






 Bert与GPT是两种基于Transformer的预训练模型,主要区别在于网络结构和预训练任务。Bert采用Masked Multi-Head Attention,预测被遮蔽的单词,而GPT使用Decoder进行Next Token Prediction。在使用上,Bert通常利用CLS标记进行下游任务,而GPT则可进行One-shot或Zero-shot Learning,无需大量微调。
Bert与GPT是两种基于Transformer的预训练模型,主要区别在于网络结构和预训练任务。Bert采用Masked Multi-Head Attention,预测被遮蔽的单词,而GPT使用Decoder进行Next Token Prediction。在使用上,Bert通常利用CLS标记进行下游任务,而GPT则可进行One-shot或Zero-shot Learning,无需大量微调。
Bert与GPT的区别
1. 网络结构上的区别
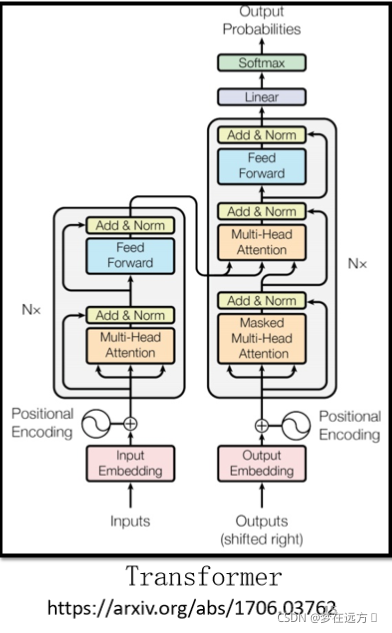
上图是Transformer的一个网络结构图,Bert的网络结构类似于Transformer的Encoder部分,而GPT类似于Transformer的Decoder部分。单从网络的组成部分的结构上来看,其最明显的在结构上的差异为Multi-Head-Attention和Masked Multi-Head-Attention。
为了解释清楚这两个的区别,先来看看self-attention
Self-Attention
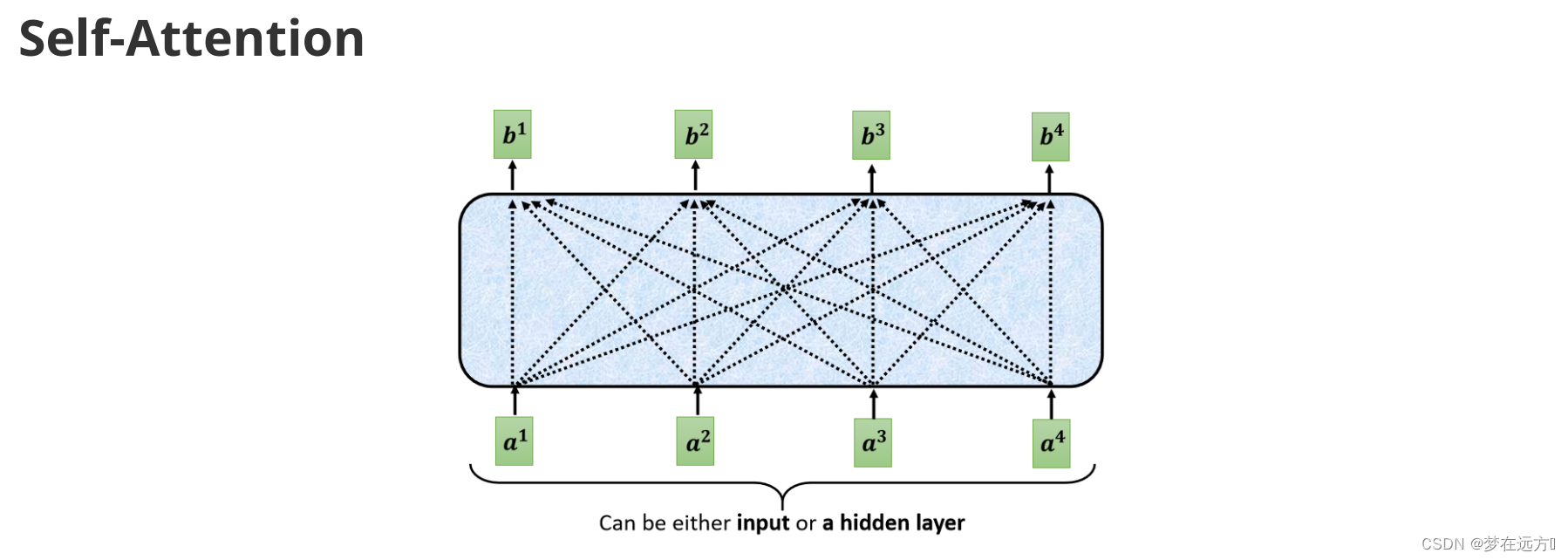
Self-Attention的Input,它就是一串的Vector,我们用 a a a来表示它,代表它有可能是前面已经做过一些处理,它是某个隐藏层的输出,输入一排a这个向量以后,Self-Attention要输出另外一排b这个向量。下面来看看如何输出 b 1 b 2 b 3 b 4 b^1 b^2 b^3 b^4 b1b2b3b4
