







0. 背景研究
在现在环境中,无论我们使用的是开源的ASR还是收费的ASR,都面临着一个问题,就是识别特定领域内的某些词汇时识别的不准确,比如一些人工智能和云计算领域有很多新兴的名词,就比如DeepSeek-R1和通义千问等待名词,如果我们使用市面上开源的语音识别模型做测试发现,识别出来的结果完全不对,甚至我们使用商业收费的ASR也不能准确识别,那么这个时候我们就很有必要做微调训练。
1. 数据准备
使用 DeepSeek-R1 大模型生成关于 AI 和云计算相关的句子,根据句子自己录制高质量无损音频,要求音频采样率大于等于16k,单通道,pcm_s16le 编码的 wav 音频。
需要准备两个文本文件,一个是标注文件,一个是音频路径文件。
标注文件 train_text.txt 格式如下:注意标注文本中不带标点符号。
dhfajks234123 你用过 DeepSeek-R1 大模型吗
bfdafkfkf1234 你觉得通义千问和 DeepSeek-R1 哪个更好用呢
音频路径文件 train_wav.scp 格式如下:注意音频一定要和标注文本对应上。
dhfajks234123 /root/autodl-tmp/data/audio/dhfajks234123.wav
bfdafkfkf1234 /root/autodl-tmp/data/audio/bfdafkfkf1234.wav
除了训练集外,还需要准备验证集和测试集,格式一样。
2. 生成jsonl文件
根据 train_text.txt 和 train_wav.scp 两个文件生成 jsonl 文件,执行下面命令生成。
sensevoice2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"]' \
++data_type_list='["source", "target"]' \
++jsonl_file_out="../../../data/list/train.jsonl" \
++model_dir='iic/SenseVoiceSmall'
3. 训练
bash finetune.sh
4. 查看loss曲线
执行下面命令启动 tensorboard 进程
ps -ef | grep tensorboard | awk '{print $2}' | xargs kill -9
nohup tensorboard --port 6007 --logdir /path/to/your/tf-logs/direction > tensorboard.log 2>&1 &
训练 loss 曲线如下图所示
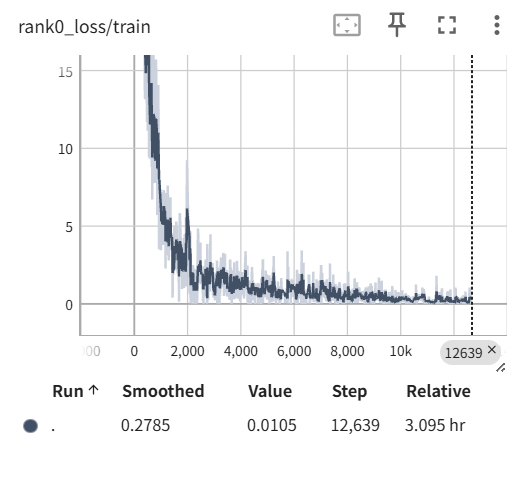
可以看到这个 loss 值很接近0,下降的很明显,说明模型有学习到内容。
5. 评估字错率
5.1 训练前字错率
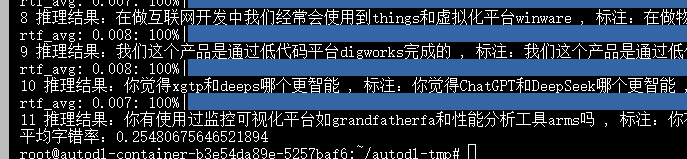
5.2. 训练后字错率

