







目录
一、Faiss 定义
Faiss(Facebook AI Similarity Search)是由Facebook AI Research团队开发的一个用于高效相似性搜索和稠密向量聚类的库。它能够处理大规模的向量数据集,支持在十亿级别的向量上进行快速的相似度搜索。Faiss用C++编写,并提供了与Python的接口,同时支持GPU加速。
Faiss 应用
图像检索:在图像数据库中,通过Faiss可以快速找到与目标图像相似的其他图像。
文本相似性比较:在大规模文本数据中,利用Faiss可以快速找出相似的文本片段。
推荐系统:在推荐系统中,Faiss可以用于根据用户的兴趣向量找到相似的推荐内容。
特征匹配:例如在商品库中匹配相似的商品,或者在音乐库中匹配相似的音乐。
Faiss 最新信息
性能提升:Faiss在处理大规模数据集时表现出色,能够在极短的时间内完成相似性搜索。
索引类型:支持多种索引类型,如倒排索引(IVF)、积量化(PQ)、HNSW等,以适应不同的搜索需求。
安装与使用:Faiss可以通过pip或conda进行安装,支持CPU和GPU版本。
pip install -qU langchain-community faiss-cpu
pip install -qU langchain-openai
二、初始化向量库
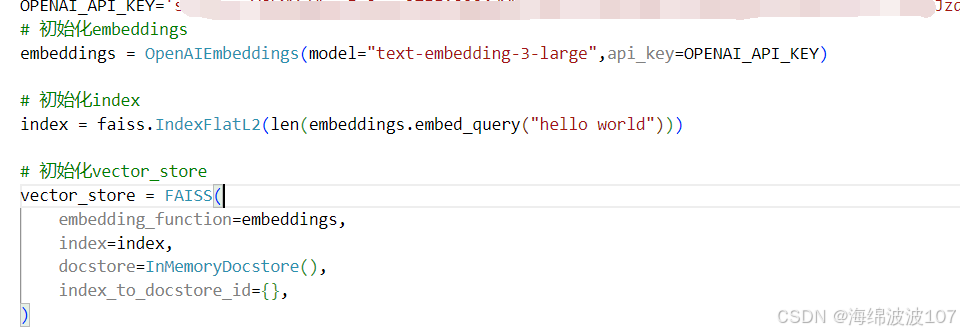
使用openai_api_key时需要挂VPN
三、管理矢量存储
1.将项目添加到向量库中
准备了10个文档

然后将文档添加到向量库中
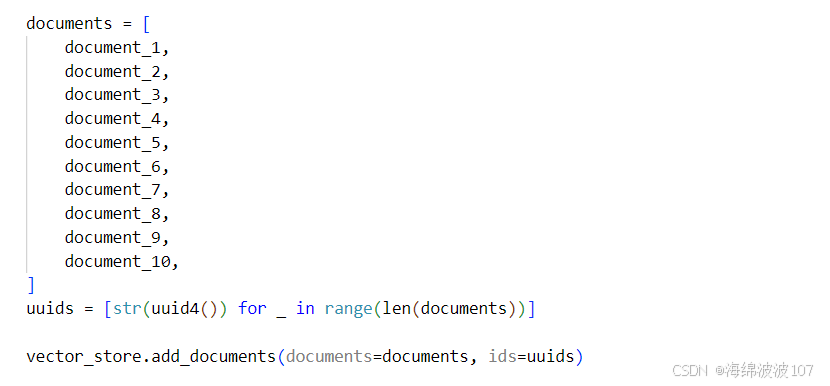
会用uuid4()函数为每一个文档生成一个(随机的16字节,概率上重复率极低,所以是唯一)唯一标识符


