






自然语言处理/
词袋模型是信息检索领域常用的文档表示方法。在信息检索中,词袋模型假定对于一个文本信息,忽略它的单词顺序和语法、句法等要素,只把这个文本看作若干词汇的集合,文档中每个单词的出现都是独立的。
eg:
- Jane wants to go to Shenzhen.
- Bob wants to go to Shanghai。
我们统计一下这两个句子一共有几个单词:
1.Jane 2.wants 3.to 4.go 5.Shenzhen 6.Bob 7.Shanghai
很明显有七个单词,因此我们可以开始构造一个长度为7的数组,来表示每一个单词的位置
于是,上面两个句子就可以用下列向量表示了 - 例句1:[1,1,2,1,1,0,0]
- 例句2:[0,1,2,1,0,1,1]
计算机视觉
对于一副图像,我们可以看作文档——若干个“词汇”的集合,同样的,视觉词汇之间没有顺序。
因为图像中的词汇不像文本中那样是现成的,我们首先要从图像中提取出相互独立的视觉词汇,通常需要三个步骤:
(1).特征检测
(2).特征表示
(3).单词本的生成

同一类目标的不同实例虽然存在差异,但我们仍然可以找到他们之间一些共同的地方,比如说人脸,虽然不同的人脸之间的差异比较大,但是眼睛、鼻子、嘴巴等一些部位却观察不到太大的差别,我们可以把不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
假设我们现在有三个目标类,分别是人脸、自行车、吉他。
step1:利用SIFT算法(SIFT算法能够从不同的尺度空间上查找关键点,并计算关键点的方向),从每类图像提取视觉词汇,将所有视觉词汇集合在一起,如下图所示

step2:利用K-Means算法构造单词表。K-Means算法可以根据SIFT提取的视觉词汇向量之间距离的远近,将词义相近的词汇合并,作为单词表中的基础词汇。当K为4时:
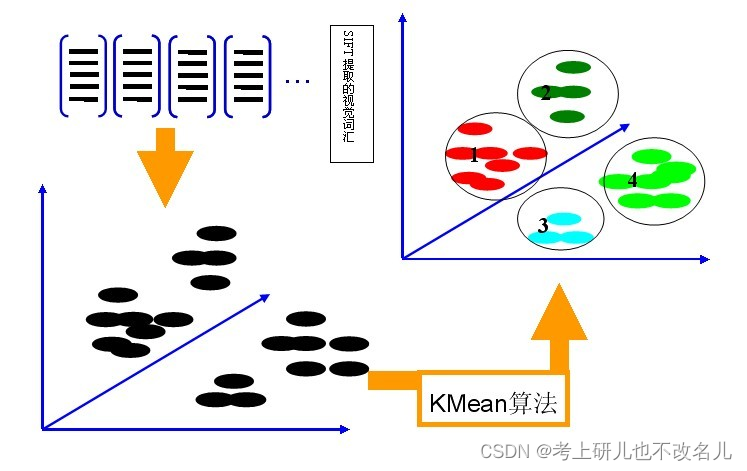
step3:利用单词表中的词汇表示图像。利用SIFT算法可以从每幅图像中提取很多特征点,这些特征点都可以用单词表中的单词近似代替,统计单词表中每个单词在图像中出现的次数,可以将图像表示为一个K=4维数值向量。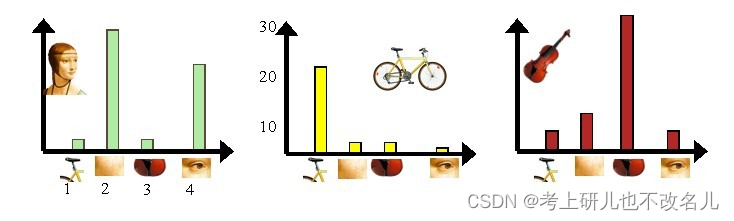















 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









