







回顾
折扣回报
动作价值函数
状态价值函数

最优动作价值函数
最优状态价值函数

优势函数
定义

表示动作a相对于baseline
V
∗
V^*
V∗的优势,动作越好,优势越大
性质
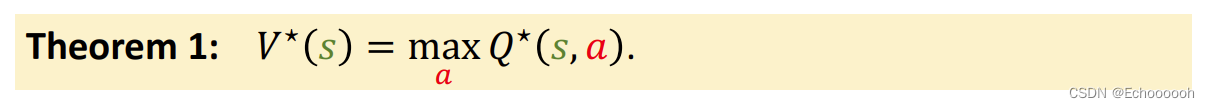
在定义式两边关于a做最大化,式子依然成立,又带入性质1得到
m
a
x
A
∗
(
s
,
a
)
=
0
maxA^*(s,a)=0
maxA∗(s,a)=0
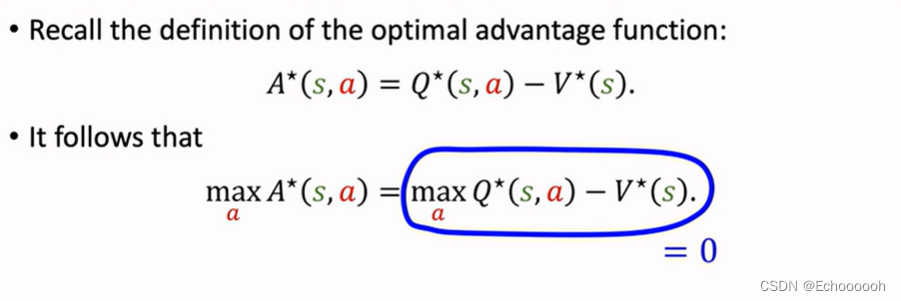
再由定义式出发,移项得