2.从向量库中删除项目
删除最后一个元素

四、查询向量存储
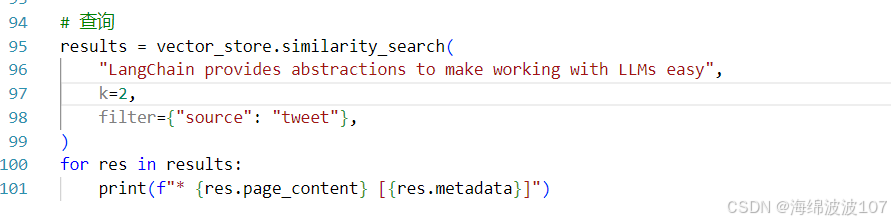
1.直接查询
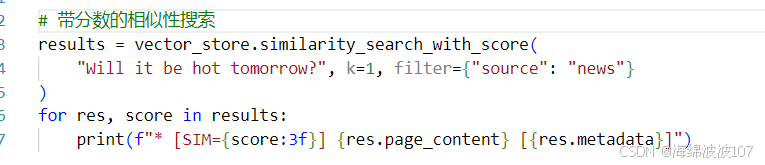
相似性搜索,从十条文档中找出相似的2个条目

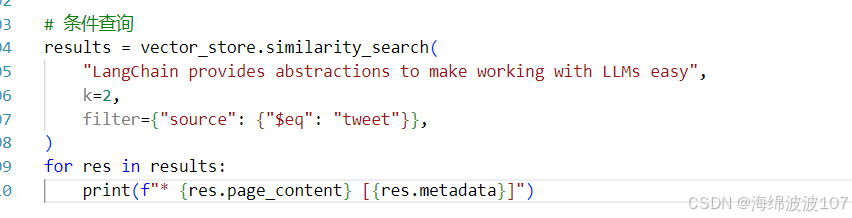
高级条件查询


2.转换为retriever进行查询
这段内容描述的是如何将一个向量存储(vector store)转换为一个检索器(retriever),以便在某种链式处理流程中更方便地使用。以下是对这段内容的详细解释:
向量存储(Vector Store)
- 概念:向量存储是一种数据结构,用于存储和管理向量数据。在自然语言处理和其他机器学习任务中,文本或其他数据通常会被转换为向量形式,以便进行相似度计算和检索。
- 用途:它可以用于存储大量文本的向量表示,以便后续进行快速的相似性搜索或检索操作.
检索器(Retriever)
- 概念:检索器是一个用于从向量存储中检索相关向量的工具或组件。它可以根据查询条件从存储中找到最相关的向量或数据项.
- 作用:在信息检索、问答系统等场景中,检索器用于快速找到与用户查询最相关的数据,从而提高系统的响应速度和准确性.

代码解释
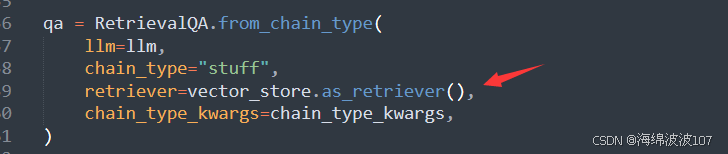
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 1})
vector_store.as_retriever():将向量存储转换为检索器。这个方法接受一些参数来配置检索器的行为.search_type="mmr":指定使用最大边际相关性(Maximal Marginal Relevance, MMR)作为搜索算法。MMR是一种在检索过程中平衡相关性和多样性的算法,常用于信息检索和推荐系统中,以确保检索结果既相关又具有一定的多样性.search_kwargs={"k": 1}:设置搜索参数,其中k=1表示每次搜索只返回一个最相关的结果.
retriever.invoke("Stealing from the bank is a crime", filter={"source": "news"})
retriever.invoke():调用检索器进行查询。这个方法接受查询字符串和一些过滤条件.- 查询字符串:“Stealing from the bank is a crime” 是要检索的内容,检索器会根据这个查询字符串在向量存储中寻找最相关的向量或数据项.
- 过滤条件:
filter={"source": "news"}表示只从来源为 “news” 的数据中进行检索,这是一种数据过滤机制,用于限制检索范围,提高检索的针对性和准确性.
检索器相当于直接查询相似性的封装,设置了检索方法和返回的检索结果个数。
检索器就是调用接口入口
五、保存和加载
可以把向量库保存到本地,并加载他。这样就不用在每次使用时重新创建

