






目录
Low-stage feature alignment module
Low-stage information fusion module
High-stage feature alignment module.
High-stage information fusion module.
Gold-yolo解决了一个怎样的问题?
FPN简述
——摘自详解FPN网络-CSDN博客

图(a)中,针对每一层的特征进行提取和预测,只要在任意层中检测到了目标即算检测成功,但是这种方法对于内存和时间的消耗都极大,故鲜有使用;
#图(b)中,像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。使用感受野最大的一层,与(a)相比,虽然节约了时间,但是难以实现小特征的检测。
——详参RCNN、Fast RCNN、Faster RCNN算法详细介绍_AI追随者的博客-CSDN博客
#图(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,这种方式不会增加额外的计算量。单但是这种方式的代价便是小目标检测的准确率
图(d)便是FPN网络,在以上几种方法的基础上,FPN通过不同层级的特征融合实现了准确率和速度的最优解。如下图所示,在FPN网络中,首先对于检测图片自上而下形成特征金字塔,然后以类似残差网络的形式进行自下而上的特征融合,例如,左侧从上到下依次编号1,2,3,4,右侧依次编号1',2',3',1'进行2倍上采样,而2通过1*1卷积进行resize,而后两者融合后进行预测。

FPN的缺陷

但是,FPN也同样存在一个缺陷——对于不同层级之间的信息融合,例如 level-1和level-2,其融合可以直接进行,但是,对于跨层级的融合,如level-1和level-3,需要先融合level-2和level-3,然后level-1再通过融合后的结果间接地获取level-3的信息,此方法会造成信息传递过程中的丢失,使信息融合的有效性收到限制。
Gold-yolo做出的改善
Gold-yolo采用了一种“聚集和分发”机制(GD),使用一个统一的模块来收集和融合所有Level的信息,然后将其分发到不同的Level,作者不仅避免了传统FPN结构固有的信息丢失,而且增强了中间层的部分信息融合能力,而不会显著增加延迟。
GD机制详解

GOLD-YOLO的结构如图所示,整体算法分为了两个阶段:Low-GD和High-GD,两者又都包含了三个部分:

FAM:特征对齐模块(Feature Alignment module),此模块负责收集并不同层次的特征信息,并统一规格
IFM:信息融合模块(Information Fusion Module),此模块负责融合FAM统一之后的特征信息,并产生全局的信息进行分配
Inject:信息注入模块(Information Injection Module),在IFM完成特征信息的融合之后,将其注入不同的层级,与FPN类似,最终使不同层级的特征检测能力得到增强。
先看引入后的结果:

先忽略LAF,仅看Low-GD和High-GD,可以发现,Low-GD在中,小目标的检测中有着明显的优势,而High-GD在大目标的检测中有着明显的优势,两者同时使用,虽然精度都有明显上升,但是在运算时间上做出了牺牲。
Low-GD

RB2=R,RB3=1/2R,RB4=1/4R,RB5=1/8R
Low-stage feature alignment module
低阶特征对齐模块
论文中,此模块采用了Avgpool进行特征对齐,但是在实际中发现使用B4为速度和准度综合最佳的大小,所以实际对齐方式为B2,B3平均池化,B5双线插值。
Low-stage information fusion module
低阶信息融合模块
该模块包括一个Repblock模块和分割模块。具体如如下公式所示:
Falign = Low_FAM ([B2, B3, B4, B5]),
Ffuse = RepBlock (Falign),
Finj_P3, Finj_P4 = Split(Ffuse).
什么是repblock?
参考RepVGG网络简介_太阳花的小绿豆的博客-CSDN博客
repblock是RepVGG的模块。在RepVGG中,作者提出了结构重参数化的概念。分为两步,第一步主要是将Conv2d算子和BN算子融合以及将只有BN的分支转换成一个Conv2d算子,第二步将每个分支上的3x3卷积层融合成一个卷积层。

一句话概述:将BN的系数和常数项分开,变成卷积的权重和偏重。
Information injection module
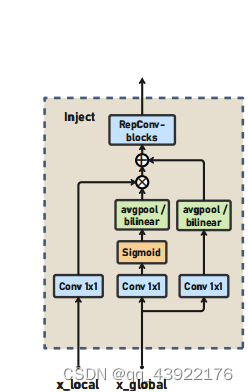
X_local:即本地特征
X_global:即通过Low_IFM之后的全局特征
这里的过程参考了Seaformer,X_global通过sigmoid激活之后和X_local卷积,最后再与X_global残差相加,而其中的维度差异则通过平均池化/双线性插值同化。
流程公式:
Fglobal_act_Pi = resize(Sigmoid(Convact(Finj_Pi)))
Fglobal_embed_Pi = resize(Convglobal_embed_Pi(Finj_Pi)),
Fatt_fuse_Pi = Convlocal_embed_Pi(Bi) ∗ Fglobal_act_Pi + Fglobal_embed_Pi,
P i = RepBlock(Fatt_fuse_Pi).
High-GD
High-stage feature alignment module.
高阶特征对齐模块
与低阶相同,也是使用avgpool对齐。
High-stage information fusion module.


Information injection module.
信息注入模块(高阶)
与低阶相同的方式,维度有差异。
LAF

如上图所示,GOLD-yolo在Inject阶段加入了LAF机制,而LAF又分为了Low-stage和high-stage。
还是先看结果:
之前已经看过了Low-GD和high-GD的提升结果,现在,在加入LAF之后,可以看到,FPS几乎没有大变化的前提下,增加LAF使中,小目标的检测精度上有着明显提升。
PAFPN

论文中指出,LAF结构参考了PAFPN结构,那么,PAFPN是什么呢?

上图是PAFPN的结构,论文中分为了5个部分,其中,(a)即常规的FPN结构,但是,在PAFPN中,添加了(b)这个上采样的步骤,在完成上采样之后 ,通过(c)的Adaptive Feature Pooling模块进行特征融合。

而Gold-yolo中的LAF模块也是参考了Adaptive Feature Pooling这一模块。对于不同层级的local特征,通过上/下采样后进行concat,最后通过1*1卷积调整通道数(低阶为上下采样,高阶仅下采样)

此外,针对特征融合使用concat还是add,实验结果也显示,Concat无论是在精度还是时间上都更优.
一些可能的改进:
AFPN

除了上/下采样之外,引入ASFF(自适应空间融合)模块,用于增强关键层的特征信息。
FPT
实验结果

后续改进实验待发布














 1794
1794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