用最简单的点积方式来计算q为例子:
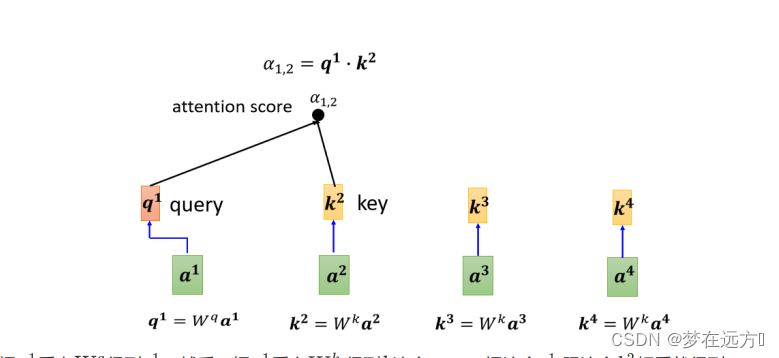
把 a 1 a^1 a1乘上 W q W^q Wq 得到 q 1 q^1 q1,然后,把 a 1 a^1 a1乘上 W k W^k Wk,得到 k k k这个Vector,把这个 q 1 q^1 q1,跟这个 k 2 k^2 k2相乘就得到α
这边用 α 1 , 2 α_{1,2} α1,2来代表说,Query是1提供的,Key是2提供的时候,这个α这个关联性叫做Attention的分数。
接下来也要跟 a 3 a 4 a^3 a^4 a3a4来计算
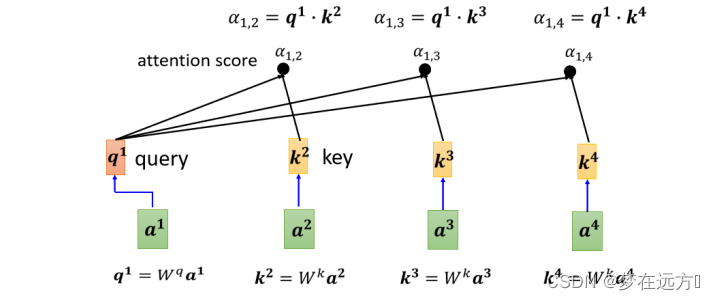
把 a 3 a_3 a3乘上 W k W^k Wk,得到另外一个Key也就是 k 3 k^3 k3, a 4 a^4 a4乘上 W k W^k Wk得到 k 4 k^4 k4,然后再把 k 3 k^3 k3这个Key,跟 q 1 q^1 q1这个Query做Inner-Product,得到1跟3之间的关联性,得到1跟3的Attention,把 k 4 k^4 k4跟 q 1 q^1 q1做点积,得到 α 1 , 4 α_{1,4} α1,4(1跟4之间的关联性)
计算出a1跟每一个向量的关联性以后,接下来这边会接入一个SoftMax
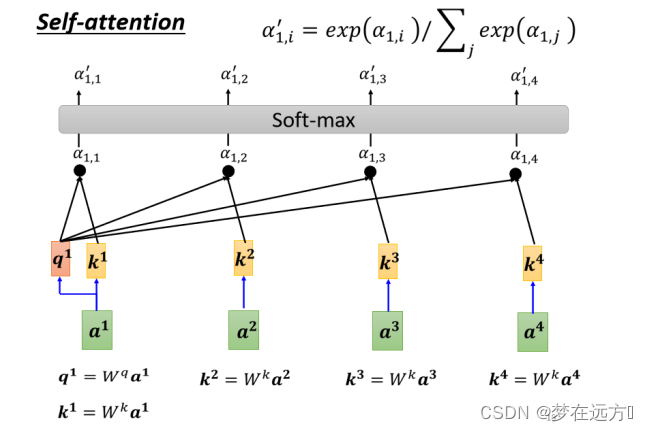
通过Soft-Max就得到 α ′ α' α′
-
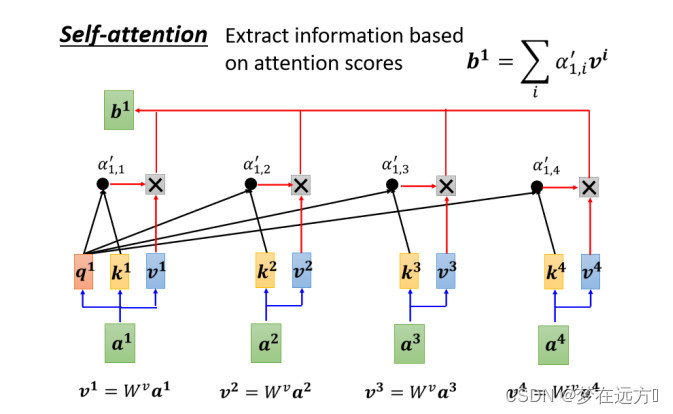
首先把 a 1 a^1 a1到 a 4 a^4 a4这边每一个向量,乘上 W v W^v Wv得到新的向量,这边分别就是用 v 1 v 2 v 3 v 4 v^1 v^2 v^3 v^4 v1v2v3v4来表示
-
接下来把这边的 v 1 v^1 v1到 v 4 v^4 v4,每一个向量都去乘上Attention的分数,都去乘上 α ′ α' α′
-
然后再把它加起来,得到 b 1 b^1 b1
