeline rank(模型分层的数据计算阶段)中的执行顺序(不同GPU执行顺序?)
"""
# 1. 父类初始化:调用父类 nn.Module 的构造函数,从而确保实例能使用父类所有的属性和方法
super().__init__()
# 2. 检查设备:next从可迭代对象中获取第一个模块参数,并判断参数所在设备是否位于当前 CUDA 设备上,不在会抛出AssertionError,停止运行
assert next(modules[0].parameters()).device == torch.device(torch.cuda.current_device())
# 3. 封装模块:将两个模块封装到 nn.ModuleList 中
self.module = nn.ModuleList(modules)
# 4. 检查两个模块是否为同一类型,并且该类型是否具有 overlapped_forward_backward 方法。若满足,表示支持重叠的前向和反向传播。
self.overlapped_forward_backward = type(modules[0]) == type(modules[1]) and hasattr(type(modules[0]), "overlapped_forward_backward")
# 5. 获取批次维度、分布式进程组、进程组中的进程数量
self.batch_dim = batch_dim
self.group = process_group or dist.distributed_c10d._get_default_group()
self.num_ranks = self.group.size()
# 6. 初始化排名映射和反向排名映射
# rank_mapping: 将进程组中的排名映射到实际的流水线排名。
# rank_inverse_mapping: 将实际的流水线排名映射到进程组中的排名。
if rank_mapping is None: # 如果未提供排名映射,则使用默认的排名顺序
rank_mapping = list(range(self.num_ranks))
rank_inverse_mapping = [None] * (self.num_ranks + 1)
for i in range(self.num_ranks):
rank_inverse_mapping[rank_mapping[i]] = i
# 7. 获取进程在流水线中的排名,包括当前进程、前一个进程和下一个进程
self.rank = rank_mapping[self.group.rank()]
self.prev_rank = rank_inverse_mapping[self.rank - 1]
self.next_rank = rank_inverse_mapping[self.rank + 1]
# 8. 判断进程排名:判断当前进程是否为第一个进程和最后一个进程
self.is_first_rank = self.rank == 0
self.is_last_rank = self.rank == self.num_ranks - 1
def _reset_states(self) -> None:
"""
重置模型的各种状态,避免旧的状态影响新的计算。
"""
# 1. 清空权重梯度存储,避免在新的训练或推理步骤开始时出现旧梯度信息干扰
WeightGradStore.clear()
# 2. 初始化各种列表:包括输入、输出、输入梯度块列表、输出梯度块列表、标签列表、损失块列表和损失函数
self.input_chunks: Tuple[List[List[torch.Tensor]], List[List[torch.Tensor]]] = ([], [])
self.output_chunks: Tuple[List[List[torch.Tensor]], List[List[torch.Tensor]]] = ([], [])
self.input_grad_chunks: Tuple[List[List[torch.Tensor]], List[List[torch.Tensor]]] = ([], [])
self.output_grad_chunks: Tuple[List[List[torch.Tensor]], List[List[torch.Tensor]]] = ([], [])
self.labels: List[List[torch.Tensor]] = None
self.loss_chunks: List[torch.Tensor] = []
self.criterion: Callable = None
# 3. 初始化各种索引
self.current_f_chunk_id: List[int] = [0, 0] # 前向传播块的索引
self.current_b_chunk_id: List[int] = [0, 0] # 反向传播块的索引
self.current_send_f_chunk_id: List[int] = [0, 0] # 发送前向传播块的索引
self.current_send_b_chunk_id: List[int] = [0, 0] # 发送反向传播块的索引
self.current_recv_f_chunk_id: List[int] = [0, 0] # 接收前向传播块的索引
self.current_recv_b_chunk_id: List[int] = [0, 0] # 接收反向传播块的索引
# 4.初始化通信操作列表和待释放的张量列表
self.comm_ops: List[dist.P2POp] = []
self.to_free: List[torch.Tensor] = []
def _forward_compute_chunk(self, phase: int) -> None:
"""
作用:执行一个微批次的前向传播计算
参数:
phase (int): 当前阶段的编号,0表示第一个阶段,1表示第二阶段
"""
# 1. 获取当前前向传播块的索引,并增加索引,以便下次处理下一个块
chunk_id = self.current_f_chunk_id[phase]
self.current_f_chunk_id[phase] += 1 # current_f_chunk_id是用于记录每个阶段当前处理的微批次索引的列表
# 2. 获取当前输入块,在仅前向传播的情况下,输入数据在使用后不再需要,因此可以将其清空
inputs = self.input_chunks[phase][chunk_id]
if self.forward_only:
self.input_chunks[phase][chunk_id] = None
# 3. 判断是否为最后一个阶段(当前进程为第一个进程且当前阶段为第二阶段)
is_last_stage = (self.is_first_rank and phase == 1)
# 4. 执行前向传播计算,并处理输出格式
outputs = self.module[phase](*inputs)
outputs = [outputs] if isinstance(outputs, torch.Tensor) else outputs
# 5. 判断若为最后一个阶段且定义了损失函数,则计算损失并添加到损失块列表
if is_last_stage and self.criterion is not None:
labels = self.labels[chunk_id]
loss = self.criterion(*outputs, *labels)
self.loss_chunks.append(loss)
# 6. 如果是最后一个阶段且为阶段 0,则将输出作为下一个阶段的输入
if self.is_last_rank and phase == 0:
self.input_chunks[1].append([output.detach().requires_grad_() for output in outputs])
# 7. 如果不是最后一个阶段或需要返回输出,则保存输出
if (not is_last_stage) or self.return_outputs:
self.output_chunks[phase].append(outputs)
def _backward_compute_chunk(self, phase: int, enable_zb: bool = False) -> None:
"""
作用:执行一个微批次的反向传播计算
参数:
phase (int): 当前阶段的编号,0表示第一个阶段,1表示第二阶段
enable_zb (bool, 可选): 是否启用零气泡,默认为 False
"""
# 1. 如果只进行前向传播,则无需进行反向传播计算,直接返回
if self.forward_only:
return
# 2. 获取当前反向传播块的索引,并增加索引,以便下次处理下一个块,保证微批次按顺序依次处理
chunk_id = self.current_b_chunk_id[phase]
self.current_b_chunk_id[phase] += 1
# 3. 判断是否为最后一个阶段(当前进程为第一个进程且当前阶段为第二阶段)
is_last_stage = (self.is_first_rank and phase == 1)
# 4. enable_zb表示是否启用零气泡(zero bubble)技术,优化流水线并行中的计算效率,而开启零气泡需要先开启权重梯度存储
WeightGradStore.enabled = enable_zb
# 5. 如果是最后一个阶段,则从损失块列表中获取当前损失,并计算其梯度
if is_last_stage:
loss = self.loss_chunks[chunk_id]
loss.backward()
loss.detach_()
else:
# 获取当前输出块和输出梯度块
outputs = self.output_chunks[phase][chunk_id]
if not self.return_outputs:
self.output_chunks[phase][chunk_id] = None
output_grads = self.output_grad_chunks[phase][chunk_id]
self.output_grad_chunks[phase][chunk_id] = None
# 过滤掉空的输出和梯度
non_empty = [(t, g) for t, g in zip(outputs, output_grads) if g is not None]
outputs, output_grads = list(zip(*non_empty))
if len(outputs) > 0: # 执行反向传播计算
run_backward(outputs, output_grads)
# 6. 禁用权重梯度存储,且如果启用零气泡,则刷新权重梯度存储
WeightGradStore.enabled = False
if enable_zb:
WeightGradStore.flush()
# 7. 获取当前输入块,并清空该位置的输入块
inputs = self.input_chunks[phase][chunk_id]
self.input_chunks[phase][chunk_id] = None
# 8. 计算输入梯度
input_grads = [t.grad for t in inputs]
# 9. 如果是最后一个阶段且为阶段 1,则将输入梯度作为上一个阶段的输出梯度,不是则保存输入梯度
if self.is_last_rank and phase == 1:
self.output_grad_chunks[0].append(input_grads)
else:
self.input_grad_chunks[phase].append(input_grads)
def _forward_backward_compute_chunk(self, phase0: int, phase1: int) -> None:
"""
作用:执行一个微批次的前向和反向传播计算,支持重叠计算
参数:
phase0 (int): 第一个阶段的编号,0 或 1
phase1 (int): 第二个阶段的编号,0 或 1
"""
# 1. 如果只进行前向传播,则只执行前向传播计算
if self.forward_only:
self._forward_compute_chunk(phase0)
return
# 2. 如果不支持重叠计算,则分别执行前向和反向传播计算
if not self.overlapped_forward_backward:
self._forward_compute_chunk(phase0)
self._backward_compute_chunk(phase1)
return
# 以下为支持重叠操作的代码,则提前准备好前向传播和反向传播所需的信息,以便后续执行高效的重叠计算。
# 3. 预前向传播:准备前向传播的相关信息
chunk_id0 = self.current_f_chunk_id[phase0] # 获取当前前向传播块的索引,定位当前处理的微批次
