






下载数据集分两个:
一是场景数据集
二是任务数据集
方法一:
github下载场景和任务数据集
1.下载MatterPort3D–15GB的场景数据集
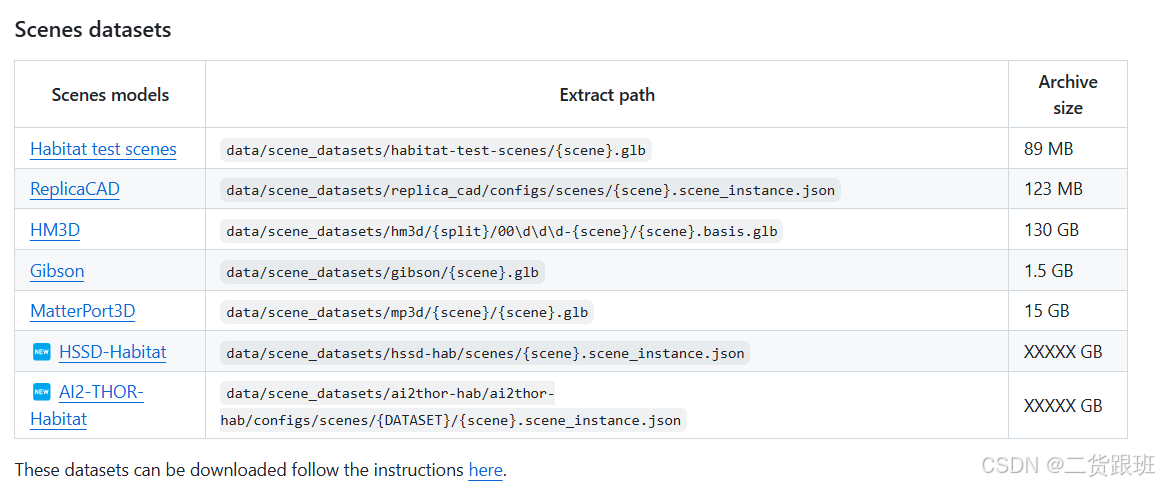
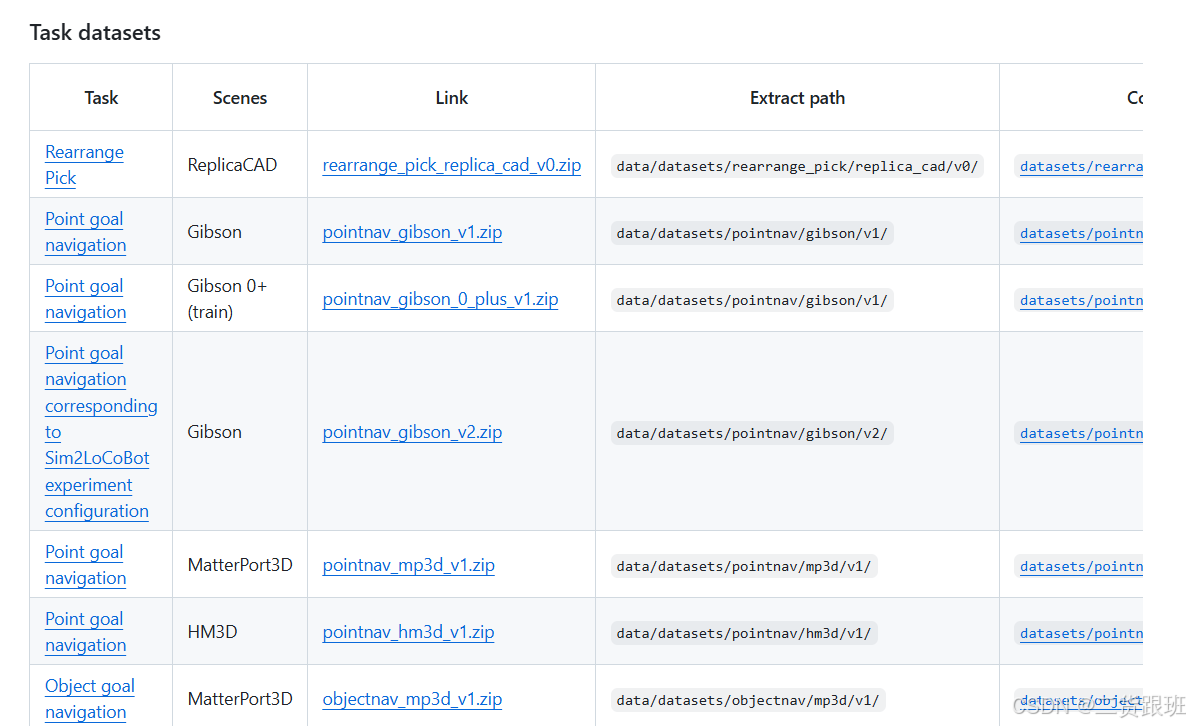
2.下载任务数据集
根据自己需求下载Object goal navigation或者Point goal navigation任务数据集
方法二
1.conda创建python2.7虚拟环境
conda create -n py27 python=2.7
2.进入虚拟环境
conda activate py27
3.运行download_mp.py
python download_mp.py --task habitat -o ./data
# --task habitat:指定任务为 habitat,这是脚本支持的一个任务类型(具体作用需参考脚本的实现)。
# -o ./data:指定输出目录为当前路径下的 data 文件夹,下载的内容会保存到此目录。
创建download_mp.py后执行上面命令:
#!/usr/bin/env python
# Downloads MP public data release
# Run with ./download_mp.py (or python download_mp.py on Windows)
# -*- coding: utf-8 -*-
import argparse
import collections
import os
import tempfile
import urllib
BASE_URL = 'http://kaldir.vc.in.tum.de/matterport/'
RELEASE = 'v1/scans'
RELEASE_TASKS = 'v1/tasks/'
RELEASE_SIZE = '1.3TB'
TOS_URL = BASE_URL + 'MP_TOS.pdf'
FILETYPES = [
'cameras',
'matterport_camera_intrinsics',
'matterport_camera_poses',
'matterport_color_images',
'matterport_depth_images',
'matterport_hdr_images',
'matterport_mesh',
'matterport_skybox_images',
'undistorted_camera_parameters',
'undistorted_color_images',
'undistorted_depth_images',
'undistorted_normal_images',
'house_segmentations',
'region_segmentations',
'image_overlap_data',
'poisson_meshes',
'sens'
]
TASK_FILES = {
'keypoint_matching_data': ['keypoint_matching/data.zip'],
'keypoint_matching_models': ['keypoint_matching/models.zip'],
'surface_normal_data': ['surface_normal/data_list.zip'],
'surface_normal_models': ['surface_normal/models.zip'],