b 1 = ∑ i α 1 , i ′ v i b^1=\sum_i\alpha'_{1,i}v^i b1=i∑α1,i′vi
这就是Self-Attention的过程
Multi-Head-Attention
Self-attention 有一个进阶的版本,叫做 Multi-head Self-attention, 顾名思义,Multi-head Self-attention,相比较于Self-attention自然是使用了较多的head,需要用多少的 head,这个又是另外一个 超参数也是需要调的
为什么会需要比较多的 head 呢?
在做这个 Self-attention 的时候,我们就是用 q 去找相关的 k,但是相关这件事情有很多种不同的形式,有很多种不同的定义,所以也许我们不能只有一个 q,我们应该要有多个 q,不同的 q 负责不同种类的相关性。
其具体操作为(以一个两个head为例):
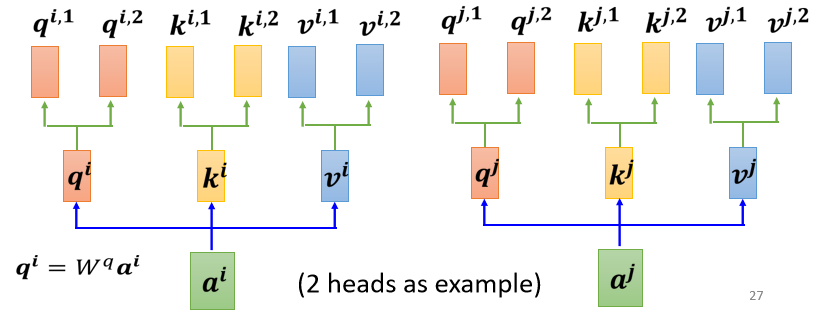
- 先把 a 乘上一个矩阵得到 q
- 再把 q 乘上另外两个矩阵,分别得到 q 1 q^1 q1 跟 q 2 q^2 q2,那这边还有 这边是用两个上标,i 代表的是位置,然后这个 1 跟 2 代表是,这个位置的第几个 q,所以这边有 q i , 1 q^{i,1} qi,1 跟 q i , 2 q^{i,2} qi,2,代表说我们有两个 head
既然 q 有两个,那 k 也就要有两个,那 v 也就要有两个,从 q 得到 q 1 q 2 q^1 q^2 q1q2,从 k 得到 k 1 k 2 k^1 k^2 k1k2,从 v 得到 v 1 v 2 v^1 v^2 v1v2,那其实就是把 q 把 k 把 v,分别乘上两个矩阵,得到这个不同的 head。
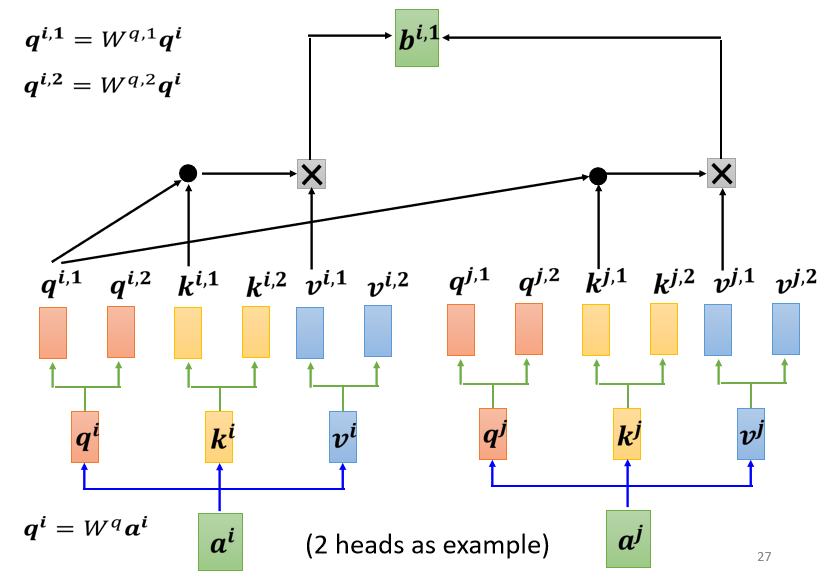
- 所以 q i , 1 q_{i,1} qi,1 就跟 k i , 1 k^{i,1} ki,1 算 attention
