







 文章提出了一种新的注意力机制RFA,用于解决卷积核参数共享问题。RFAConv是一种考虑感受野特征的卷积操作,能提高网络性能,且计算成本和参数增量微小。在ImageNet-1k、MSCOCO和VOC数据集上的实验显示,RFAConv在分类、物体检测和语义分割等任务中表现优越。
文章提出了一种新的注意力机制RFA,用于解决卷积核参数共享问题。RFAConv是一种考虑感受野特征的卷积操作,能提高网络性能,且计算成本和参数增量微小。在ImageNet-1k、MSCOCO和VOC数据集上的实验显示,RFAConv在分类、物体检测和语义分割等任务中表现优越。
即插即用新的注意力机制RFAConv
一、 前言
空间注意力已被广泛用于提高卷积神经网络的性能,使其能够专注于重要信息。然而,它有一定的局限性。在本文中,我们对空间注意的有效性提出了一个新的观点,那就是它可以解决卷积核参数共享的问题。尽管如此,由空间注意产生的注意图中所包含的信息对于大尺寸卷积核来说是不够的。因此,我们引入了一种新的注意机制,称为感受场注意(RFA)。虽然以前的注意机制,如卷积块注意模块(CBAM)和协调注意(CA)只关注空间特征,它们不能完全解决卷积核参数共享的问题。相比之下,RFA不仅关注感受野空间特征,而且还为大尺寸卷积核提供有效的注意力权重。由RFA开发的感受野注意卷积操作(RFAConv)代表了一种取代标准卷积操作的新方法。它提供了几乎可以忽略不计的计算成本和参数的增加,同时显著提高了网络性能。我们在ImageNet-1k、MS COCO和VOC数据集上进行了一系列的实验,证明了我们的方法在各种任务中的优越性,包括分类、物体检测和语义分割。特别重要的是,我们认为现在是时候将重点从空间特征转移到当前空间注意机制的接受场空间特征上了。通过这样做,我们可以进一步提高网络性能,取得更好的结果。
1. 解决问题
通过研究卷积运算的内在限制和注意力机制的特性注意机制,我们认为,虽然目前的空间注意机制已经从根本上解决了卷积运算中的参数共享问题、但它仍然局限于对空间特征的识别。目前的空间注意机制并没有完全解决较大的卷积运算的参数共享问题。内核。此外,它们无法强调每个特征在接受领域中的重要性。如现有的卷积块注意模块(CBAM)[17]和协调注意(CA)[18]。因此,我们引入了一种新的感受野注意机制(RFA),全面解决了卷积核的参数共享问题。
卷积核的参数共享问题,并考虑到每个特征在感受野中的重要性。场的重要性。RFA设计的卷积操作(RFAConv)是一种突破性的方法
它可以取代目前神经网络中的标准卷积操作。只需额外的几个参数和计算开销,RFAConv就能提高网络性能。
RFAConv: Innovating Spatital Attention and Standard Convolutional Operation
2.RFAConv原理
最近的研究表明,交互信息可以提高网络性能、如[40, 41, 42]所示。同样地,对于,RFAConv来说,交互接受场特征信息来学习注意力图,可以提高网络性能。然而,与每个感受野特征进行交互会导致额外的计算开销。为了尽量减少计算开销和参数数量为了最大限度地减少计算开销和参数数量,
AvgPool被用来汇总每个接收场特征的全局信息。每个感受野特征的全局信息。然后,使用1×1组卷积运算来交互信息。最后,我们使用softmax来强调重要性。
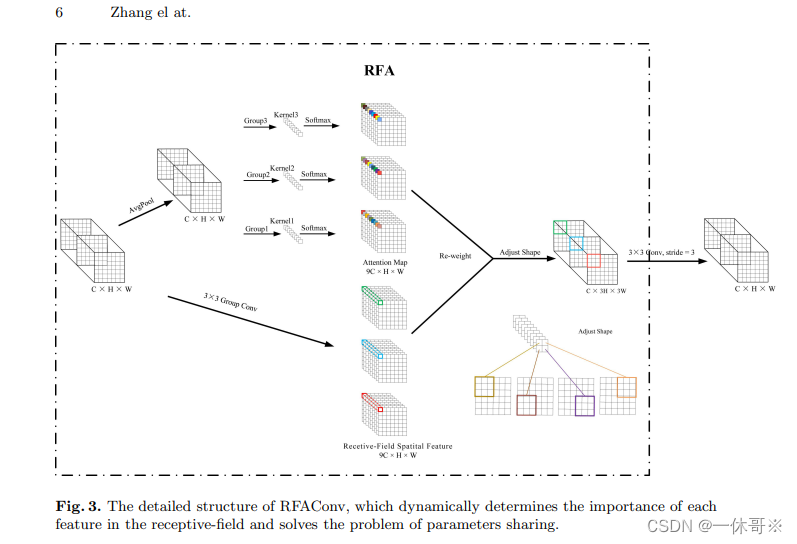
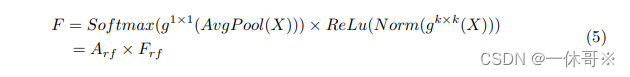
二、添加方法
#RFA exp start********************************
class CAConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride, reduction=32):
super(CAConv, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv = nn.Sequential(nn.Conv2d(inp, oup, kernel_size, padding=kernel_size // 2, stride=stride),
nn.BatchNorm2d(oup),
nn.ReLU())
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return self.conv(out)
class CBAMConv(nn.Module):
def __init__(self, channel, out_channel, kernel_size, stride, reduction=16, spatial_kernel=7):
super().__init__()
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
self.spatital = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