经过训练前后字错率对比发现,训练后的字错率下降了大概23.7%,说明训练是有效果的。
6. 应用
把训练好后的模型 model.pt 文件替换官方默认的 model.pt 文件。
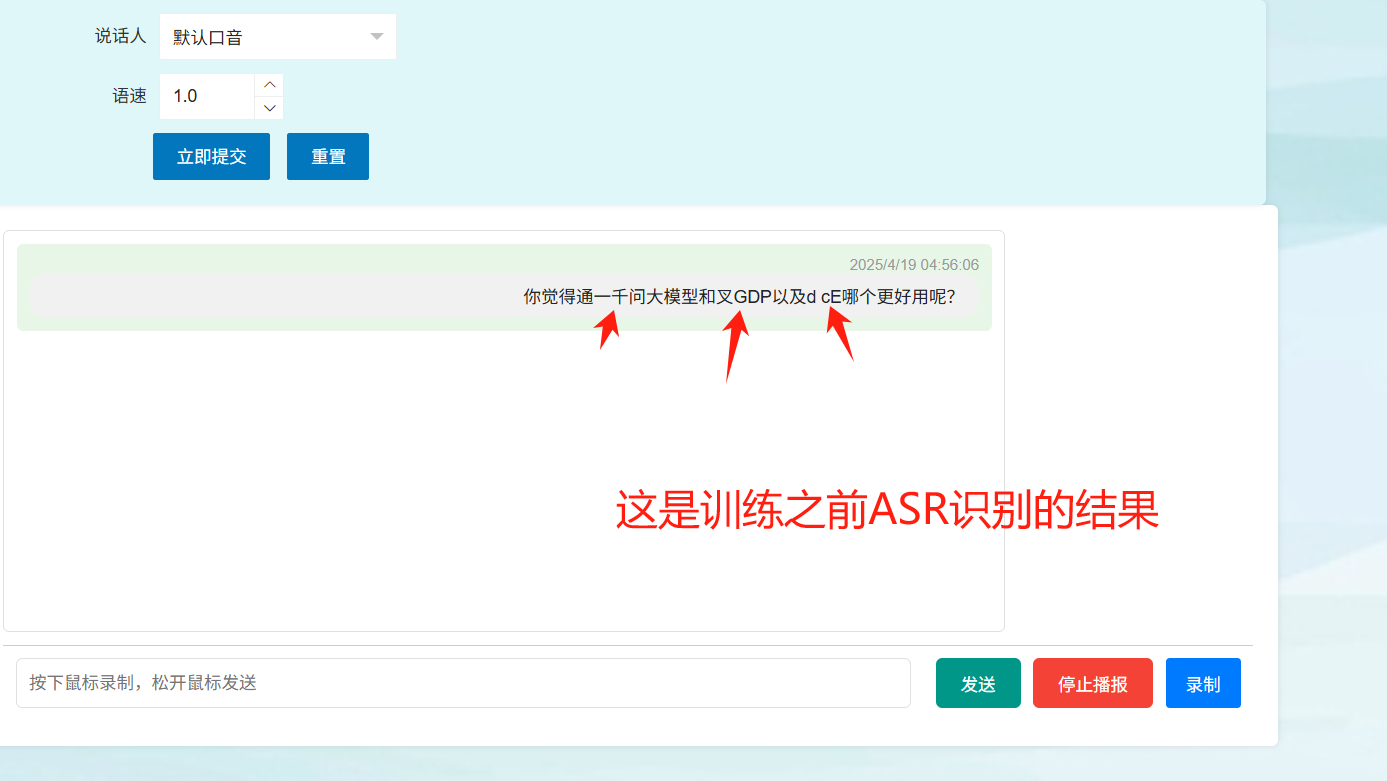
集成到 ASR_LLM_TTS 项目中,训练之前的效果如下:
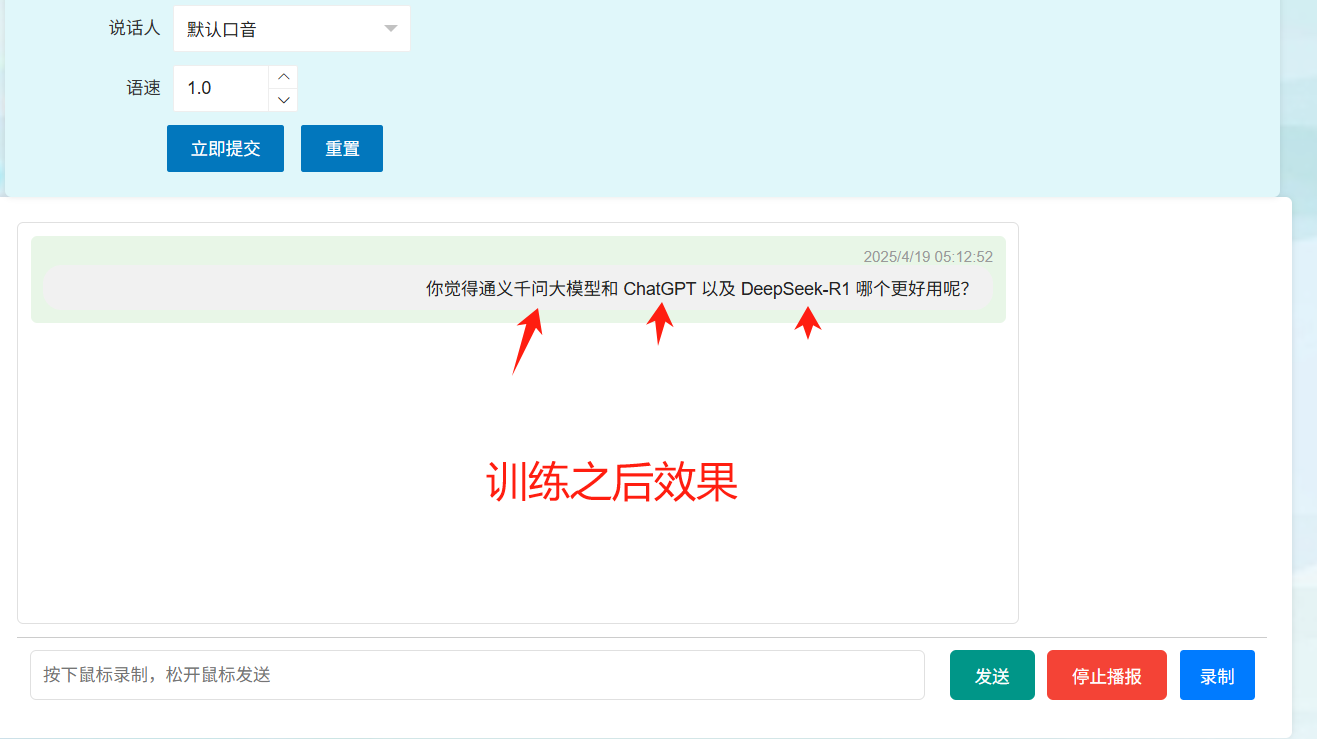
训练之后的效果如下:
7. 其它
本篇文章出自我的个人博客,要想看更多内容,欢迎点击这里访问我的博客。

















 4142
4142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