- q i , 1 q_{i,1} qi,1 就跟 k j , 1 k^{j,1} kj,1 算 attention,也就是算这个点积,然后得到这个 attention 的分数
- 把 attention 的分数乘 v i , 1 v^{i,1} vi,1,把 attention 的分数乘 v j , 1 v^{j,1} vj,1
- 然后接下来就得到 b i , 1 b^{i,1} bi,1
这边只用了其中一个 head,对于另一个 head,也做一模一样的事情
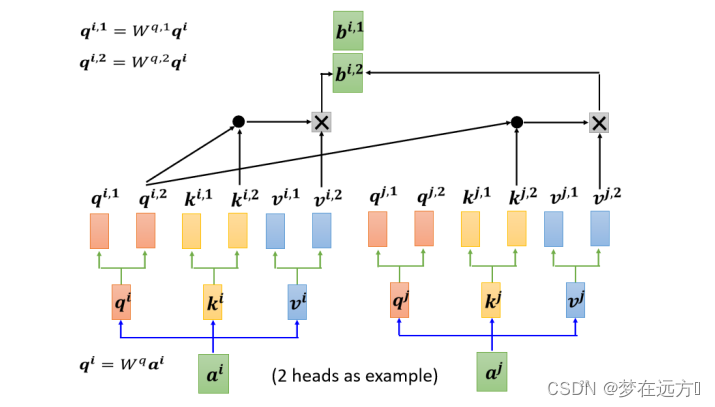
所以 q 2 q^2 q2 只对 k 2 k^2 k2 做 attention,它们在做 weighted sum 的时候,只对 v 2 v^2 v2 做 weighted sum,然后就得到 b i , 2 b^{i,2} bi,2
如果有多个 head,有 8 个 head 有 16 个 head,那也是一样的操作,那这边是用两个 head 来当作例子
然后把 b i , 1 b^{i,1} bi,1 跟 b i , 2 b^{i,2} bi,2,把它接起来,然后再通过一个 transform
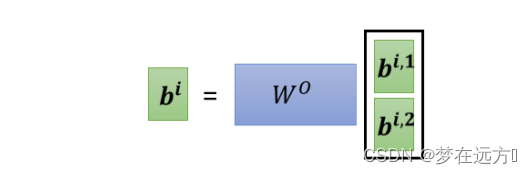
也就是再乘上一个矩阵,然后得到 bi,然后再送到下一层去,那这个就是 Multi-head attention
Masked Multi-Head-Attention
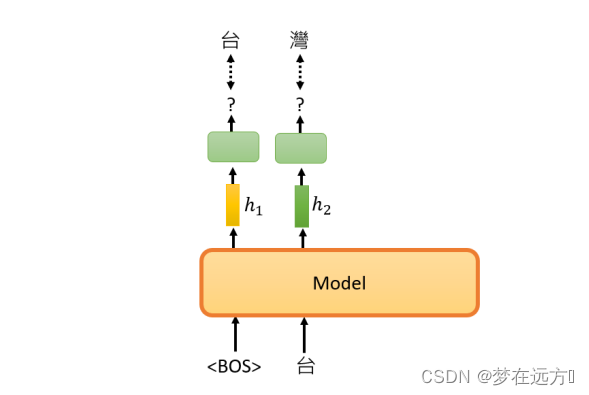
使用mask的原因是因为在预测句子的时候,当前时刻是无法获取到未来时刻的信息的。也就是Multi-Head-Attention可以看到Input的整个句子,而Masked Multi-Head-Attention只能看到当前输入之前的内容,无法看到之后的内容
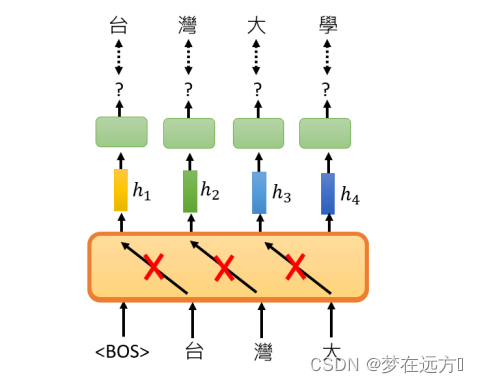
