






文章介绍
Published in:
National Conference on Artificial Intelligence. AAAI Press, 2014
All Authors:
Zhen Wang∗, Jianwen Zhang, Jianlin Feng, Zheng Chen
Department of Information Science and Technology, Sun Y at-sen University, Guangzhou, China2Microsoft Research, Beijing, China
摘要
In terms of embedded relationship mapping, TransE does a poor job of handling one-to-many, many-to-one, and many-to-many relationships.
【 在嵌入的关系映射方面,TransE在处理一对多/多对一/多对多关系上效果不佳。】
TransH can directly balance model capacity and efficiency, and has the same model complexity as TransE.
【TransH、能够在模型容量和效率之间取得平衡、与TransE的模型复杂度同。】
Propose a simple trick to reduce the possibility of false negative labeling. Conduct extensive experiments on link prediction, triplet classification and fact extraction on bench-mark datasets like WordNet and Freebase.
【提出一个简单的方法来减少假阴性标签的可能性。我们在WordNet和Freebase等基准数据集上进行了大量的链接预测、三元组分类和事实提取实验。】
介绍
将知识图谱嵌入在连续的空间中。方法是将头尾实体表示为空间中的点(即是坐标原点到这个点的向量),关系边表示为两个点之间的映射属性,而每个关系r被建模为空间中的一个操作,其特征是一个向量r,如平移、投影等。通过最小化一个全局损失函数来训练这三个向量。
通常知识图谱表征中,实体被表示为一个 k 维度的向量 h 、t ,定义一个得分函数 f1(h,𝑡)f_1 (h,t) 表示三元组 (h,r,t)的嵌入空间。
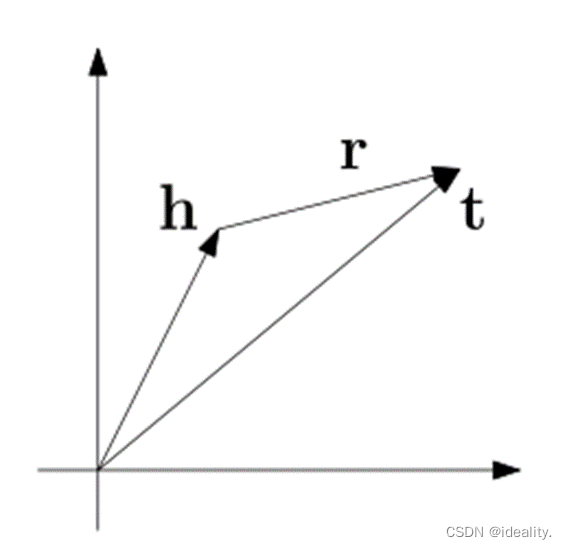
TransE不足
参考:https://www.bilibili.com/video/BV1zh411Z7nL/?spm_id_from=333.337.search-card.all.click
