









🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
K-means++: 一种改进的聚类算法详解
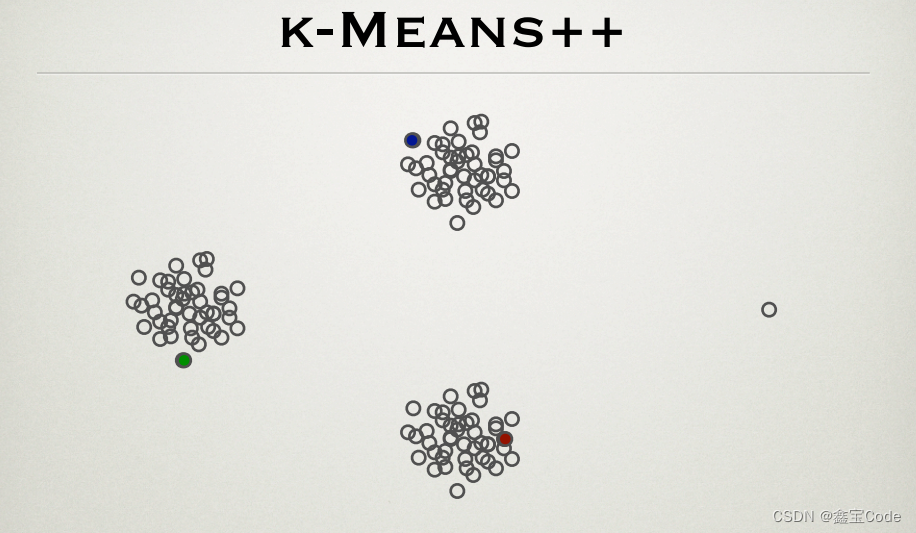
引言
在数据分析与机器学习领域,聚类算法作为无监督学习的重要组成部分,被广泛应用于数据分组、模式识别和数据挖掘等场景。其中,K-means算法以其简单直观和高效的特点,成为最常用的聚类方法之一。然而,经典K-means算法在初始聚类中心的选择上存在随机性,可能导致算法陷入局部最优解。为解决这一问题,2007年,David Arthur 和 Sergei Vassilvitskii 提出了K-means++算法,它通过一种智能化的初始化策略显著提高了聚类质量。本文将深入探讨K-means++算法的原理、优势、实现步骤以及实际应用案例,旨在为读者提供一个全面且易于理解的K-means++算法指南。
1. K-means算法回顾

1.1 基本概念
K-means算法的目标是将数据集划分为K个簇(clusters),每个簇由距离其质心(centroid)最近的数据点组成。算法迭代执行以下两个步骤直至收敛:
- 分配步骤:将每个数据点分配给最近的质心。
- 更新步骤:重新计算每个簇的质心,即该簇所有点的均值。
1.2 局限性
- 对初始质心敏感:随机选择的初始质心可能导致算法陷入局部最优解。
- 不适合处理不规则形状的簇:倾向于形成球形或凸形簇。
- 难以处理大小和密度变化较大的簇。
2. K-means++算法介绍
2.1 初始质心选择策略
K-means++算法的核心改进在于其初始化过程,具体步骤如下:
- 从数据集中随机选择第一个质心。
- 对于每个数据点
x,计算其到已选择的所有质心的最短距离D(x)。 - 选择一个新的数据点作为下一个质心,选择的概率与
D(x)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