例如,在本例子中,输入的时候,不会看到后面的信息,输入台的时候,我们也没法看到“湾大学”的字样。这就是Masked Multi-Head-Attention和Multi-Head-Attention的主要区别。
2.预训练任务区别
在Bert与GPT的预训练任务的选取上,Bert与GPT所用的模型也存在着较大的差异。
Bert——Masking Input
在Bert的预训练任务中,Bert主要使用“填空题"的方式来完成预训练:
随机盖住一些输入的文字,被mask的部分是随机决定的,当我们输入一个句子时,其中的一些词会被随机mask。
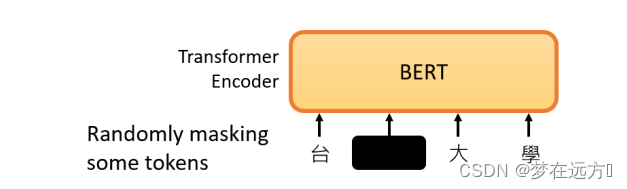
mask的具体实现有两种方法。
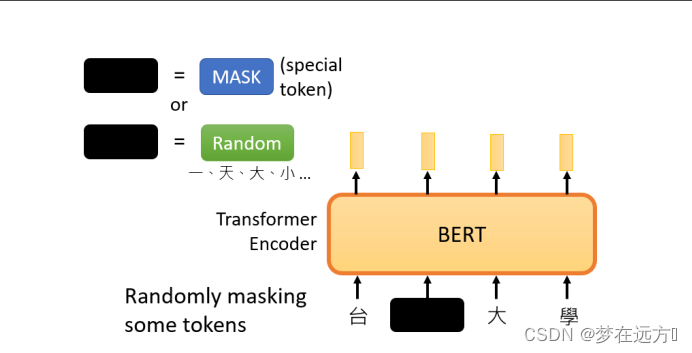
- 第一种方法是,用一个特殊的符号替换句子中的一个词,我们用 "MASK "标记来表示这个特殊符号,可以把它看作一个新字,这个字完全是一个新词,它不在字典里,这意味着mask了原文。
- 另外一种方法,随机把某一个字换成另一个字。中文的 "湾"字被放在这里,然后可以选择另一个中文字来替换它,它可以变成 "一 "字,变成 "天 "字,变成 "大 "字,或者变成 "小 "字,我们只是用随机选择的某个字来替换它
两种方法都可以使用。使用哪种方法也是随机决定的。因此,当BERT进行训练时,向BERT输入一个句子,先随机决定哪一部分的汉字将被mask。
mask后,一样是输入一个序列,我们把BERT的相应输出看作是另一个序列,接下来,我们在输入序列中寻找mask部分的相应输出,然后,这个向量将通过一个Linear transform,输入向量将与一个矩阵相乘,然后做softmax,输出一个分布。。
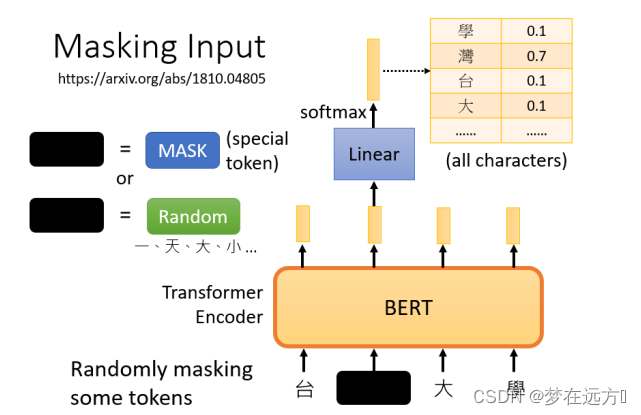
这与我们在Seq2Seq模型中提到的使用transformer进行翻译时的输出分布相同。输出是一个很长的向量,包含我们想要处理的每个汉字,每一个字都对应到一个分数。
