






作者认为估计每个action的价值是没有必要的,例如在Enduro游戏中,仅仅当碰撞要发生时,判断左转还是右转才是有效的。在一些状态下,知道该做什么action是首要重要的,但是在一些其他状态下,action的选择对于产生的结果是没有影响的。然而state value的估计对于每个状态是至关重要的。作者说这个方法在存在多个相似的action时效果很好。

所以作者重新定义了Q值:
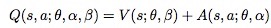
V表示state value,A表示(state-dependent)action advantages。
但是作者又认为这个公式是没有鉴别性的,因为被给Q值,无法分别估计出V和A。
(但是这样又会怎么样呢?这块不太懂。。。)所以作者首先想的是给A减去一个常量:
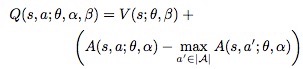
让A-max(A)趋近于0,这样就可以得到Q=V。
之后又有一种变化:
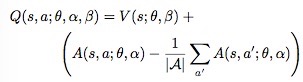
作者认为这样损失了V和A原始的语义信息(减去最大值的方法没有损失吗?)增加了模型的稳定性,同时也没有改变V和A的本质表示。(但是这样就能从Q恢复到V和A了嘛?)















 3825
3825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









