






近些年来,基于transfome模型的各种自注意力机制的模型层出不穷,因此我想要认真学习一下transformer模型,以便更好的对各种基于自注意力以及encoder-decoder架构的模型进行分析与理解。本文将从以下几个部分进行介绍:
1、Transformer总体介绍
2、输入Embedding与位置编码Positional Encoding
3、残差连接、Layer Normalization
4、encoder部分
5、decoder部分
6、总结
1、Transformer总体介绍与直观认识
Transformer模型主要分为两大部分,分别为6层Encoder与6层Decoder,(但是一般为了简化描述,都只展示了一层Encoder与一层Decoder)。总体来看,Encoder主要负责将输入(也就是自然语言的序列)映射成为对应的隐藏层,然后Decoder则把隐藏层映射成为对应的自然语言序列。对于模型的总体输入需要注意一下(结合下面的总体结构图),Encoder以及Decoder均有输入信息,可以看到,encoder部分的输入是源文本的Embeddings(嵌入向量)以及对应的位置编码、而Decoder的输入部分则是目标文本的Embeddings(嵌入向量)以及对应的位置编码。transformer的总体结构如下: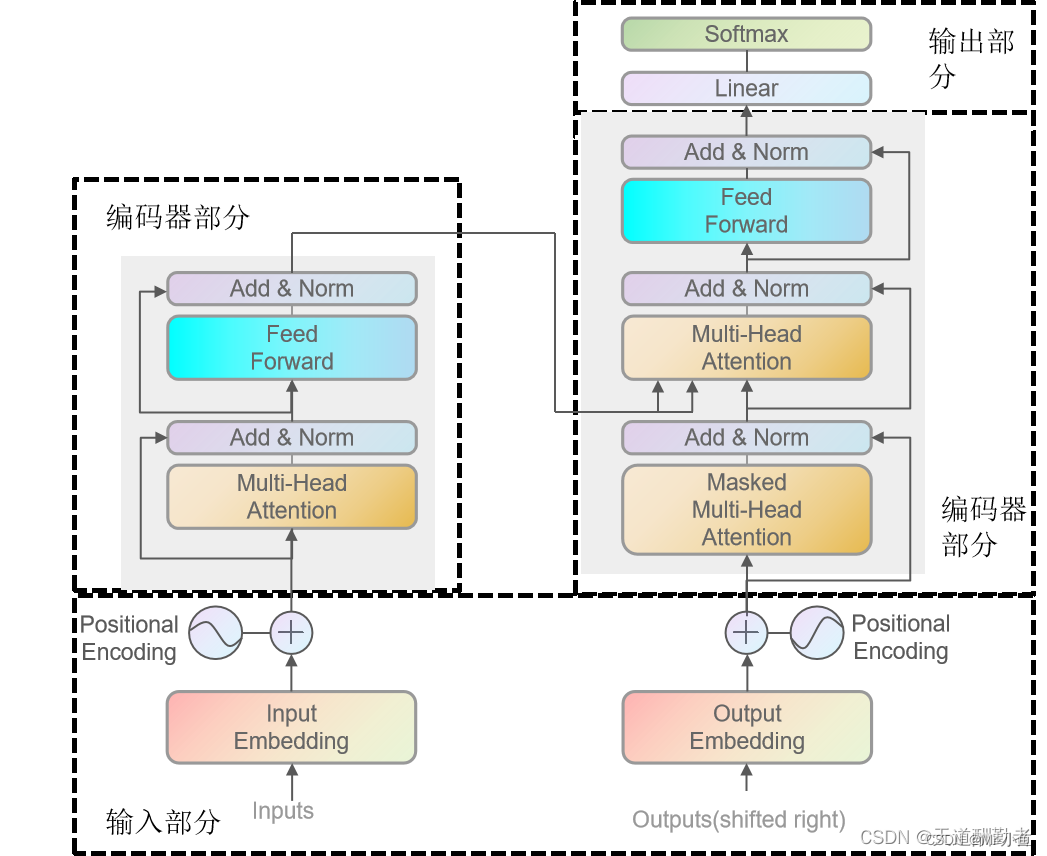 相信通过上面这个图,如果大家只是刚开始了解transformer,那一定还有很多的困惑的点,比如:
相信通过上面这个图,如果大家只是刚开始了解transformer,那一定还有很多的困惑的点,比如:
1、Input Embedding是什么,怎么嵌入成向量的?
2、位置编码又是什么?怎么进行编码得呢?
3、Multi-Head Attention怎么实现的?有什么好处呢?Add&Norm这个又是啥?具体又是什么相加?归一化?
4、Feed ForWard 又是啥?前馈?
5、经过6层Encoder输出的又是啥?怎么连接到了Decoder那个架构部分?
6、Decoder的Masked Multi-Head Attention(中文为掩码多头自注意力机制)是啥?有什么用?