在训练过程中。我们知道被mask的字符是什么,而BERT不知道,我们可以用一个one-hot vector来表示这个字符,并使输出和one-hot vector之间的交叉熵损失最小。
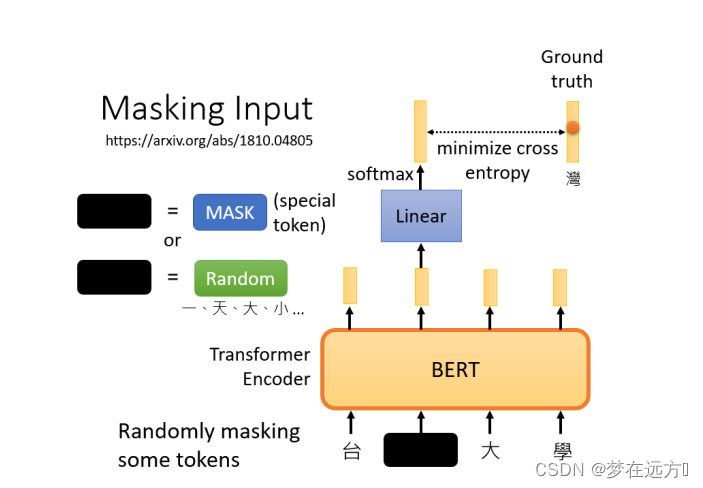
BERT要做的是,预测什么被盖住。被掩盖的字符,属于 "湾"类。
在训练中,我们在BERT之后添加一个线性模型,并将它们一起训练,尝试去预测被覆盖的字符是什么。
GPT——Predict Next Token
GPT要做的任务是,预测接下来,会出现的token是什么
举例来说,假设训练资料里面,有一个句子是台湾大学,那GPT拿到这一笔训练资料的时候,选取BOS这个Token所对应的输出,作为Embedding的结果,用这个embedding去预测下一个应该出现的token是什么
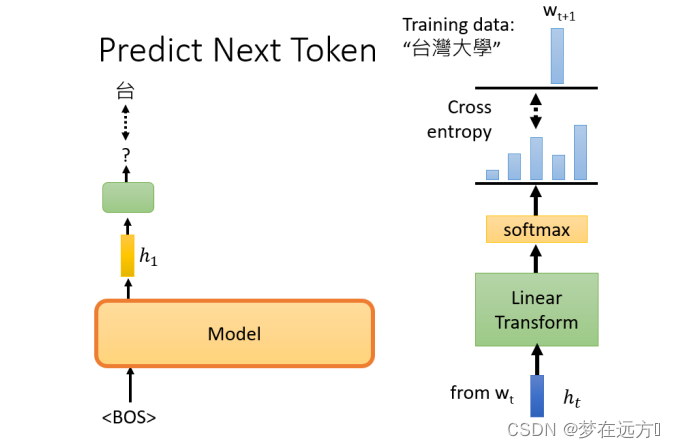
那在这个句子里面,根据这笔训练资料,下一个应该出现的token是"台",要训练模型,根据第一个token,根据BOS给的embedding,那它要输出"台"这个token
这个部分,有一个embedding,这边用h来表示,然后通过一个Linear Transform,再通过一个softmax,得到一个概率分布,我们希望这个输出的概率分布,跟正确答案的交叉熵越小越好。
接下来要做的事情,就是以此类推了,输入BOS跟"台",它产生embedding,接下来它会预测,下一个出现的token是什么,以此类推来训练模型。
3.使用方法的区别
对于Bert和GPT,其本意是提供一个预训练模型,使得人们可以方便的将其运用于下流(downstream)任务当中去。当然,这两种模型最后使用的方法也是有一些区别的。
Bert的使用方法——以情感分类为例
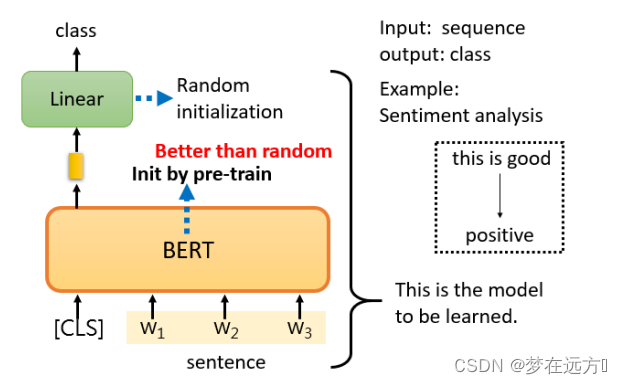