self.current_f_chunk_id[phase0] += 1 # 增加索引,定位下一个微批次
module0 = self.module[phase0] # 获取对应模块
inputs0 = self.input_chunks[phase0][chunk_id0] # 获取对应输入
# 根据是否为最后一个阶段,确定标签和损失函数
is_last_stage0 = (self.is_first_rank and phase0 == 1)
if is_last_stage0 and self.criterion is not None:
labels0 = self.labels[chunk_id0]
criterion0 = self.criterion
else:
labels0 = []
criterion0 = None
# 4. 预反向传播:准备反向传播的相关信息
chunk_id1 = self.current_b_chunk_id[phase1] # 获取当前反向传播块的索引
self.current_b_chunk_id[phase1] += 1 # 增加索引,定位下一个微批次
module1 = self.module[phase1] # 获取对应模块
# 根据是否为最后一个阶段,确定损失、输出和输出梯度
is_last_stage1 = (self.is_first_rank and phase1 == 1)
if is_last_stage1: # 最后一个阶段,从损失块列表中获取损失
loss1 = self.loss_chunks[chunk_id1]
outputs1 = []
output_grads1 = []
else: # 非最后一个阶段,从输出和输出梯度块列表中获取
loss1 = None
outputs1 = self.output_chunks[phase1][chunk_id1]
if not self.return_outputs:
self.output_chunks[phase1][chunk_id1] = None
output_grads1 = self.output_grad_chunks[phase1][chunk_id1]
self.output_grad_chunks[phase1][chunk_id1] = None
non_empty = [(t, g) for t, g in zip(outputs1, output_grads1) if g is not None]
outputs1, output_grads1 = list(zip(*non_empty))
#(核心) 5. 执行前向和反向传播的重叠计算
# - 前向传播 :首先执行前向传播,计算当前阶段的输出和损失。
# - 反向传播 :在执行前向传播的同时,利用之前保存的信息进行反向传播计算梯度。
# - 同步与优化 :确保前向传播和反向传播的计算不会相互干扰,同时优化计算过程以提高效率。
outputs0, loss0 = type(module0).overlapped_forward_backward(
module0, inputs0, criterion0, labels0,
module1, loss1, outputs1, output_grads1,
)
# 8. 后前向传播:重叠计算后,对前向传播的输出和损失进行处理
if self.is_last_rank and phase0 == 0: # 当前进程是最后一个进程且处于阶段 0 时,会将前向传播的输出作为阶段1的输入
self.input_chunks[1].append([output.detach().requires_grad_() for output in outputs0])
if (not is_last_stage0) or self.return_outputs: # 不是最后一个阶段或需要返回输出,则保存输出
self.output_chunks[phase0].append(outputs0)
if is_last_stage0 and self.criterion is not None: # 是最后一个阶段且定义了损失函数,则计算损失并添加到损失块列表
self.loss_chunks.append(loss0)
# 9. 后反向传播:处理反向传播的输入和梯度
inputs = self.input_chunks[phase1][chunk_id1]
self.input_chunks[phase1][chunk_id1] = None
input_grads1 = [t.grad for t in inputs]
if self.is_last_rank and phase1 == 1:
self.output_grad_chunks[0].append(input_grads1)
else:
self.input_grad_chunks[phase1].append(input_grads1)
def _forward_chunk(self, phase: int, recv: bool = True, send: bool = True) -> None:
"""
作用:执行一个微批次的前向传播,包括接收、计算和发送操作
参数:
phase (int): 阶段编号,0 或 1
recv (bool, 可选): 是否接收数据,默认为 True
send (bool, 可选): 是否发送数据,默认为 True
"""
# 1. 如果需要接收数据,则接收前向传播数据
if recv:
self._recv_forward(phase)
# 2. 调用_commit_and_wait_comm提交并等待,确保之前所有的通信操作都已完成
self._commit_and_wait_comm()
# 3. 执行前向传播计算
self._forward_compute_chunk(phase)
# 4. 如果需要发送数据,则发送前向传播数据
if send:
self._send_forward(phase)
def _backward_chunk(self, phase: int, enable_zb: bool = False, recv: bool = True, send: bool = True) -> None:
"""
执行一个微批次的反向传播,包括接收、计算和发送操作。
参数:
phase (int): 阶段编号,0 或 1。
enable_zb (bool, 可选): 是否启用零气泡,默认为 False。
recv (bool, 可选): 是否接收数据,默认为 True。
send (bool, 可选): 是否发送数据,默认为 True。
