







一 FTL算法层的工作内容
SSD(固态硬盘)固件中的FTL(Flash Translation Layer,闪存转换层)算法主要用于管理NAND闪存存储器的数据读写操作。由于NAND闪存在物理特性上有一些限制,比如擦除块才能写入数据、不能直接覆盖已写入的数据等,因此需要一种机制来处理这些复杂性。FTL算法的主要职责包括:
-
地址映射:FTL将主机请求访问的逻辑块地址(LBA)映射到物理块地址(PBA),这样主机无需关心底层闪存的具体物理位置。
-
磨损均衡(Wear Leveling):为了延长闪存的使用寿命,FTL会分散写入操作,使得所有的块都能均匀地承担擦写次数,避免某些块过早失效。
-
垃圾回收(Garbage Collection):当一个块被标记为无效后,FTL会定期进行垃圾回收,清理无效的数据块,合并碎片空间以便新数据可以高效写入。
-
坏块管理(Bad Block Management):闪存中可能会出现坏块,这些块不能用于数据存储。FTL会自动检测并隔离这些坏块,确保它们不会影响正常的数据存储操作。
-
错误校正(Error Correction):FTL还包括了错误校正码(ECC),用于检测和修正数据读取过程中的位错误。
通过上述功能,FTL算法能够有效提高SSD的性能、可靠性和耐用性,同时简化了操作系统与硬件之间的交互。不同的SSD厂商可能采用不同的FTL实现方式,以优化其产品的特定性能指标。
二 BRAM和DRAM的区别
图1:计算机中的存储介质

1 概念
1)DRAM (Dynamic Random Access Memory):
DRAM,也就是 动态随机存储器。DRAM利用电容来存储数据,下电数据就会消失。
2)DDR (Double Data Rate) DRAM
双倍速率DRAM,就是指在每个时钟信号的上下沿都传输一次数据的DDR,传输速率较DDR更快速。
3)SRAM (Static Random Access Memory):
SRAM,静态随机存储器,是一种半导体存储器。它通过多个晶体管组成的锁存器存储数据,因此不需要刷新电路来保存数据。实现成本较高,可以用来实现CPU的L1,L2和L3缓存。
4) BRAM (Block RAM)