self.conv = nn.Sequential(nn.Conv2d(channel, out_channel, kernel_size, padding=kernel_size // 2, stride=stride),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.spatital(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return self.conv(x)
class CAMConv(nn.Module):
def __init__(self, channel, out_channel, kernel_size, stride, reduction=16, spatial_kernel=7):
super().__init__()
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
self.conv = nn.Sequential(nn.Conv2d(channel, out_channel, kernel_size, padding=kernel_size // 2, stride=stride),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
return self.conv(x)
#RFA exp start********************************
v5yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, CAConv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, CAConv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, CAConv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, CAConv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, CAConv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, CAConv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, CAConv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, CAConv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
代码
自己实现一个的版本,好像不太对,知识有限,希望大佬指出错误
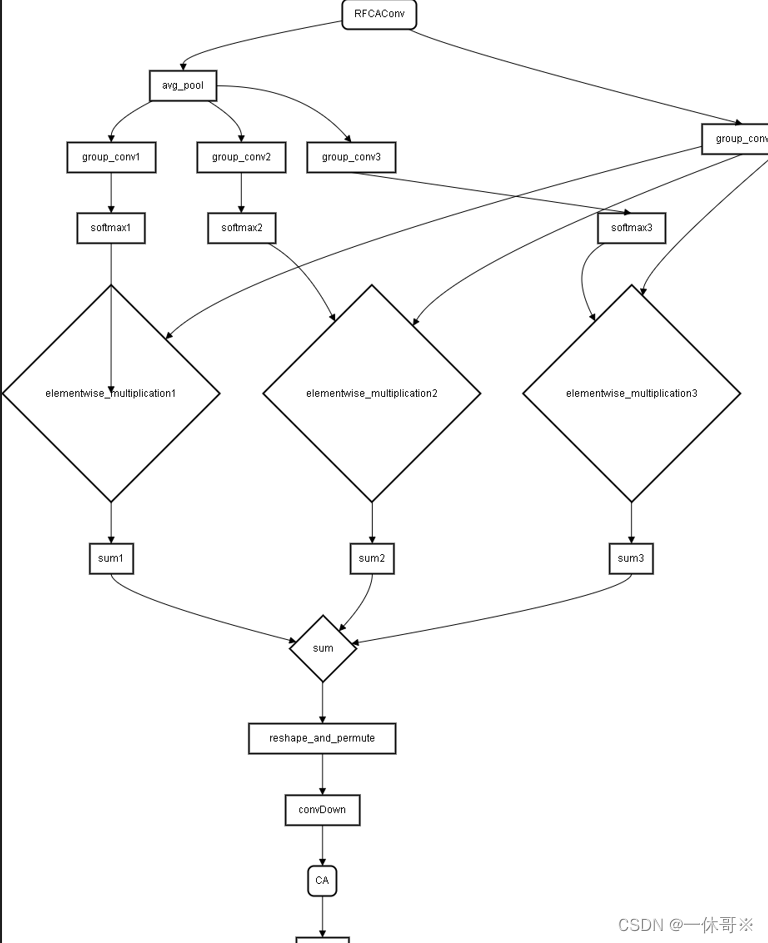
class RFCAConv(nn.Module):
def __init__(self, c1, c2, kernel_size, stride):
super(RFCAConv, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.group_conv1 = Conv_L(c1, 9 *c1, k=1, g=c1)
self.group_conv2 = Conv_L(c1, 9 *c1, k=3, g=c1)
self.group_conv3 = Conv_L(c1, 9 *c1, k=5, g=c1)
self.softmax = nn.Softmax(dim=1)
self.group_conv = Conv(c1, 9 * c1, k=3, g=c1)
self.convDown = Conv(c1, c1, k=3, s=3)
self.CA = CAConv(c1, c2, kernel_size, stride)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
group1 = self.softmax(self.group_conv1(y))
group2 = self.softmax(self.group_conv2(y))
group3 = self.softmax(self.group_conv3(y))
# g1 = torch.cat([group1, group2, group3], dim=1)
g2 = self.group_conv(x)
out1 = g2 * group1.expand_as(g2)
out2 = g2 * group2.expand_as(g2)
out3 = g2 * group3.expand_as(g2)
out = sum([out1, out2, out3])
# 获取输入特征图的形状
batch_size, channels, height, width = out.shape
# 计算输出特征图的通道数
output_channels = channels // 9