"""
if recv:
self._recv_backward(phase)
self._commit_and_wait_comm()
self._backward_compute_chunk(phase, enable_zb)
if send:
self._send_backward(phase)
def _forward_backward_chunk(self, phase0: int, phase1: int, recv0: bool = True) -> None:
"""
执行一个微批次的前向和反向传播,包括接收、计算和发送操作。
参数:
phase0 (int): 第一个阶段的编号,0 或 1。
phase1 (int): 第二个阶段的编号,0 或 1。
recv0 (bool, 可选): 是否接收第一个阶段的数据,默认为 True。
"""
if recv0:
# 接收第一个阶段的前向传播数据
self._recv_forward(phase0)
# 接收第二个阶段的反向传播数据
self._recv_backward(phase1)
# 提交并等待通信操作完成
self._commit_and_wait_comm()
# 执行前向和反向传播计算
self._forward_backward_compute_chunk(phase0, phase1)
# 发送第一个阶段的前向传播数据
self._send_forward(phase0)
# 发送第二个阶段的反向传播数据
self._send_backward(phase1)
def _weight_chunk(self) -> None:
"""
按照FIFO顺序可以确保每个节点都按照相同的顺序处理梯度,避免因为梯度处理顺序不一致而导致的同步问题。
"""
if self.forward_only: # 如果只进行前向传播,则直接返回
return
self._commit_and_wait_comm() # 提交并等待通信操作
# Assume FIFO
# 假设为先进先出队列,从权重梯度存储队列WeightGradStore 中弹出一个元素
WeightGradStore.pop()
def _free_tensors(self) -> None:
"""
释放存储在 to_free 列表中的张量所占用的内存资源,避免训练过程中不及时释放无用张量的内存资源导致的内存泄漏。
"""
# 遍历检查将张量数据替换为空张量,从而将原来存储在该张量中的数据清空,释放这部分内存。
for tensor in self.to_free:
# 确保管道阶段不返回视图张量(视图张量是指那些共享底层数据的张量,它们本身并不拥有独立的数据存储)
assert tensor._base is None, f"pipeline stage should not return view tensors {dist.get_rank(), tensor.shape}"
tensor.data = torch.Tensor()
# 清空 to_free 列表
self.to_free = []
def _recv_forward(self, phase: int) -> None:
"""
接收前向传播的数据块。
"""
# 判断进程所处阶段决定是否接收前向传播的数据
# - 当前进程是第一个阶段且处于阶段 0,表示数据最初进入流水线的起点,所以无需接收
# - 当前进程是最后一个阶段且处于阶段 1。,表示数据已经到达流水线的终点,基于前面阶段传来的数据进行最终的计算,而不是再接收新的前向传播数据
if (self.is_first_rank and phase == 0) or (self.is_last_rank and phase == 1):
return
# 中间阶段接收数据块
self.current_recv_f_chunk_id[phase] += 1 # 记录接收数据块的数量
# 异步接收张量并添加到 comm_ops 中
tensors = comm.append_irecv(self.comm_ops, self.prev_rank if phase == 0 else self.next_rank, self.group)
self.input_chunks[phase].append(tensors) # 将接收到的张量添加到输入块列表中
def _send_forward(self, phase: int) -> None:
"""
发送前向传播的数据块。
"""
# 当前进程是第一个阶段且处于阶段 1 或者 当前进程是最后一个阶段且处于阶段 0 时不需要发送数据块
if (self.is_first_rank and phase == 1) or (self.is_last_rank and phase == 0):
# 如果是第一个阶段的第二阶段或最后一个阶段的第一阶段,则无需发送
return
# 获取当前要发送的前向传播块的 ID
chunk_id = self.current_send_f_chunk_id[phase]
# 增加当前发送的前向传播块的 ID
self.current_send_f_chunk_id[phase] += 1
# 获取要发送的张量
tensors = self.output_chunks[phase][chunk_id]
# 异步发送张量并添加到 comm_ops 中
comm.append_isend(self.comm_ops, tensors, self.next_rank if phase == 0 else self.prev_rank, self.group)
if not self.return_outputs:
# 如果不返回输出,则将张量添加到 to_free 列表中以便释放
self.to_free.extend(tensors)
def _recv_backward(self, phase: int) -> None:
"""
接收反向传播的数据块。
"""
if self.forward_only: # 如果只进行前向传播,则直接返回
return
if (self.is_first_rank and phase == 1) or (self.is_last_rank and phase == 0):
# 如果是第一个阶段的第二阶段或最后一个阶段的第一阶段,则无需接收
return
# 增加当前接收的反向传播块的 ID
self.current_recv_b_chunk_id[phase] += 1
# 异步接收张量并添加到 comm_ops 中
tensors = comm.append_irecv(self.comm_ops, self.next_rank if phase == 0 else self.prev_rank, self.group)