6、输出部分的Linear、softmax这个又是对Decoder的操作进行了怎样的操作?
刚开始了解这个transformer架构时,相信大家过多或少都会具有一定的疑问,其中不乏我提到的那些问题。因此我将仔细介绍这个transformer的各个部分,并着重让大家理解,以解决我刚刚列出来的那些疑问。
2、输入Embedding与位置编码Positional Encoding
2.1 输入Embedding
以机器翻译为例,对于transformer中的输入Embedding部分,进行讲解。
首先对于机器翻译而言,一个输入样本是由原始句子和翻译后的句子组成的,比如原始句子“我爱吃苹果”,对应翻译句子为“i love eating apples"。输入样本就是由”我爱吃苹果“和”i love eating apples“组成。
这个样本的原始句子”我爱吃苹果“的单词长度为4,即为“我”,“爱”,“吃”,“苹果”,经过输入的embedding之后,每个词也就变成向量了,向量大小为512,(向量大小为512是transformer原始模型这样设置得,实际上自己也可以修改大小),那么“我爱吃苹果”这个句子的embedding后的维度为(4,512)。而对于实际情况下的的模型输入,一般会批量进行输入并处理,也就是每一次选择多个句子进行处理。比如每一次20个句子。(这里就有batch (n. 一组;一批)的概念了,batch或者batchsize用来描述每一次训练的样本句子数量,以后很多时候的模型训练都会见到用batchsize或者batch述每次处理多少样本数)。这样的话,一个batchsize的句子输入并emdedding,得到的向量维度为(batchsize,句子单词长度,512)。
而有时候一个句子的长度并不统一,有些句子长度为20,有些句子长度为4等等,并不统一。因此需要规定一个默认最大句子长度。如果一个句子达不到默认最大句子的长度,那就将该句子补充空白字符,以达到默认句子长度,便于统一处理。比如,我规定最大句子长度为20,那么”我爱吃苹果“则需要补充14个空白,又称作padding。如此之后,每个句子经过输入Embedding就都统一了向量大小(20,512),而j句子中补的空白对应的Embedding数值就是0啦,实际上在模型中的展示也只是输入embedding中补充的对应的数值全为0的向量而已。
若规定最大句子长度为20,以”我爱吃苹果”这个句子为例,需要补全16个空白,则它嵌入的向量形式是这样的,后面16个512维的向量值均为0值:
521列:
1 2 3 4 5 … 512
12 12 24 34 42 … 44
14 12 23 34 42 … 44
12 12 27 34 42 … 44
4 12 3 34 42 … 44
0 0 0 0 0 … 0
0 0 0 0 0 … 0
… … … … … … …
0 0 0 0 0 … 0
此外,对于输入序列一般要进行padding补齐,也就是说设定一个统一长度N,在较短的序列后面填充0到长度为N。对于那些补零的数据来说,attention机制不应该把注意力放在这些位置上,所以需要进行一些处理。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样经过softmax后,这些位置的权重就会接近0。Transformer的padding mask实际上是一个张量,每个值都是一个Boolean,值为false的地方就是要进行处理的地方。
2.2 位置编码Positional Encoding
当我们将输入的一个个句子嵌入成向量之后,如果将它们直接输入到encoder中,那就会造成没有考虑到句子中的位置顺序关系的。为什么要考虑位置关系呢?这肯定是因为序列的顺序也是很重要的信息,特别是机器翻译等任务,我们对句子“我爱吃苹果”进行翻译时,不能胡乱颠倒顺序翻译啊,也不能忽略语义的前后关联啊。这也足以说明序列的顺序很重要的,有信息可以挖掘的。因此为了能够考虑到句子中的位置顺序关系,transformer模型为每个输入的词嵌入向量添加了额外的一个位置编码Positional Encoding向量。这些向量遵循模型学习的特定模式,有助于模型确定每个词的位置,或序列中不同词之间的距离。其核心思想是在attention计算时提供有效的距离信息。
接下来好好定义一个位置嵌入的概念,也就是 Positional Encoding,位置嵌入的维度为 [最大序列长度max_sequence_length, 嵌入向量维度embedding_dimension=512], 位置嵌入向量的维度与词嵌入向量的维度是相同的,都是 embedding_dimension=512。max_sequence_length 属于超参数,也就是上文中提到过的最大句子长度这个概念,限定每个句子最长由多少个词构成。
论文中使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
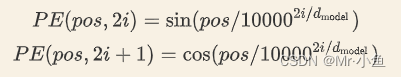
上式中 pos 指的是一句话中某个字的位置,取值范围是[0,max_sequence_length),i 指的是字向量的维度序号,取值范围是[0,embedding_dimension/2),d_model指的是 embedding_dimension的值。
为啥给序列中的词按照这种公式设计位置嵌入向量呢?点击这个链接的介绍就比较清楚了。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