# 重塑并转置特征图以将通道数分成3x3个子通道并扩展高度和宽度
out = out.view(batch_size, output_channels, 3, 3, height, width).permute(0, 1, 4, 2, 5,3).\
reshape(batch_size, output_channels, 3 * height, 3 * width)
out = self.convDown(out)
out = self.CA(out)
return out
重新修改了以下,
class RFCAConv2(nn.Module):
def __init__(self, c1, c2, kernel_size, stride):
super(RFCAConv2, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.group_conv1 = Conv_L(c1, 3 *c1, k=1, g=c1)
self.group_conv2 = Conv_L(c1, 3 *c1, k=3, g=c1)
self.group_conv3 = Conv_L(c1, 3 *c1, k=5, g=c1)
self.softmax = nn.Softmax(dim=1)
self.group_conv = Conv(c1, 3 * c1, k=3, g=c1)
self.convDown = Conv(c1, c1, k=3, s=3,g=c1)
self.CA = CAConv(c1, c2, kernel_size, stride)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
group1 = self.softmax(self.group_conv1(y))
group2 = self.softmax(self.group_conv2(y))
group3 = self.softmax(self.group_conv3(y))
# g1 = torch.cat([group1, group2, group3], dim=1)
g1 = self.group_conv(x)
# g2 = self.group_conv(x)
# g3 = self.group_conv(x)
out1 = g1 * group1
out2 = g1 * group2
out3 = g1 * group3
out =torch.cat([out1, out2, out3],dim=1)
# 获取输入特征图的形状
batch_size, channels, height, width = out.shape
# 计算输出特征图的通道数
output_channels = c
# 重塑并转置特征图以将通道数分成3x3个子通道并扩展高度和宽度
out = out.view(batch_size, output_channels, 3, 3, height, width).permute(0, 1, 4, 2, 5, 3).\
reshape(batch_size, output_channels, 3 * height, 3 * width)
# out = out.view(batch_size, output_channels, height*3, width*3)
out = self.convDown(out)
out = self.CA(out)
return out
官方RFAconv代码
import torch
from torch import nn
from einops import rearrange
class RFAConv(nn.Module): # 基于Group Conv实现的RFAConv
def __init__(self,in_channel,out_channel,kernel_size,stride=1):
super().__init__()
self.kernel_size = kernel_size
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel,bias=False))
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size,padding=kernel_size//2,stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self,x):
b,c = x.shape[0:2]
weight = self.get_weight(x)
h,w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) #b c*kernel**2,h,w -> b c k**2 h w 获得感受野空间特征
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, # b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











