









按需Slot下载数据集

标记
GOCI-II数据集下载脚本
运行批量下载脚本
数据集网站:
https://nosc.go.kr/opendap/hyrax/GOCI-II/
🌺 有批量下载数据集的需求,可以直接python运行脚本
import os
import requests
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
from urllib.parse import urljoin
# 基础URL路径,指向GOCI-II数据的根目录
base_url = "https://nosc.go.kr/opendap/GOCI-II"
# 本地保存文件的目录,确保所有下载的文件存放到该文件夹中
output_folder = "GOCI_Downloads"
# 创建本地文件夹,如果文件夹不存在,则创建
os.makedirs(output_folder, exist_ok=True)
# 定义下载的日期范围,开始日期和结束日期
start_date = datetime(2021, 1, 1) # 起始日期
end_date = datetime(2021, 1, 31) # 结束日期
# 定义要下载的槽位列表
slots = ["S007", "S010"] # 槽位 7 和槽位 10
# 定义产品类型
product = "TSS" # 表示 Total Suspended Solids
# 定义文件下载的函数,增加重试机制
def download_file(file_url, local_file_path, retries=5, timeout=120):
"""
尝试从指定URL下载文件,并保存到本地路径。支持多次重试和超时设置。
:param file_url: 文件的远程URL
:param local_file_path: 本地保存文件的路径
:param retries: 下载失败时的最大重试次数
:param timeout: 单次请求的超时时间(秒)
:return: 下载成功返回 True,否则返回 False
"""
for attempt in range(retries): # 循环指定的重试次数
try:
# 发起HTTP GET请求下载文件,设置超时时间
response = requests.get(file_url, stream=True, timeout=timeout)
response.raise_for_status() # 检查请求是否成功
# 将文件内容保存到本地路径
with open(local_file_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192): # 分块读取文件内容
file.write(chunk)
print(f"已保存:{local_file_path}")
return True # 下载成功
except requests.exceptions.RequestException as e:
# 打印错误信息,并记录当前尝试次数
print(f"下载失败 {file_url}(尝试 {attempt + 1}/{retries}):{e}")
if attempt + 1 == retries: # 如果达到最大重试次数,打印失败信息
print(f"文件 {file_url} 在多次尝试后仍然失败。")
return False # 下载失败
# 遍历日期范围
current_date = start_date
while current_date <= end_date:
# 格式化日期信息,用于构建URL路径
year = current_date.strftime("%Y")
month = current_date.strftime("%m")
day = current_date.strftime("%d")
date_str = current_date.strftime("%Y%m%d")
# 构建日期目录的URL
date_url = f"{base_url}/{year}/{month}/{day}/L2/"
try:
print(f"访问日期目录:{date_url}") # 打印正在访问的日期目录URL
response = requests.get(date_url, timeout=30) # 请求日期目录的网页内容
response.raise_for_status() # 检查请求是否成功
soup = BeautifulSoup(response.text, "html.parser") # 解析网页内容为HTML
# 查找所有子文件夹链接,链接以 "GK2" 开头
subdirs = [
link.get("href") for link in soup.find_all("a")
if link.get("href") and link.get("href").startswith('GK2')
]
# 遍历每个子文件夹
for subdir in subdirs:
subdir_url = urljoin(date_url, subdir) # 构建完整的子文件夹URL
try:
print(f"访问子目录:{subdir_url}") # 打印正在访问的子目录URL
subdir_response = requests.get(subdir_url, timeout=30) # 请求子目录网页内容
subdir_response.raise_for_status() # 检查请求是否成功
subdir_soup = BeautifulSoup(subdir_response.text, "html.parser") # 解析网页内容
# 查找所有文件链接,文件名以 ".nc" 结尾
files = [
link.get("href") for link in subdir_soup.find_all("a")
if link.get("href") and link.get("href").endswith('.nc')
]
# 遍历匹配的文件名
for file_name in files:
if "_LA_" in file_name and date_str in file_name: # 检查文件名中包含日期和"_LA_"
for slot in slots:
if f"_{slot}_" in file_name and f"_{product}.nc" in file_name:
# 构建完整的文件URL
file_url = urljoin(subdir_url, file_name)
if "viewers" in file_url: # 跳过无效的查看器链接
print(f"跳过无效的查看器链接:{file_url}")
continue
# 构建本地保存路径,确保文件夹存在
local_file_folder = os.path.join(output_folder, year, month, day, slot)
os.makedirs(local_file_folder, exist_ok=True)
local_file_path = os.path.join(local_file_folder, file_name)
# 下载文件
print(f"正在下载:{file_url}")
download_file(file_url, local_file_path)
break # 找到匹配文件后跳出槽位循环
except requests.exceptions.RequestException as e:
print(f"无法访问子目录 {subdir_url}:{e}") # 捕获子目录访问失败的错误
except requests.exceptions.RequestException as e:
print(f"无法访问日期目录 {date_url}:{e}") # 捕获日期目录访问失败的错误
# 日期加一天
current_date += timedelta(days=1)
print("所有指定的文件已下载完成!") # 打印下载完成的提示
🍕直接可以下载需要的数据,实现自动批量下载
🎂根据自己的实际需要修改变量名称、时间、slot
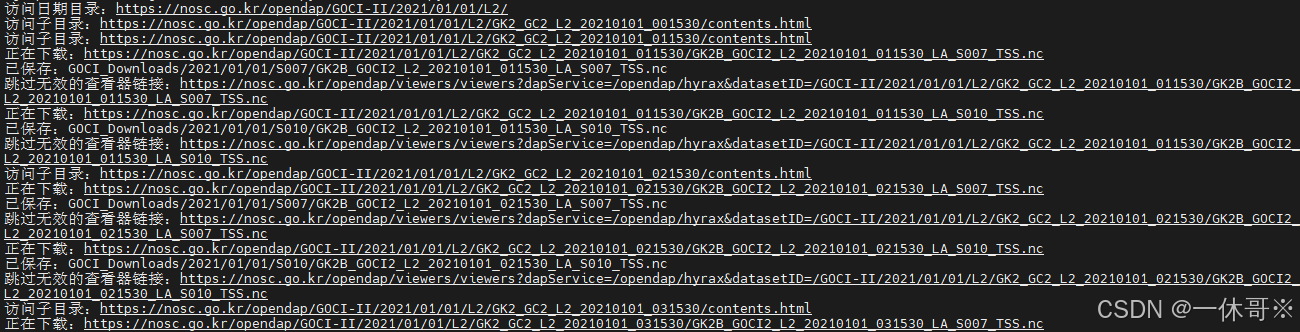
下载结果
命令下载后输出的结果图



















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