带入刚刚推导的
m
a
x
A
∗
(
s
,
a
)
=
0
maxA^*(s,a)=0
maxA∗(s,a)=0,得到性质2

Dueling Network
回顾DQN
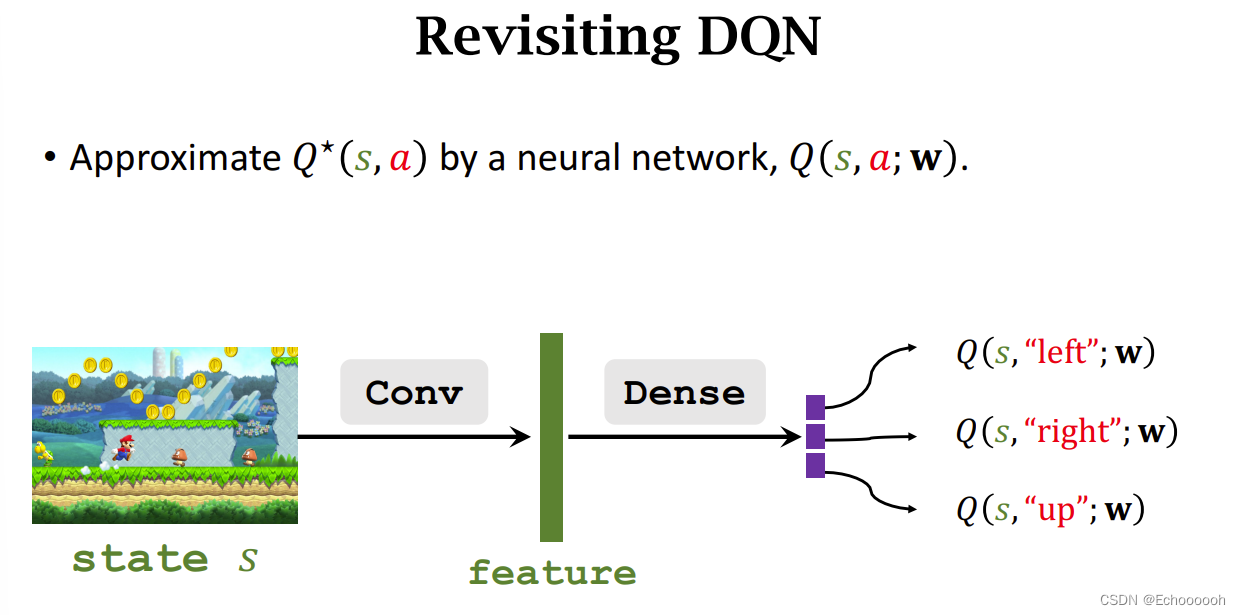
DQN用神经网络对
Q
∗
Q^*
Q∗做近似,这里我们不对
Q
∗
Q^*
Q∗做近似,我们对
A
∗
A^*
A∗做近似,网络结构不变
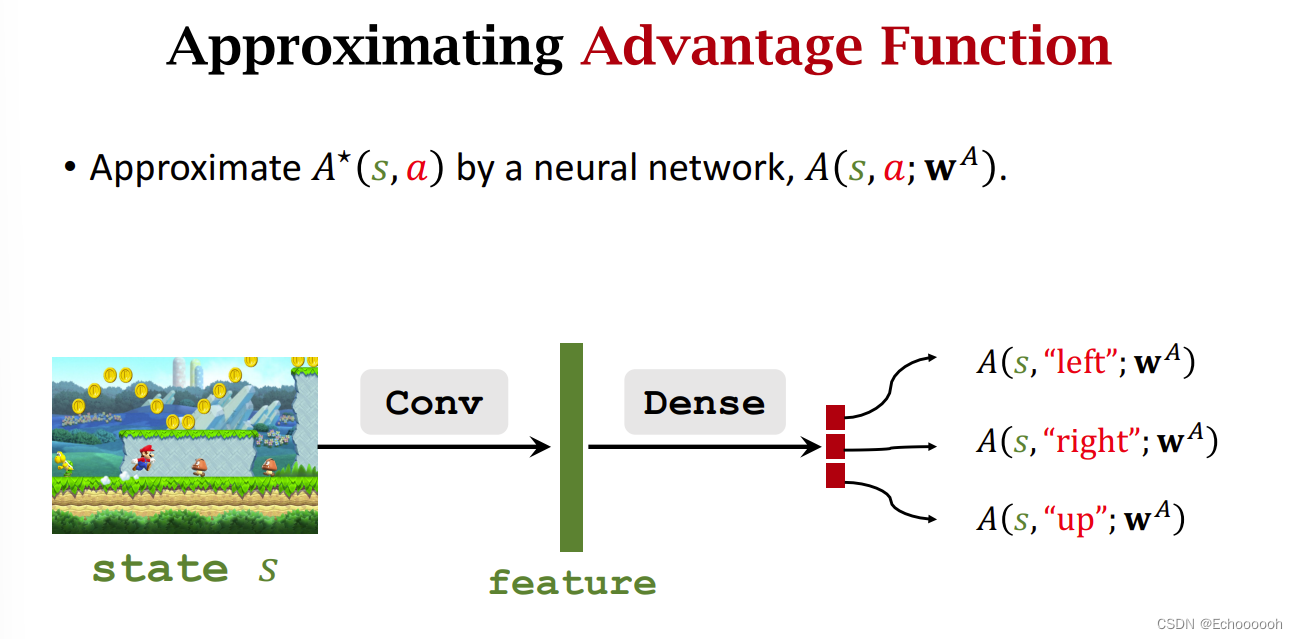
再用一个网络近似
V
∗
V^*
V∗,其输出式一个实数,可以和
A
∗
A^*
A∗的网络共享卷积层。
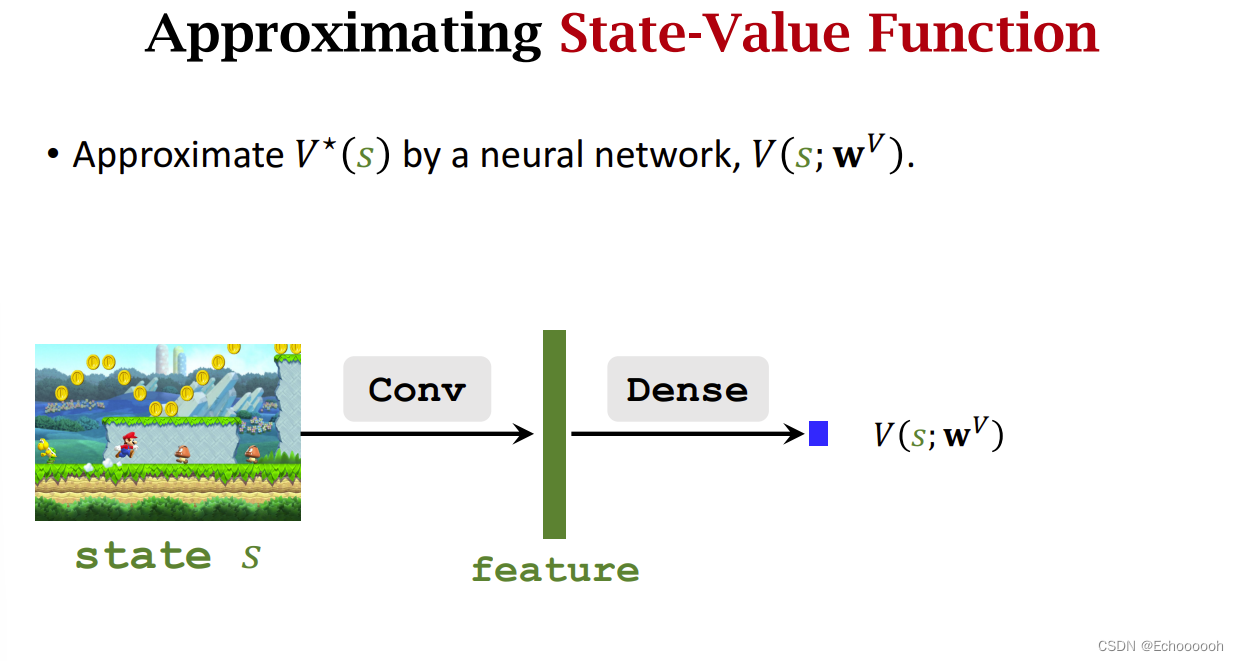