由于TransE在一对多,多对一,多对多关系时或自反关系上效果不是很好,所以TransH被提出。

比如我们看两组关系,(司马懿 小妾 柏灵筠),(司马懿 小妾 静姝)。因为两组关系中都存在实体“司马懿”和关系“小妾”,那么如果只简单考虑h+r=t,那么“柏灵筠”=“司马懿”+“小妾”和“静姝”=“司马懿”+“小妾”,所以“柏灵筠”=“静姝”,很显然,这并不是我们想要的结果。
再比如自反关系,(曹操 欣赏 曹操),“曹操”+“欣赏”=曹操,所以“欣赏”=0。如果你非要说如果存在自反关系,relation 就该为0,那么轮到计算(曹操 欣赏 司马懿)时,如果将“欣赏”=0代入,则会产生“曹操”=“司马懿”的结果。当然TransE在实际迭代中也不会这样,原因是因为(曹操 欣赏 司马懿)这类的数据大概率会在训练集中占大多数,而(曹操 欣赏 曹操)会被它当作噪音数据一样的存在, 所以会影响效果。
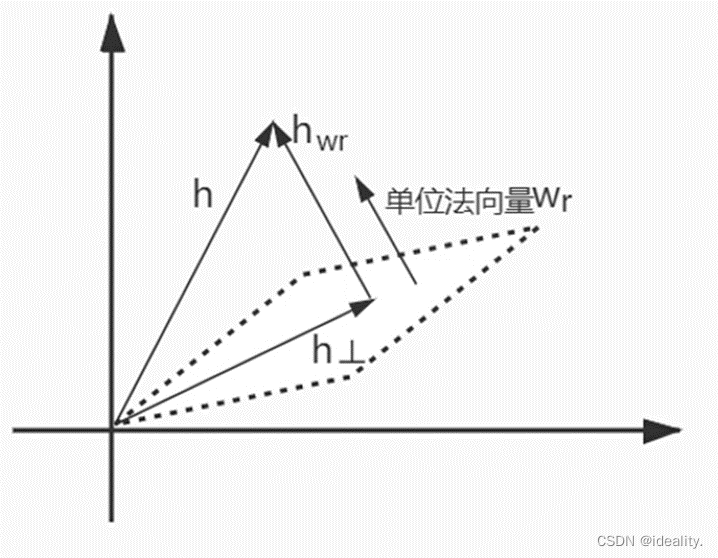
TransH
对每个关系定义一个超平面 Wr。而h⊥ 与𝑡⊥" 作为h和t在超平面上的投影,将 h⊥与𝑡⊥ 代替 h, t 满足:
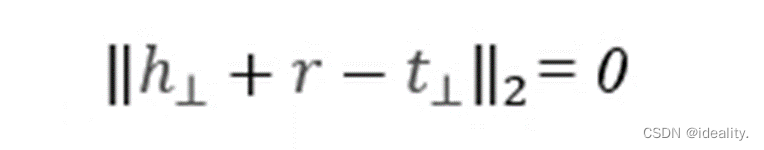
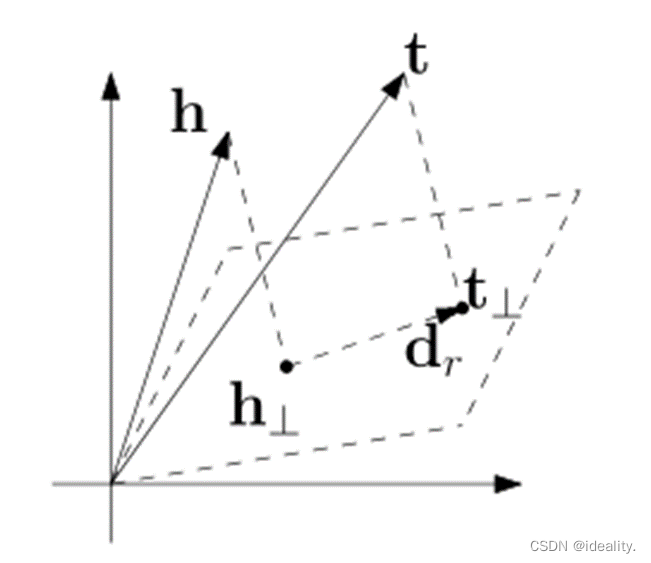
