






首先先进行最基础的特征筛选,剔除掉特征缺失值过大和方差筛选之后的特征值
import pandas as pd
data_path = 'application_train.csv'
data = pd.read_csv(data_path)
# 缺失值比例
missing_percentage = data.isnull().mean() * 100
features_with_less_missing = data.columns[missing_percentage < 30]
reduced_data = data[features_with_less_missing]
variance = reduced_data.var()
features_with_higher_variance = variance[variance > 0.01].index # 方差的阈值为0.01
final_data = reduced_data[features_with_higher_variance]
final_data.to_csv('selected_features_data1.csv', index=False)
print(f"原始特征数量: {data.shape[1]}")
print(f"移除缺失值过多的特征后的数量: {reduced_data.shape[1]}")
print(f"基于方差筛选后的特征数量: {final_data.shape[1]}")得出结果:

然后进行第二步骤,进行相关联度分析
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data_path = 'selected_features_data1.csv'
data = pd.read_csv(data_path)
correlation_matrix = data.corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='coolwarm')
plt.title('Feature Correlation Matrix')
plt.show()得出结果图:
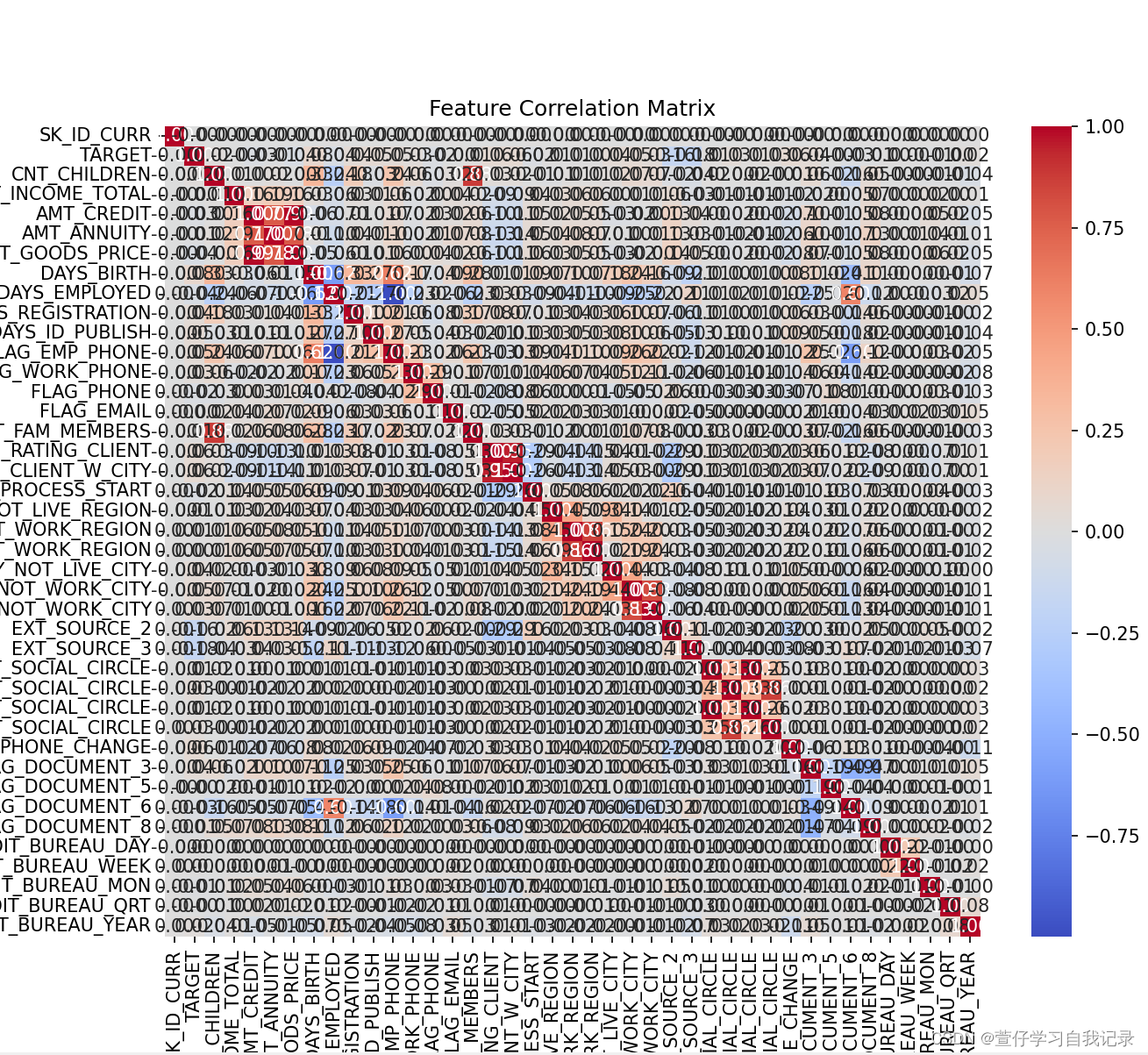
然后进行vif膨胀系数计算
import pandas as pd
from statsmodels.stats.outliers_influence import variance_inflation_factor
data_path = 'selected_features_data1.csv'
data = pd.read_csv(data_path)
data = data.dropna()
# 计算VIF值
vif_data = pd.DataFrame()
vif_data["feature"] = data.columns
vif_data["VIF"] = [variance_inflation_factor(data.values, i) for i in range(data.shape[1])]
# 显示VIF值大于10的特征
print(vif_data[vif_data["VIF"] > 10])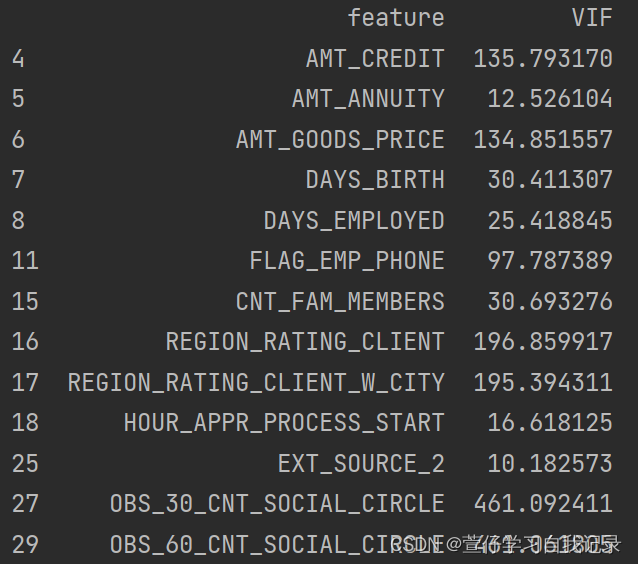
然后进行 lgbm算法对特征重要性进行排序
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
data_path = 'selected_features_data1.csv'
data = pd.read_csv(data_path)
X = data.drop('TARGET', axis=1) # 假设数据中有一个名为'target'的列
y = data['TARGET']
model = lgb.LGBMClassifier()
model.fit(X, y)
importances = model.feature_importances_
feature_names = X.columns
feature_imports = pd.DataFrame({'Feature': feature_names, 'Importance': importances})
feature_imports.sort_values(by='Importance', ascending=False, inplace=True)
feature_imports.to_csv('feature_importance.csv', index=False)
plt.figure(figsize=(12, 8))
sns.barplot(data=feature_imports, x='Importance', y='Feature', palette='viridis')
plt.title('Feature Importances by LightGBM')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.tight_layout()
plt.show()
















 5087
5087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