'region_classification_data': ['region_classification/data.zip'],
'region_classification_models': ['region_classification/models.zip'],
'semantic_voxel_label_data': ['semantic_voxel_label/data.zip'],
'semantic_voxel_label_models': ['semantic_voxel_label/models.zip'],
'minos': ['mp3d_minos.zip'],
'gibson': ['mp3d_for_gibson.tar.gz'],
'habitat': ['mp3d_habitat.zip'],
'pixelsynth': ['mp3d_pixelsynth.zip'],
'igibson': ['mp3d_for_igibson.zip'],
'mp360': ['mp3d_360/data_00.zip', 'mp3d_360/data_01.zip', 'mp3d_360/data_02.zip', 'mp3d_360/data_03.zip', 'mp3d_360/data_04.zip', 'mp3d_360/data_05.zip', 'mp3d_360/data_06.zip']
}
def get_release_scans(release_file):
scan_lines = urllib.urlopen(release_file)
scans = []
for scan_line in scan_lines:
scan_id = scan_line.rstrip('\n')
scans.append(scan_id)
return scans
def download_release(release_scans, out_dir, file_types):
print('Downloading MP release to ' + out_dir + '...')
for scan_id in release_scans:
scan_out_dir = os.path.join(out_dir, scan_id)
download_scan(scan_id, scan_out_dir, file_types)
print('Downloaded MP release.')
def download_file(url, out_file):
out_dir = os.path.dirname(out_file)
if not os.path.isfile(out_file):
print '\t' + url + ' > ' + out_file
fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)
f = os.fdopen(fh, 'w')
f.close()
urllib.urlretrieve(url, out_file_tmp)
os.rename(out_file_tmp, out_file)
else:
print('WARNING: skipping download of existing file ' + out_file)
def download_scan(scan_id, out_dir, file_types):
print('Downloading MP scan ' + scan_id + ' ...')