这么一来,像 (司马懿 小妾 柏灵筠),(司马懿 小妾 静姝) 在TransH中就不需要“柏灵筠”的向量等于“静姝”的向量了,仅仅需要他们在WrW_r上的投影相同既可以。
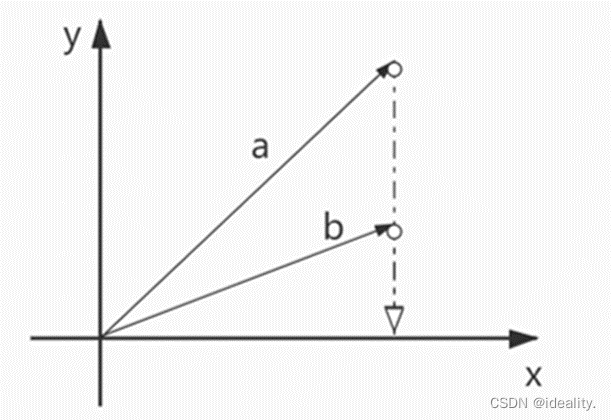
要知道投影相同不需要他们自身也要相同。
如下图所示,a向量与b向量在x轴上的投影虽相同,但a与b可以是两个不同的向量。
相关工作
以下模型都将实体嵌入到一个向量空间中,并在一个评分函数下强制嵌入兼容。不同模型对评分函数fr(h,𝑡)的定义不同,其中包含了h和t的一些变换。

TransH详解
首先我们定义一个wrw_r为WrW_r超平面的单位法向量,即|| w_r ||= 1。根据欧几里得点积公式
![]()



负采样方法
文章另一个创新点是提出了新的采样方法 bern。原始的负采样方法是从实体集中随机抽取一个实体替换到 golden triplet 中生成负样本,但是这样做有可能会得假阴(false negative)的负样本。 设置一定的概率用于代替头实体或尾实体。
当关系为一对多时,让头实体有更大的概率被替换;当关系为多对一时,让尾实体有更大的概率被替换。负采样机制:假设tph表示每个头实体对应的尾实体数量的平均值,hpt表示每个尾实体对应的头实体数量的平均值。给定的实体对 (h,r,t),然后以tph/(tph+hpt)概率替换头实体,以 hpt/(tph+hpt)概率替换尾实体。