# 将接收到的张量添加到输出梯度块列表中
self.output_grad_chunks[phase].append(tensors)
def _send_backward(self, phase: int) -> None:
"""
发送反向传播的数据块。
"""
if self.forward_only:
# 如果只进行前向传播,则直接返回
return
if (self.is_first_rank and phase == 0) or (self.is_last_rank and phase == 1):
# 如果是第一个阶段的第一阶段或最后一个阶段的第二阶段,则无需发送
return
# 获取当前要发送的反向传播块的 ID
chunk_id = self.current_send_b_chunk_id[phase]
# 增加当前发送的反向传播块的 ID
self.current_send_b_chunk_id[phase] += 1
# 获取要发送的张量
tensors = self.input_grad_chunks[phase][chunk_id]
# 将输入梯度块列表中的对应元素置为 None
self.input_grad_chunks[phase][chunk_id] = None
# 异步发送张量并添加到 comm_ops 中
comm.append_isend(self.comm_ops, tensors, self.prev_rank if phase == 0 else self.next_rank, self.group)
def _commit_and_wait_comm(self) -> None:
"""
提交并等待所有通信操作完成。
"""
# 如果没有通信操作,则直接返回
if not self.comm_ops:
return
# 批量发送和接收通信操作
reqs = dist.batch_isend_irecv(self.comm_ops)
for req in reqs: # 等待每个通信操作完成
req.wait()
# 清空通信操作列表
self.comm_ops = []
# 释放存储在 to_free 列表中的张量
self._free_tensors()
def step(
self,
*inputs: Optional[torch.Tensor],
num_chunks: int = 0,
criterion: Optional[Callable] = None,
labels: List[Optional[torch.Tensor]] = [],
return_outputs: bool = False,
) -> Tuple[Optional[torch.Tensor], Optional[Union[torch.Tensor, Tuple[torch.Tensor]]]]:
"""
在分布式环境中执行一次训练或推理步骤,通过将输入数据分割成多个微批次(micro-batches),并在多个阶段进行前向传播和反向传播,以实现高效的并行计算
参数:
- *inputs : 模块的输入,仅在第一个进程中需要提供。
- num_chunks : 微批次的数量,必须大于 0 且至少为进程总数的 2 倍。
- criterion : 损失函数,仅在第一个进程中需要提供,调用方式为 criterion(*outputs, *labels) 。
- labels : 损失函数的标签,仅在第一个进程中需要提供。
- return_outputs : 是否在第一个进程中返回输出,默认为 False 。
返回值(元组(loss, outputs)):
- loss : 批次的损失,仅在第一个进程中返回。
- outputs : 模块的输出,仅当 return_outputs=True 且在第一个进程中返回。
"""
# 在分布式训练或推理中,进程间的点对点(P2P)通信需要预先知道张量的形状和数据类型,所以要先确保在执行前已经设置张量的形状和数据类型。
assert comm.TENSOR_SHAPES is not None and comm.TENSOR_DTYPE is not None, \
"You need to call set_p2p_tensor_shapes and set_p2p_tensor_dtype before executing a step."
# 判断是否只进行前向传播:梯度计算is_grad_enabled被禁用时,只进行前向传播。
self.forward_only = not torch.is_grad_enabled()
# 设置是否返回输出:控制在第一个进程中是否返回模型的输出
self.return_outputs = return_outputs
# 获取当前进程的排名和进程组的总排名数
rank = self.rank
num_ranks = self.num_ranks
# 确保微批次的数量大于 0 且大于等于总排名数的 2 倍:保证在多进程并行计算中,每个进程都有足够的微批次进行处理,避免出现数据不足的情况
assert num_chunks > 0 and num_chunks >= num_ranks * 2, f"{num_chunks=}, {num_ranks=}"
# 如果不是只进行前向传播(即需要进行反向传播),并且当前进程是第一个进程,那么必须提供损失函数 criterion
if not self.forward_only and self.is_first_rank:
assert criterion is not None
# 重置状态,避免之前的计算结果对本次计算产生影响。
self._reset_states()
# 如果当前进程是第一个进程,则将输入数据 inputs 和标签 labels 分割成 num_chunks 个微批次,并设置损失函数
if self.is_first_rank:
# 如果是第一个排名,则将输入和标签分割成多个微批次
self.input_chunks = (scatter(inputs, num_chunks, self.batch_dim), [])
self.labels = scatter(labels, num_chunks, self.batch_dim)
self.criterion = criterion
# Step 1: nF0,根据当前进程的排名和总进程数,计算要在阶段 0 进行多少次前向传播,让数据能够在流水线中流动。
# 计算第一步的迭代次数:num_ranks 是进程总数, rank 是当前进程的排名
step_1 = (num_ranks - rank - 1) * 2
