







 本文旨在提出异步垂直联邦学习框架,保证数据安全、提高传输效率。介绍了垂直联邦学习适用于样本空间相同但特征空间不同的情况,还阐述了异步参数更新方法及改进措施。最后总结其与水平联邦学习区别,指出异步训练架构虽常用但难解决实际问题。
本文旨在提出异步垂直联邦学习框架,保证数据安全、提高传输效率。介绍了垂直联邦学习适用于样本空间相同但特征空间不同的情况,还阐述了异步参数更新方法及改进措施。最后总结其与水平联邦学习区别,指出异步训练架构虽常用但难解决实际问题。
背景和动机
- 旨在提出一个异步垂直联邦学习框架
- 保证数据的安全性
- 提高传输效率
论文贡献
本篇论文提出了:
- 一个对于垂直联邦学习框架通用的最优化公式( optimization formulation)
- 灵活的异步训练架构
- 严格的收敛分析(这里不作说明)
垂直联邦学习(Vertical FL)
与我们常见的联邦学习(水平联邦学习)不同的是,垂直联邦学习或基于特征的联邦学习适用于两个数据集共享相同的样本空间但是特征空间不同的情况。例如,考虑在同一城市中的两家不同的公司,一家是银行,另一家是电子商务公司。他们的用户集可能包含该地区的大多数居民,因此他们的用户空间相交很大。但是,由于银行记录了用户的收支行为和信用等级,并且电子商务保留了用户的浏览和购买历史,因此它们的特征空间大不相同。在这种情况下我们便需要用到垂直的联邦学习
假设有M个cilent:
M
:
=
{
1
,
.
.
,
M
}
M := \{1,..,M\}
M:={1,..,M}。总的数据集大小为
N
N
N,则数据集可以表示为
{
x
n
,
y
n
}
n
=
1
N
\{\rm{x}_n,y_n\}_{n=1}^N
{xn,yn}n=1N。并且每个client上的特征集都不一样, 在第m个client上保存的特征为
x
n
,
m
∈
R
p
m
x_{n,m} \in R^{p_m}
xn,m∈Rpm,其中
p
m
p_m
pm表示第m个client上数据的维度,在垂直联邦学习框架中,每一个client需要学习一个embedding
h
m
(
θ
m
)
h_m(\theta_m)
hm(θm),其中
θ
m
\theta_m
θm是
h
m
h_m
hm的参数,将数据维度
p
m
p_m
pm映射到一个公共的维度
p
m
‾
\overline{p_m}
pm上,则
h
n
,
m
:
=
h
m
(
θ
m
;
x
n
,
m
)
∈
R
p
m
‾
h_{n,m} := h_m(\theta_m;x_{n,m}) \in R^{\overline{p_m}}
hn,m:=hm(θm;xn,m)∈Rpm,则整个系统需要优化的东西是:
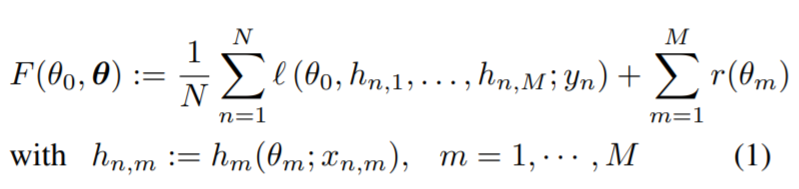
其中
θ
0
\theta_0
θ0是全局参数(全局模型),
θ
:
=
[
θ
1
T
,
.
.
.
,
θ
M
T
]
\theta := [\theta_1^T,...,\theta_M^T]
θ:=[θ1T,...,θMT]表示局部参数(局部模型),
r
(
θ
m
)
r(\theta_m)
r(θm)表示正则项
则我们需要传输的参数为
{
h
n
,
m
}
\{h_{n,m}\}
{hn,m}和梯度
(
▽
h
n
,
m
l
)
(\triangledown _{h_{n,m}}l)
(▽hn,ml),如下图所示:
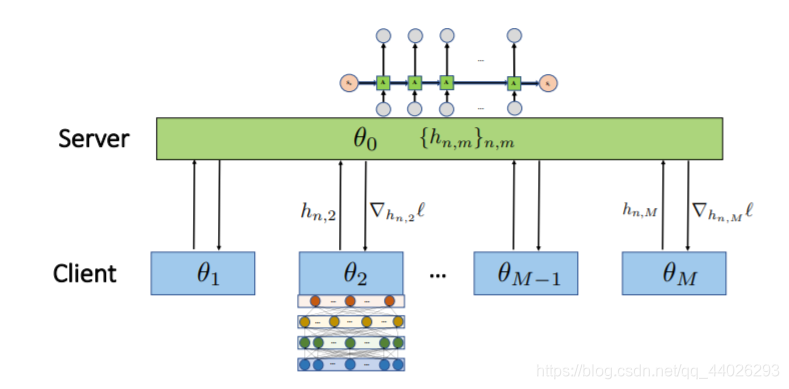
异步参数更新
在训练的过程中,server会一直等待,直到收到以下两种信息:
- 对于第m个设备的 h n , m h_{n,m} hn,m的一个梯度更新 ( ▽ h n , m l ) (\triangledown _{h_{n,m}}l) (▽hn,ml)的Query
- 第m个设备上传的参数
h
n
,
m
h_{n,m}
hn,m也就是
θ
m
\theta_m
θm
对于第一种信息,server会根据保存的 h n , m h_{n,m} hn,m计算对应的梯度并发送给对应的client,然后client会利用该梯度来更新本地的 θ m \theta_m θm,对于第二种信息,server会根据上传的 h n , m h_{n,m} hn,m来更新全局模型 θ 0 \theta_0 θ0,整个算法流程如下:

为了确保收敛,作者对上述训练方法进行了改进:当server收到t个不同client上传的参数时才更新全局模型,同时当server收到t个不同client发起的query时,才向t个client发送梯度:

总结
垂直联邦学习与我们熟知的水平联邦学习的区别就在于前者需要先将不同client上的特征空间先embedding到一个公共的特征空间上,然后运用传统的联邦学习方法来更新client上的参数,也就是embedding的参数 θ \theta θ。然后这篇论文提出的异步训练的架构核心在于,将异步训练下的一部分训练步骤变成同步的,也就是本来每一个client的训练都是异步的,但是为了减少延迟带来的问题,设置为每t个cilent的训练之间是异步的,但是这t个client内部的训练是同步的,server不会每来一个请求都进行相应的处理,而是每来t个请求才会进行回应。这也是目前很多研究者都使用的方法,但是并不能解决实际问题

















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