BRAM 是FPGA的一种可编辑数据存储器,也是静态存储器。BRAM一般是集成在FPGA或者ASIC(专用集成电路)上的存储器块。 FTL固件工作中用到的BRAM只是一种叫法叫buffer RAM,实际就是SRAM,和Block RAM无关
2 区别
| DRAM | BRAM | |
|---|---|---|
| 存储容量 | 容量较大,可以达到GB级别 | 容量较小,一般是数十KB到数MB之间 |
| 读写速度 | DDR的读写频率现在也可达到几千MHz的水平。DDR4 SDRAM的典型频率可以达到2133 MHz到3200 MHz以上 | 读写速度非常高,可以达到数百MHz的频率,一般较DRAM更快 |
| 访问延迟 | 由于DDR位于外部总线,其访问延迟通常高于BRAM | 访问延迟很低,通常只有几个时钟周期 |
| 功耗 | - - | 由于BRAM不需要像DRAM那样一直刷新电路,因此功耗较DRAM会更低 |
总结:BRAM适合需要高速访问小量数据的应用,而DRAM适用于需要大容量存储的应用。
三 ArmV8内存类型
1 内存类型
Armv8提供了以下互斥的内存类型:
| 类型 | 说明 |
|---|---|
| Normal | Normal 类型的内存通常是可以被缓存的。这意味着数据可以被临时存储在 CPU 缓存(如 L1, L2, L3 等)中,以便快速访问。适用于常规的数据处理任务,例如应用程序代码、用户数据等。 |
| Device | Device 类型的内存通常是不可缓存的。这是因为设备寄存器和其他硬件资源可能需要即时更新,而缓存可能会导致延迟或不一致。用于与硬件设备通信,例如 I/O 操作、DMA(直接内存访问)传输等。这种类型的内存要求低延迟和高一致性,因为它通常涉及到对硬件状态的实时读写。 |
2 Device Memory的属性
Device memory属性有三种,分别是Gathering,Reordering,Early Write Acknowledgement
1) Gathering(聚合)
G 代表具有Gathering属性,nG代表没有Gathering属性。主要用来优化写操作。
含义:Gathering 属性允许将多个较小的写操作合并成一个较大的写操作,从而减少总线上的事务数量。
目的:通过减少写操作的数量,可以降低系统总线的负载,提高总线效率,并可能减少功耗。
应用场景:适用于那些对数据一致性要求不高,但希望通过减少总线事务来优化性能的情况。
2)Reordering(重排序)