# 通过多次前向传播,确保每个阶段都有数据可以处理,从而让流水线能够持续、高效地运行。
for i in range(step_1):
self._forward_chunk(0)
# Step 2: nF0F1,让阶段 0 和阶段 1 都开始工作,并相互能够进行配合
# 计算第二步的迭代次数
step_2 = rank + 1
self._recv_forward(0) # 接收阶段 0 的前向传播数据块。
for i in range(step_2):
# 执行前向传播块,不接收和发送数据
self._forward_chunk(0, recv=False, send=False)
# 接收前向传播数据块
self._recv_forward(0)
# 执行前向传播块,根据条件发送数据:如果当前进程不是最后一个进程,或者还未到达最后一次迭代,则发送数据。
self._forward_chunk(1, send=(not self.is_last_rank) or (i < step_2 - 1))
# 发送前向传播数据块
self._send_forward(0)
# Step 3: nB1W1F1,在阶段 1 开始反向传播和权重更新,同时继续在阶段 1 进行前向传播。使用“零气泡”技术是为了提高效率,减少空闲时间。
# 计算第三步的迭代次数
step_3 = num_ranks - rank - 1
for i in range(step_3):
# 执行反向传播块,启用零气泡
self._backward_chunk(1, enable_zb=True)
# 接收前向传播数据块
self._recv_forward(1)
# 处理权重块
self._weight_chunk()
# 执行前向传播块,不接收数据
self._forward_chunk(1, recv=False)
# Step 4 (Main step): nF0B1F1B0,让阶段 0 和阶段 1 同时进行前向传播和反向传播,实现高效的并行计算。
# 计算第四步的迭代次数
step_4 = num_chunks - num_ranks * 2 + rank + 1
for i in range(step_4):
if i == 0:
if self.is_last_rank:
# 如果是最后一个排名,则不重叠两个块以减少气泡大小
self._forward_chunk(0, recv=False, send=False)
self._send_forward(1)
self._backward_chunk(1, send=False)
self._send_forward(0)
self._send_backward(1)
else:
# 执行前向和反向传播块,不接收第一个阶段的数据
self._forward_backward_chunk(0, 1, recv0=False)
else:
# 执行前向和反向传播块
self._forward_backward_chunk(0, 1)
# 执行前向和反向传播块
self._forward_backward_chunk(1, 0)
# Step 5: nB1F1B0,
# 计算第五步的迭代次数
step_5 = num_ranks - rank - 1
for i in range(step_5):
# 执行反向传播块
self._backward_chunk(1)
# 执行前向和反向传播块
self._forward_backward_chunk(1, 0)
# Step 6: nB1B0 (The second half of the chunks use zero bubble)
# 计算第六步的迭代次数
step_6 = rank + 1
# 初始化是否启用零气泡
enable_zb = False
for i in range(step_6):
if i == step_6 // 2 and rank % 2 == 1:
# 如果是迭代次数的一半且排名为奇数,则启用零气泡
enable_zb = True
# 执行反向传播块,根据条件启用零气泡
self._backward_chunk(1, enable_zb=enable_zb)
if i == step_6 // 2 and rank % 2 == 0:
# 如果是迭代次数的一半且排名为偶数,则启用零气泡
enable_zb = True
# 执行反向传播块,根据条件启用零气泡
self._backward_chunk(0, enable_zb=enable_zb)
# Step 7: nWB0 (Use zero bubble)
# 计算第七步的迭代次数
step_7 = num_ranks - rank - 1
for i in range(step_7):
# 处理权重块
self._weight_chunk()
# 执行反向传播块,启用零气泡
self._backward_chunk(0, enable_zb=True)
# Step 8: nW,完成所有的权重更新操作。
# 计算第八步的迭代次数
step_8 = rank + 1
for i in range(step_8):
# 处理权重块
self._weight_chunk()
# 确保 WeightGradStore 中的函数队列为空
assert WeightGradStore.funcs_queue.empty()
# 提交并等待所有通信操作完成
self._commit_and_wait_comm()
# 初始化损失和输出
loss, outputs = None, None
if self.is_first_rank:
if criterion is not None:
# 如果提供了损失函数,则计算损失
loss = torch.stack(self.loss_chunks)
if return_outputs:
# 如果需要返回输出,则收集输出
outputs = gather(self.output_chunks[1], self.batch_dim)
if len(outputs) == 1:
# 如果只有一个输出,则直接返回该输出
outputs = outputs[0]
# 重置状态
self._reset_states()
# 返回损失和输出
return loss, outputs
comm.py文件
from typing import List, Tuple # 导入 List 和 Tuple 类型,用于类型提示
import torch # 导入 torch 库 ,用于深度学习