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
for ft in file_types:
url = BASE_URL + RELEASE + '/' + scan_id + '/' + ft + '.zip'
out_file = out_dir + '/' + ft + '.zip'
download_file(url, out_file)
print('Downloaded scan ' + scan_id)
def download_task_data(task_data, out_dir):
print('Downloading MP task data for ' + str(task_data) + ' ...')
for task_data_id in task_data:
if task_data_id in TASK_FILES:
file = TASK_FILES[task_data_id]
for filepart in file:
url = BASE_URL + RELEASE_TASKS + '/' + filepart
localpath = os.path.join(out_dir, filepart)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded task data ' + task_data_id)
def main():
parser = argparse.ArgumentParser(description=
'''
Downloads MP public data release.
Example invocation:
python download_mp.py -o base_dir --id ALL --type object_segmentations --task_data semantic_voxel_label_data semantic_voxel_label_models
The -o argument is required and specifies the base_dir local directory.
After download base_dir/v1/scans is populated with scan data, and base_dir/v1/tasks is populated with task data.
Unzip scan files from base_dir/v1/scans and task files from base_dir/v1/tasks/task_name.
The --type argument is optional (all data types are downloaded if unspecified).
The --id ALL argument will download all house data. Use --id house_id to download specific house data.
The --task_data argument is optional and will download task data and model files.
''',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('-o', '--out_dir', required=True, help='directory in which to download')
parser.add_argument('--task_data', default=[], nargs='+', help='task data files to download. Any of: ' + ','.join(TASK_FILES.keys()))
parser.add_argument('--id', default='ALL', help='specific scan id to download or ALL to download entire dataset')
parser.add_argument('--type', nargs='+', help='specific file types to download. Any of: ' + ','.join(FILETYPES))
args = parser.parse_args()
print('By pressing any key to continue you confirm that you have agreed to the MP terms of use as described at:')
print(TOS_URL)
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = raw_input('')
release_file = BASE_URL + RELEASE + '.txt'
release_scans = get_release_scans(release_file)
file_types = FILETYPES
# download task data
if args.task_data:
print(args.task_data)
if set(args.task_data) & set(TASK_FILES.keys()): # download task data
out_dir = os.path.join(args.out_dir, RELEASE_TASKS)
download_task_data(args.task_data, out_dir)
else:
print('ERROR: Unrecognized task data id: ' + args.task_data)
print('Done downloading task_data for ' + str(args.task_data))
key = raw_input('Press any key to continue on to main dataset download, or CTRL-C to exit.')
# download specific file types?
if args.type:
if not set(args.type) & set(FILETYPES):
print('ERROR: Invalid file type: ' + file_type)
return
file_types = args.type
if args.id and args.id != 'ALL': # download single scan
scan_id = args.id
if scan_id not in release_scans:
print('ERROR: Invalid scan id: ' + scan_id)
else:
out_dir = os.path.join(args.out_dir, RELEASE, scan_id)
download_scan(scan_id, out_dir, file_types)
elif 'minos' not in args.task_data and args.id == 'ALL' or args.id == 'all': # download entire release
if len(file_types) == len(FILETYPES):
print('WARNING: You are downloading the entire MP release which requires ' + RELEASE_SIZE + ' of space.')
else:
print('WARNING: You are downloading all MP scans of type ' + file_types[0])
print('Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.')
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = raw_input('')
out_dir = os.path.join(args.out_dir, RELEASE)
download_release(release_scans, out_dir, file_types)
if __name__ == "__main__": main()

















 5347
5347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