此时搭建Dueling Network
它跟DQN作用相同,表示相同,都是最优动作价值函数的近似
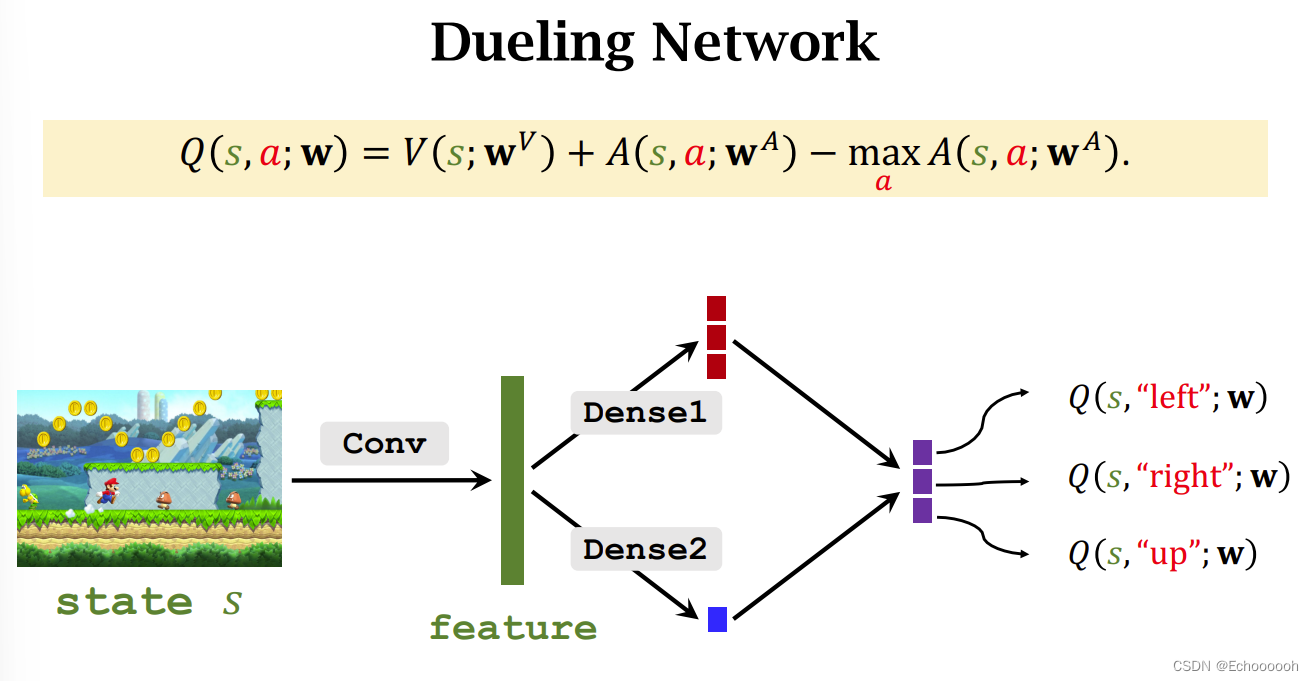
训练过程也和DQN完全一样,都是TD算法。
为什么要加 m a x A maxA maxA这一项
为了解决不唯一性的问题

等式1存在不唯一性的问题:若两个网络都有波动,但波动恰好抵消,则输出无影响。

但添加最大化项可以解决这个问题
将最大化项换为平均项,效果会更好(经验结论)
















 3825
3825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