tph/(tph+hpt)越大,说明是一对多的关系,在负采样时替换头实体,更容易获得 true negative。
实验
数据集
实验在两个数据集上分别完成,分别为WordNet和FreeBase。数据集情况如图所示: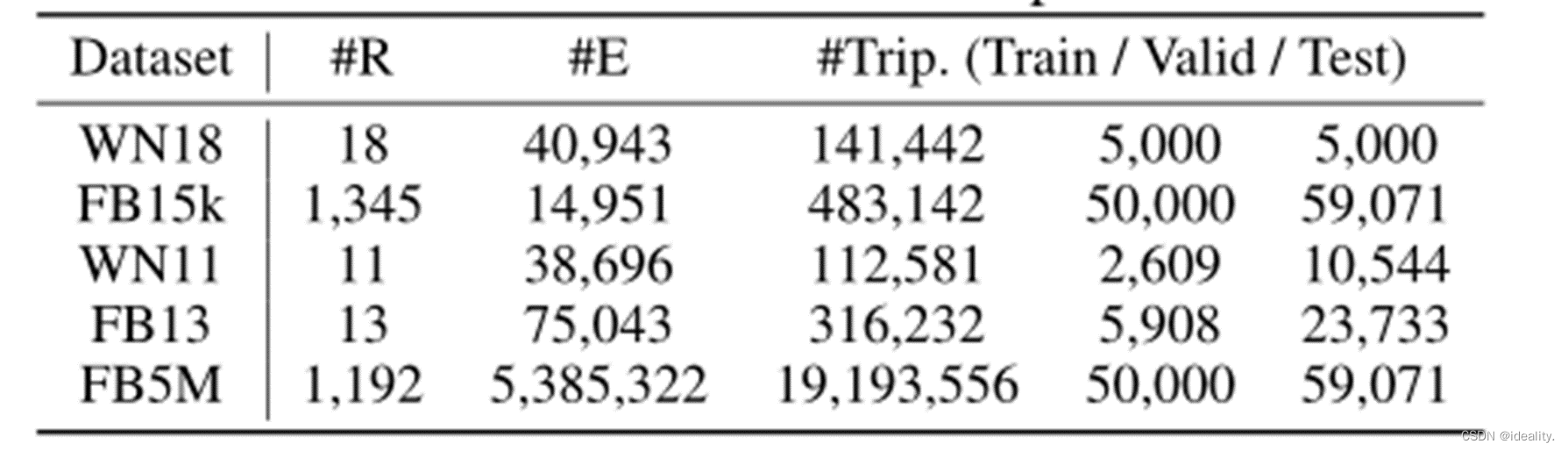
评价指标
Hits@N:表示有多少正确的三元组最终的排序是在 topN ,值越大越好,常看的是 Hits@10,Hits@3,Hits@1;
Mean Rank(MR): 所有正确三元组的排序位置的平均值,值越小越好。
Experiment-Link Prediction
这个任务是完成一个缺少h或t的三元组(h, r, t),即预测给定的t (h, r)或预测给定的h (r, t)。这个任务不是要求一个最佳答案,而是更强调从知识图中对一组候选实体进行排名。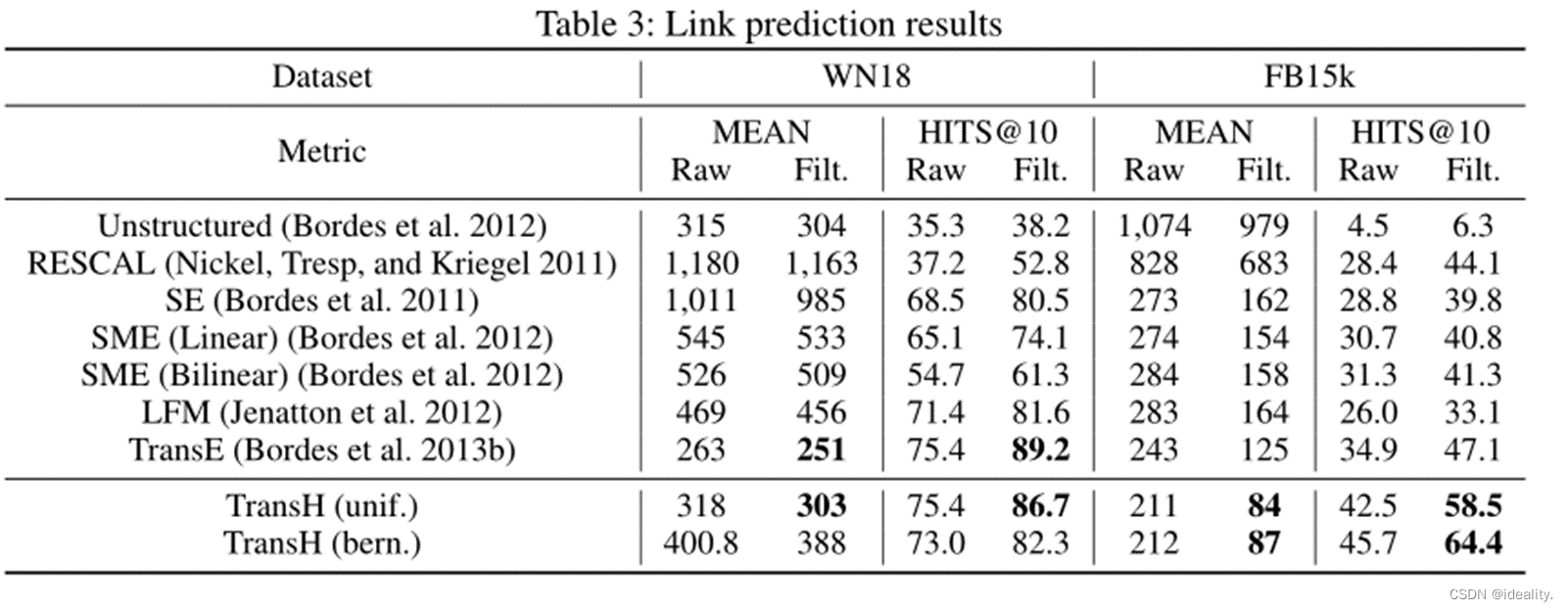
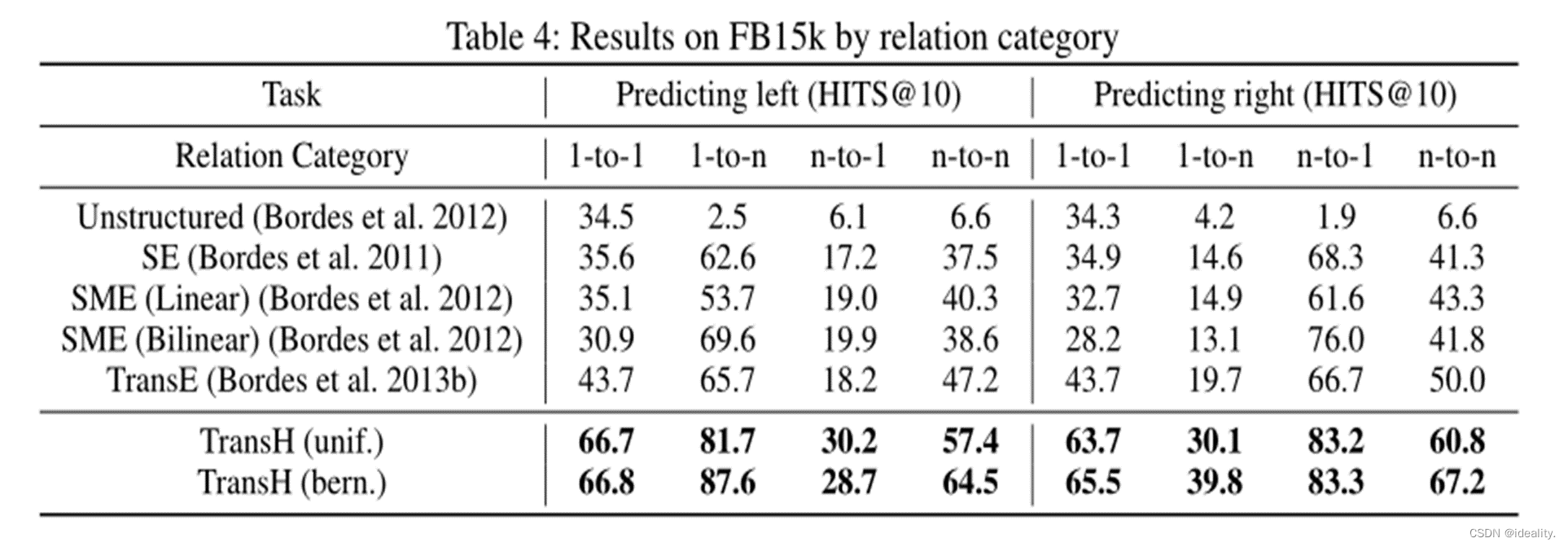
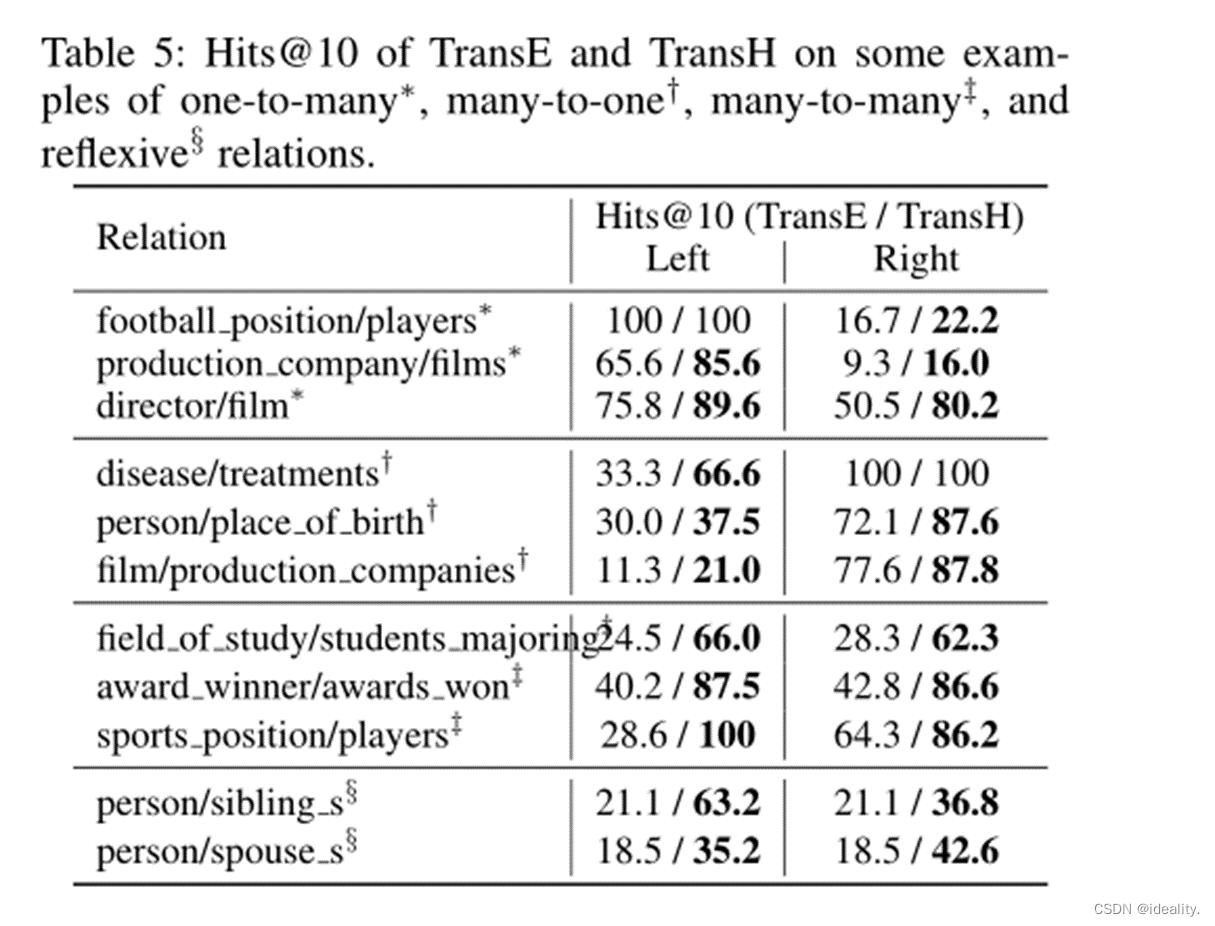
Experiment-Triplets Classification
这个任务是确认给定的三元组(h, r, t)是否正确,即对三元组进行二元分类。
