







(效果可以爬取一面的,爬取任意的见这个)
- 观察获取图片的规律
- 获取网页源码
- 解析网页源码,获得图片的name与url
import re
import requests
import os
import time
import random
#创建文件夹函数
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.mkdir(path)
print("文件夹建立成功")
else:
print("已存在这个文件夹")
# keyword = input("输入检索内容:\n")
keyword = '哈利波特'
file_path = "./"+keyword+'img/'
mkdir(file_path)
url ='https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1616736717041_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
resp = requests.get(url = (url+keyword), headers=headers)
soure_code_web = resp.content.decode('utf-8')
#制定正则解析规则, 将其编译结果存入re_obj中,提高效率
re_obj = re.compile(r'"fromPageTitle":"(?P<title>.*?)".*?"thumbURL":"(?P<url_img>.*?)"',re.S)
#从网页源码中, 按照指定规则 获取迭代器
iter = re_obj.finditer(soure_code_web)
#遍历迭代器中的内容
for it in iter:
title= it.group("title")
#真正的title
title = re.search(r'(?P<name1>.*?)<.*>(?P<name2>.*)', it.group("title"))
if title is not None:
title = (title.group("name1")+title.group("name2"))
else:
title = (it.group("title"))
#为了满足文件命名的规则, 将非法字符替换为下划线
title = re.sub(r'[\\/?、*<>|]',"_",title)
#得到图片的url, 将url响应的二进制内容写入文件中,
url_img = it.group("url_img")
url_img_resp = requests.get(url=url_img,headers=headers)
with open(file=file_path+title+'.jpg',mode='wb') as fp:
fp.write(url_img_resp.content)
print(title+".jpg下载完成")
#随机休眠, 防止被检测
time.sleep(random.uniform(0.3,1.2))
print("done")

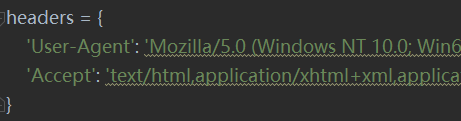
如果要指定搜索内容,尝试一下可以发现,修改word=<关键词>即可- 如果直接requests请求url,会被检测到,需要添加headers,至少添加两部分
- 获取到网页源代码后分析,按下f12 然后将光标指向某一图片,发现它的url如下,复制这个url,在网页源码里寻找,然后可以找到图片的url和名称。


4. 指定正则规则,获取这两部分内容
5.获取图片名字发现,名字里有《strong》.*?《/strong》
去掉,name1这部分可能会有内容,name2这里也是。如果< . * ? >根本就没检测到,经过正则表达式处理,结果为空。因此分情况处理。为空的话,说明名字已经符合规则了,不为空的话,就把name1和name2拼接起来。
6. 最后因为名字是一个文件的名字,所以要符合起名规则。
所以用re.sub这个方法替换这些。
7. 最后,再次请求url响应,把二进制内容存放进文件即可。















 3726
3726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