只要给它一个句子,也就是你想用它来判断情绪的句子,然后把CLS标记放在这个句子的前面,扔到BERT中,这4个输入实际上对应着4个输出。然后,我们只看CLS的部分。CLS在这里输出一个向量,我们对它进行Linear transform,也就是将它乘以一个Linear transform的矩阵,然后进行Softmax,就可以得到情感分类的结果。
Bert的使用大多如此,用CLS对应的Output作为Embedding的结果,然后根据不同的任务进行对应的操作来fine-turing,从某方面而言,更像是利用深度学习对文本进行特征表示的过程。
GPT的使用方法
对于GPT使用,由于GPT的参数是Bert的4倍有余,使得去fine-turing一个模型需要更长,更大的训练时间。因此GPT提出了一个更加“疯狂”的使用方式,一种更接近于人类的使用方式。
没有进行梯度下降的"Few short leaning",也就GPT论文所提到的“In-context learning”
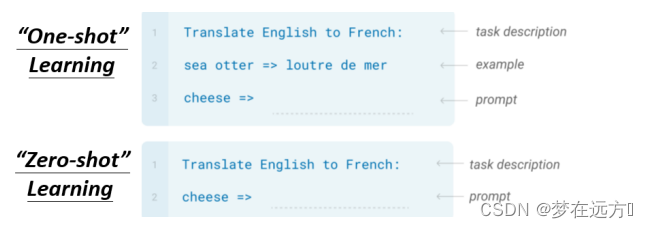
举例来说假设要GPT这个模型做翻译

- 先打Translate English to French,这个句子代表问题的描述
- 然后给它几个范例
- 最后接下来给一个Cheese的词,让他翻译成法语。
“One-shot” Learning “Zero-shot” Learning
例如我们在考听力测验的时候,都只给一个例子而已,那GPT可不可以只看一个例子,就知道它要做翻译,这个叫One-shot Learning
还有更厉害的是Zero-shot Learning,直接给它一个叙述,说现在要做翻译了,来看GPT能不能够自己就看得懂,就自动知道说要来做翻译这件事情。
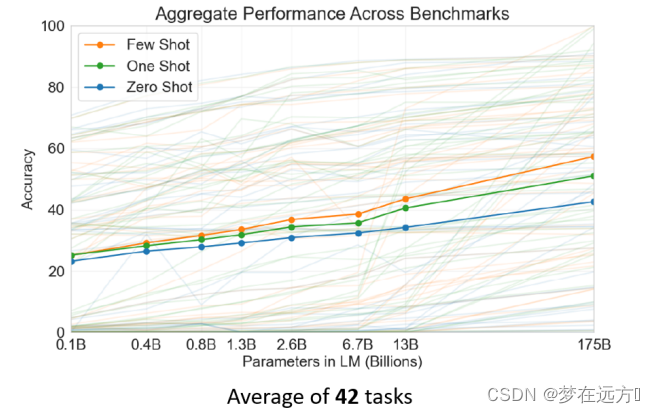
GPT在没有微调的情况下,这种使用方法虽然准确率不够高,但是随着GPT参数量的增加,在一定程度上仍然有着一定的准确率。
这就是GPT相比较于Bert更加独特的一种使用方式。

















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