分类的决策规则很简单:对于三元组(h, r, t),如果不相似度得分(由得分函数f𝑟)低于特定的关系阈值σ𝑟 ,则预测为正。否则预测为负。关系特定阈值σ𝑟是根据验证集上的分类精度(最大化)确定的。

Experiment-Relational Fact Extraction from Text
这一部分正是TransE在总结部分的未来展望,TransH将其实现这个任务的对比。关系抽取任务可以通过知识表示来完成,也属于一种知识补充。作者使用基于远程监督的关系抽取,评价指标则为P-R曲线与对应的AUC面积。实验细节省略,实验对比如图所示: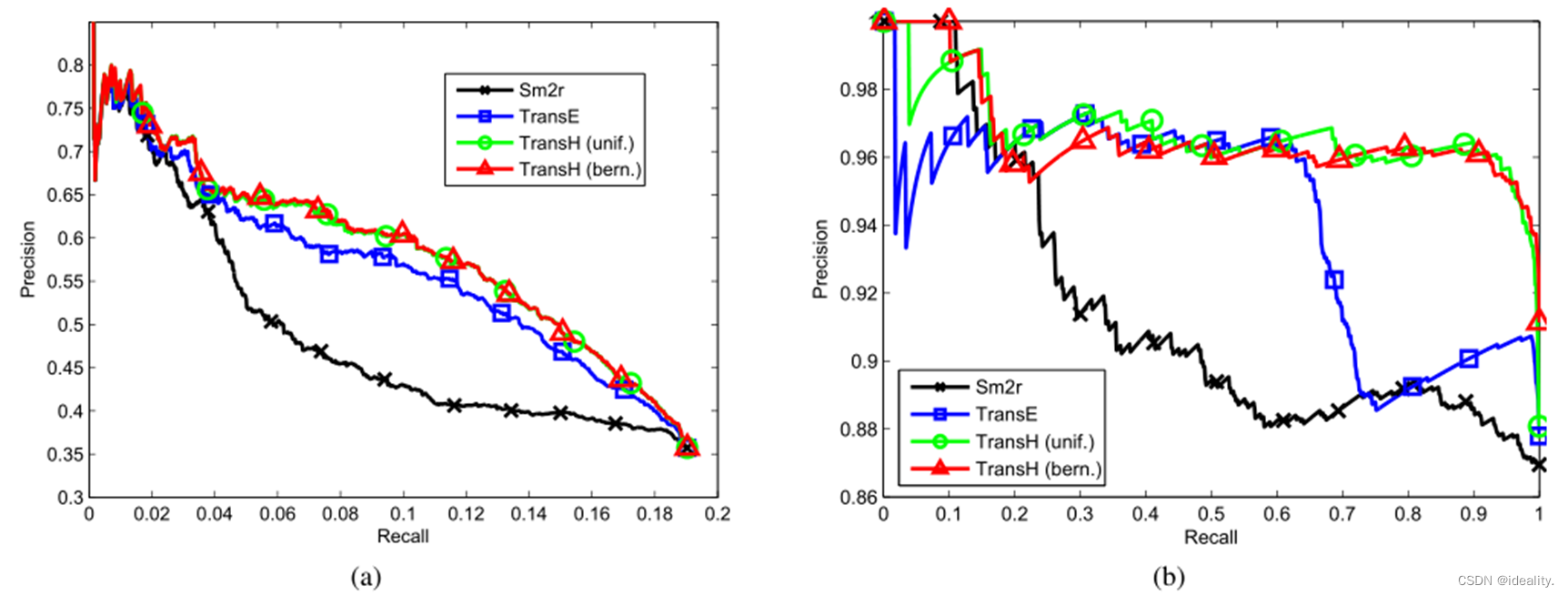
结论
这个模型TransH主要解决了TransE不能够很有效的进行复杂关系的建模,并提出一种关系映射方法解决了这个问题,在包括链接预测、三元组分类和关系抽取任务上表现最好,另外作者改进了负采样的策略,提出一种概率采样的办法,降低错误标签带来的问题。
当然TransH也存在一定的问题:头尾实体依然处于相同的语义空间,而每个三元组的关系可能关注头尾实体的不同属性,即每个关系对应的头尾实体应在不同的语义空间中表征,因此TransR模型由此诞生。















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