含义:Reordering 属性允许硬件重新排列读写操作的顺序,以优化总线利用率或提高性能。
目的:通过允许硬件对访问进行重新排序,可以在某些情况下提高数据传输的效率。例如,如果有一个长延迟的读操作,硬件可能会选择先执行后续的写操作。
应用场景:适用于那些对访问顺序没有严格要求,且可以从重排序中获益的情况。需要注意的是,这可能会导致与程序预期不一致的行为,因此需要谨慎使用。
3)Early Write Acknowledgement (早期写确认, EWA)
含义:Early Write Acknowledgement 允许处理器在实际写入完成之前就收到确认信号。
目的:这样可以减少处理器等待写操作完成的时间,从而提高处理器的效率。
应用场景:适用于那些写操作本身不会立即影响其他操作的情况,或者写操作的结果不需要立即可见的情况。例如,对于一些缓冲区或日志记录的操作,早期确认可以加速处理流程。
3 ARMv8-A 架构中的内存属性
ARMv8-A架构支持八种内存属性(两种Normal Memory,六种Device Memory)。可以在初始化页表时如何指定不同内存区域的属性,通过MAIR_EL3(Memory Attribute Indirection Register at Exception Level 3)寄存器。每组内存属性可以包含不同的特性,如缓存策略、写策略和共享性等。
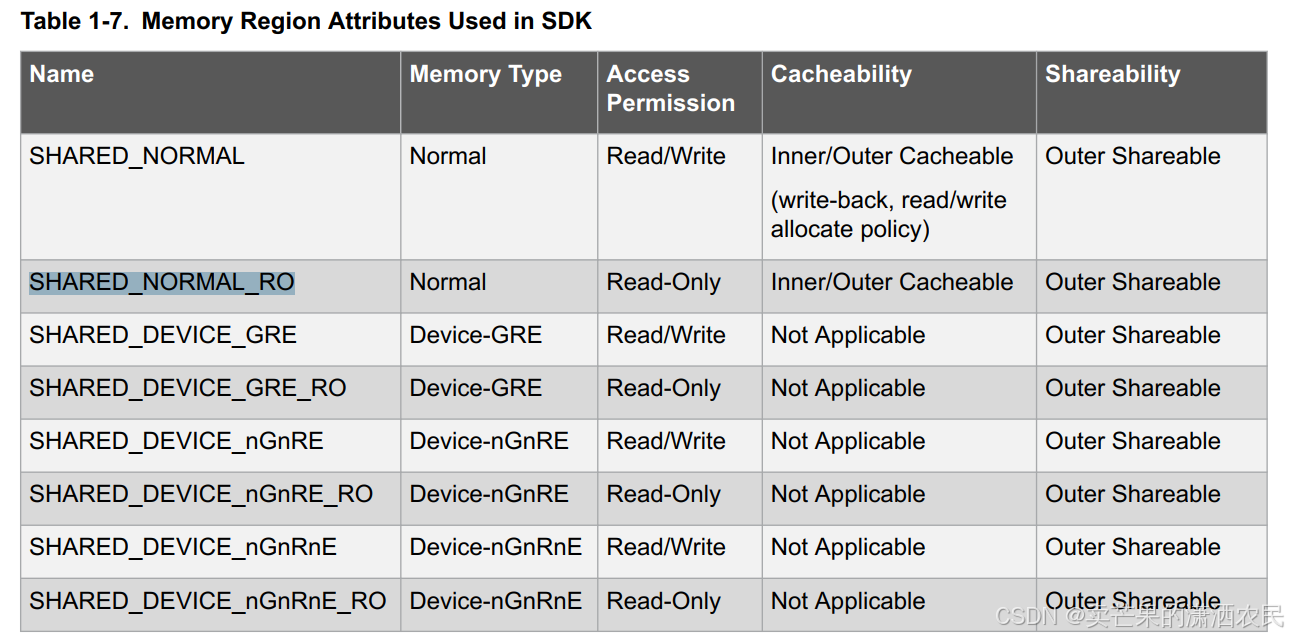
图1 32bit地址空间的内存属性情况(4G)
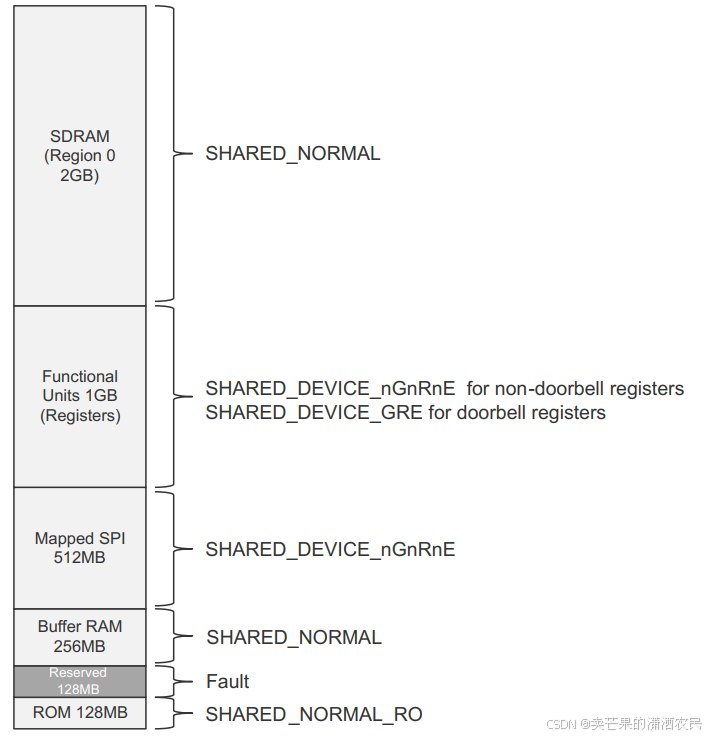
4 SDRAM Memory Map
设备理论上可以支持512GiB的SDRAM (40bit地址时)。
注意GiB是指1024为进制的单位, GB是以1000 为进制的单位
图2 40bit 地址时的地址空间情况
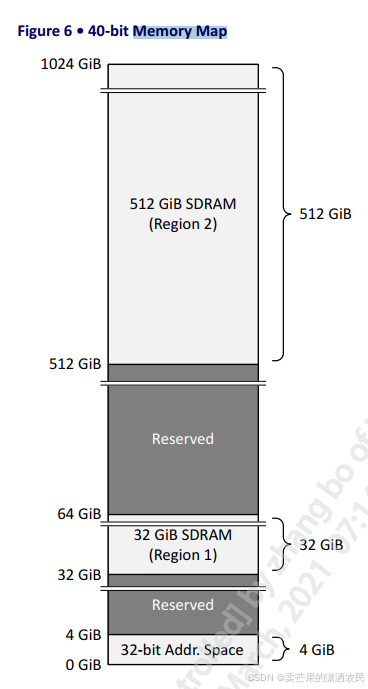
SDRAM一共有3个区域,Region 0,Region 1和 Region 2。分别对应着32bit,36bit和40bit的寻址模式。
| Region 0 | Region 1 | Region 2 | |
|---|---|---|---|
| 地址 | 32 bit | 36 bit | 40 bit |