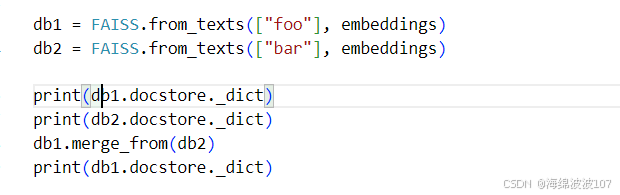
六、向量库合并
源代码
import getpass
import os
from langchain_openai import OpenAIEmbeddings
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
from uuid import uuid4
from langchain_core.documents import Document
OPENAI_API_KEY='skxxx'
# 初始化embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large",api_key=OPENAI_API_KEY)
# 初始化index
index = faiss.IndexFlatL2(len(embeddings.embed_query("hello world")))
# 初始化vector_store
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
# 初始化文档
document_1 = Document(
page_content="I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
document_3 = Document(
page_content="Building an exciting new project with LangChain - come check it out!",
metadata={"source": "tweet"},
)
document_4 = Document(
page_content="Robbers broke into the city bank and stole $1 million in cash.",
metadata={"source": "news"},
)
document_5 = Document(
page_content="Wow! That was an amazing movie. I can't wait to see it again.",
metadata={"source": "tweet"},
)
document_6 = Document(
page_content="Is the new iPhone worth the price? Read this review to find out.",
metadata={"source": "website"},
)
document_7 = Document(
page_content="The top 10 soccer players in the world right now.",
metadata={"source": "website"},
)
document_8 = Document(
page_content="LangGraph is the best framework for building stateful, agentic applications!",
metadata={"source": "tweet"},
)
document_9 = Document(
page_content="The stock market is down 500 points today due to fears of a recession.",
metadata={"source": "news"},
)
document_10 = Document(
page_content="I have a bad feeling I am going to get deleted :(",
metadata={"source": "tweet"},
)
documents = [
document_1,
document_2,
document_3,
document_4,
document_5,
document_6,
document_7,
document_8,
document_9,
document_10,
]
# 生成文档的唯一标识符
uuids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=uuids)
# vector_store.delete(ids=[uuids[-1]])
# 查询
# results = vector_store.similarity_search(
# "LangChain provides abstractions to make working with LLMs easy",
# k=2,
# filter={"source": "tweet"},
# )
# for res in results:
# print(f"* {res.page_content} [{res.metadata}]")
# 条件查询
# results = vector_store.similarity_search(
# "LangChain provides abstractions to make working with LLMs easy",
# k=2,
# filter={"source": {"$eq": "tweet"}},
# )
# for res in results:
# print(f"* {res.page_content} [{res.metadata}]")
# 带分数的相似性搜索
# results = vector_store.similarity_search_with_score(
# "Will it be hot tomorrow?", k=1, filter={"source": "news"}
# )
# for res, score in results:
# print(f"* [SIM={score:3f}] {res.page_content} [{res.metadata}]")
# 使用MMR进行检索
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 1})
retriever.invoke("Stealing from the bank is a crime", filter={"source": "news"})
# 保存和加载向量库
vector_store.save_local("faiss_index")
new_vector_store = FAISS.load_local(
"faiss_index", embeddings, allow_dangerous_deserialization=True
)
docs = new_vector_store.similarity_search("qux")
# print(docs[0])
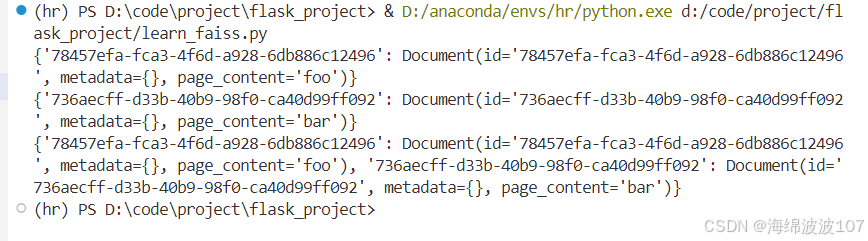
db1 = FAISS.from_texts(["foo"], embeddings)
db2 = FAISS.from_texts(["bar"], embeddings)
print(db1.docstore._dict)
print(db2.docstore._dict)
db1.merge_from(db2)
print(db1.docstore._dict)


















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