import torch.distributed as dist # 导入 torch.distributed 库,用于分布式训练
# 全局变量TENSOR_SHAPES:用于存储 P2P 通信时张量的形状,初始化为 None
TENSOR_SHAPES: List[Tuple[int]] = None
# 全局变量TENSOR_DTYPE:用于存储 P2P 通信时张量的数据类型,初始化为 None
TENSOR_DTYPE: torch.dtype = None
def set_p2p_tensor_shapes(shapes: List[Tuple[int]]):
"""
设置 P2P 通信时张量的形状,并将其存储在全局变量 TENSOR_SHAPES 中。
参数:
shapes (List[Tuple[int]]): 张量形状的列表,每个元素是一个表示张量形状的元组。
"""
# 声明使用全局变量 TENSOR_SHAPES
global TENSOR_SHAPES
# 将传入的形状列表赋值给全局变量 TENSOR_SHAPES
TENSOR_SHAPES = shapes
def set_p2p_tensor_dtype(dtype: torch.dtype):
"""
设置 P2P 通信时张量的数据类型。
参数:
dtype (torch.dtype): 张量的数据类型。
"""
# 声明使用全局变量 TENSOR_DTYPE
global TENSOR_DTYPE
# 将传入的数据类型赋值给全局变量 TENSOR_DTYPE
TENSOR_DTYPE = dtype
def build_from_tensor_shapes():
"""
根据预先设置的张量形状和数据类型创建空的可求导的 CUDA 张量。
返回值:
- List[torch.Tensor]: 包含多个空张量的列表,每个张量的形状由 TENSOR_SHAPES 定义,数据类型由 TENSOR_DTYPE 定义。
"""
# 遍历 TENSOR_SHAPES 中的每个形状,创建相应的空张量
return [torch.empty(s, dtype=TENSOR_DTYPE, device="cuda", requires_grad=True) for s in TENSOR_SHAPES]
def append_irecv(ops: List[dist.P2POp], src: int, group: dist.ProcessGroup) -> List[torch.Tensor]:
"""
向操作列表中添加异步接收操作。
参数:
ops (List[dist.P2POp]): 存储 P2P 操作的列表,即接收数据的任务添加的列表
src (int): 发送数据的源进程的局部排名
group (dist.ProcessGroup): 进程组,多个进程会组成一个组来协同工作
返回:
List[torch.Tensor]: 用于接收数据的张量列表。
"""
# 根据预先设置的形状和数据类型创建空张量
tensors = build_from_tensor_shapes()
# 获取源进程在全局进程组中的排名(把源进程的局部排名转换成全局排名,方便准确找到发送数据的进程)
src = dist.distributed_c10d.get_global_rank(group, src)
# 遍历每个张量,为非空张量添加异步接收操作到操作列表中
for tensor in tensors:
if tensor is not None:
ops.append(dist.P2POp(dist.irecv, tensor, src))
return tensors
def append_isend(ops: List[dist.P2POp], tensors: List[torch.Tensor], dst: int, group: dist.ProcessGroup) -> None:
"""
向操作列表中添加异步发送操作。
参数:
ops (List[dist.P2POp]): 操作列表,用于存储 P2P 操作。
tensors (List[torch.Tensor]): 要发送的张量列表。
dst (int): 接收数据的目标进程的局部排名。
group (dist.ProcessGroup): 进程组。
"""
# 获取目标进程在全局进程组中的排名
dst = dist.distributed_c10d.get_global_rank(group, dst)
# 遍历每个张量,为非空张量添加异步发送操作到操作列表中
for tensor in tensors:
if tensor is not None:
ops.append(dist.P2POp(dist.isend, tensor, dst))
comm.py文件
import queue
from typing import List, Callable
# 导入 torch 深度学习库,用于张量计算和自动求导
import torch
# 从 torch.autograd 中导入 Variable,用于自动求导操作
from torch.autograd import Variable
class WeightGradStore:
"""
这个类用于存储和管理权重梯度相关的操作函数。
提供了缓存、刷新、弹出和清空操作函数的功能。
"""
# 类属性,用于控制是否启用该功能
enabled: bool = False
# 缓存列表,用于存储可调用函数
cache: List[Callable] = []
# 队列,用于存储一组可调用函数
funcs_queue = queue.Queue()
@classmethod
def put(cls, func: Callable) -> None:
"""
将一个可调用函数添加到缓存列表中。
:param func: 要添加的可调用函数
"""
# 将传入的可调用函数添加到缓存列表中
cls.cache.append(func)
@classmethod
def flush(cls) -> None:
"""
将缓存列表中的所有函数添加到队列中,并清空缓存列表。
"""
# 将缓存列表作为一个元素放入队列中
cls.funcs_queue.put(cls.cache)
# 清空缓存列表
cls.cache = []
@classmethod
def pop(cls) -> None:
"""
从队列中取出一组函数并依次执行。
若队列为空,则抛出断言错误。
"""
# 检查队列是否为空,如果为空则抛出断言错误
assert not cls.funcs_queue.empty(), "Pop empty queue."