| 大小 | 512 G | 32 G | 2 G |
| 地址 | 0x 8000_0000 0x FFFF_FFFF | 0x 8_0000_0000 0x F_FFFF_FFFF | 0x 80_0000_0000 0x FF_FFFF_FFFF |
为了保证兼容性,Region 1的头2G地址 和 Region 0中的2G地址相同。Region2中的头32G地址和Region1中的32G地址相同。
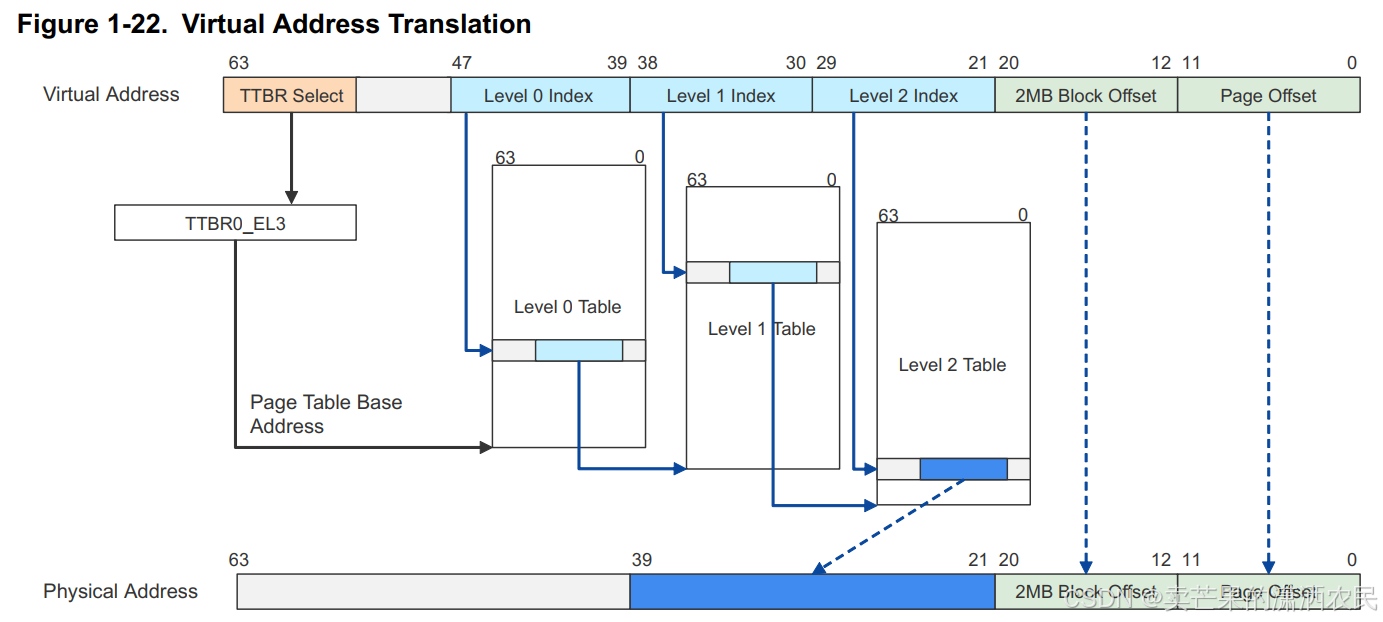
Translation Table Entry在系统初始化时被初始化。SDK用了三级页表,Level 0. Level 1, Level 2;其中Level 2级页表中每条Entry指向2MB的内存空间。每条Entry是64bit,一个Page Table是4K ( 包含512个Entry)。PA是40bit(因为40bit是支持的最大的物理地址)。每个VA是48bit(只占用64 bit中的48 bit)。注意:如果Level 1中的Entry直接指向内存区域(Block),它可以指向一块1GB的空间;或者它可以指向Level 2级别Table的base addr。【图中展示的为Level 1 Entry指向Base Addr】
pageTable.s 中的一条entry的定义是
三 Coherent Memory 和 NonCoherent Memory
内存一致性是指在多处理器系统中,所有处理器对同一内存地址的访问都能看到相同的数据。换句话说,当一个处理器修改了某个内存位置的数据后,其他处理器在访问该位置时能够立即看到最新的数据。
Coherent Network是指在片上网络中,各个处理器核心之间的缓存是一致的。这意味着当一个核心修改了缓存中的数据时,这个变化能够被网络中的其他核心所感知和更新,以保证所有核心看到的是最新的数据。这种网络通常需要复杂的缓存一致性协议来维护数据的一致性,例如MESI(Modified, Exclusive, Shared, Invalid)协议。Coherent Network适用于需要紧密协作和数据共享的多核处理器系统,可以提高系统性能和降低功耗
。

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