# 从队列中取出一组可调用函数
funcs = cls.funcs_queue.get()
# 遍历取出的可调用函数列表,并依次执行
for func in funcs:
func()
@classmethod
def clear(cls) -> None:
"""
清空缓存列表和队列。
"""
# 清空缓存列表
cls.cache = []
# 重新初始化队列为空队列
cls.funcs_queue = queue.Queue()
def run_backward(tensors: List[torch.Tensor], grad_tensors: List[torch.Tensor]) -> None:
"""
执行张量的反向传播操作。
:param tensors: 要进行反向传播的张量列表
:param grad_tensors: 对应的梯度张量列表
"""
# 定义反向传播的参数
kwargs = dict(
keep_graph=False, # 反向传播后是否保留计算图
create_graph=False, # 是否创建新的计算图用于高阶求导
allow_unreachable=True, # 是否允许不可达的节点
accumulate_grad=True, # 是否累加梯度
)
# 调用 Variable 的执行引擎执行反向传播操作
Variable._execution_engine.run_backward(tensors, grad_tensors, **kwargs)
def chunk_tensor(x, chunks, dim):
"""
将输入张量分割成指定数量的块。
如果输入为 None,则返回包含 None 的列表。
:param x: 输入张量
:param chunks: 要分割的块数
:param dim: 分割的维度
:return: 分割后的张量列表
"""
# 如果输入张量为 None
if x is None:
# 返回一个包含指定数量 None 的列表
return [None for _ in range(chunks)]
# 使用 tensor_split 方法将输入张量在指定维度上分割成指定数量的块
return x.tensor_split(chunks, dim=dim)
def cat_tensor(x, dim):
"""
将多个张量在指定维度上拼接成一个张量。
如果输入为单元素列表,则返回该元素;如果第一个元素为 None,则要求所有元素都为 None 并返回 None。
:param x: 要拼接的张量列表或元组
:param dim: 拼接的维度
:return: 拼接后的张量
"""
# 检查输入是否为列表或元组
if (isinstance(x, tuple) or isinstance(x, list)):
# 如果输入列表或元组只有一个元素
if len(x) == 1:
# 直接返回该元素
return x[0]
# 如果输入列表或元组的第一个元素为 None
elif x[0] is None:
# 断言所有元素都为 None
assert all(y is None for y in x)
# 返回 None
return None
# 使用 torch.cat 方法将输入的张量在指定维度上拼接成一个张量
return torch.cat(x, dim=dim)
def scatter(inputs, chunks, dim):
"""
将输入张量或张量列表分割成多个微批次。
:param inputs: 输入的张量、元组或列表
:param chunks: 要分割的微批次数量
:param dim: 分割的维度
:return: 微批次列表
"""
# 断言输入为 torch.Tensor、元组或列表类型
assert isinstance(inputs, (torch.Tensor, tuple, list))
# 如果输入是单个张量,将其转换为元组
if isinstance(inputs, torch.Tensor):
inputs = (inputs,)
# 断言输入中的每个元素要么为 None,要么为 torch.Tensor 类型
assert all(x is None or isinstance(x, torch.Tensor) for x in inputs)
# 对输入的每个张量进行分割操作
inputs = [chunk_tensor(x, chunks, dim) for x in inputs]
# 使用 zip 函数将分割后的张量组合成微批次列表
microbatches = [microbatch for microbatch in zip(*inputs)]
# 如果微批次列表为空
if len(microbatches) == 0:
# 生成包含指定数量空元组的列表
microbatches = [() for _ in range(chunks)]
# 返回微批次列表
return microbatches
def gather(micro_outputs, dim):
"""
将多个微批次的输出拼接成一个输出。
:param micro_outputs: 微批次的输出列表
:param dim: 拼接的维度
:return: 拼接后的输出元组
"""
# 断言微批次输出列表的第一个元素为 torch.Tensor、元组或列表类型
assert isinstance(micro_outputs[0], (torch.Tensor, tuple, list))
# 如果微批次输出列表的第一个元素是单个张量,将其转换为元组
if isinstance(micro_outputs[0], torch.Tensor):
micro_outputs = [(x,) for x in micro_outputs]
# 使用 zip 函数将微批次输出列表中的元素重新组合
outputs = [x for x in zip(*micro_outputs)]
# 对重新组合后的元素进行拼接操作,并转换为元组
outputs = tuple(cat_tensor(x, dim=dim) for x in outputs)
# 返回拼接后的输出元组
return outputs



















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











